一种数据采样方法及相关设备与流程
本技术涉及数据处理,尤其涉及一种数据采样方法、系统、计算设备集群、计算机可读存储介质、计算机程序产品。
背景技术:
1、随着互联网的产生,尤其是移动互联网的产生,数据呈现爆炸性增长趋势。对海量的数据进行挖掘、分析成为研究的热点。为了对数据进行挖掘、分析等后续的处理,通常需要进行数据准备工作。
2、数据准备是指将原始数据预处理为适合于后续处理(如挖掘、分析)的数据的过程。数据预览是数据准备重要的功能特性之一。数据预览为用户提供了一个快速了解数据分布的工具。用户可以通过预览数据来选择下一步的数据处理或分析操作。例如,用户通过预览数据,发现重复数据条目比较多,可以提交一个对该数据集进行数据去重的任务。
3、典型的数据预览流程是对包括原始数据的数据集进行随机采样获得样本数据,或者是选取前n行作为样本数据,然后展示样本数据。然而,上述方法选取的样本数据的代表性不足,尤其是在对小样本场景中,随机采样或者是选取前n行得到的样本数据很难表征整体的数据分布,难以为后续的数据处理提供帮助。
技术实现思路
1、本技术提供了一种数据采样方法,该方法能够获取接近全局数据分布的样本数据,从而大幅提升样本数据的代表性。本技术还提供了该方法对应的数据采样系统、计算设备集群、计算机可读存储介质以及计算机程序产品。
2、第一方面,本技术提供了一种数据采样方法。该方法可以由数据采样系统执行。数据采样系统可以是软件系统,该软件系统部署在计算设备集群中。计算设备集群执行数据采样系统的程序代码,从而执行本技术的数据采样方法。在一些可能的实现方式中,数据采样系统也可以是硬件系统,例如是具有数据采样功能的计算设备集群。
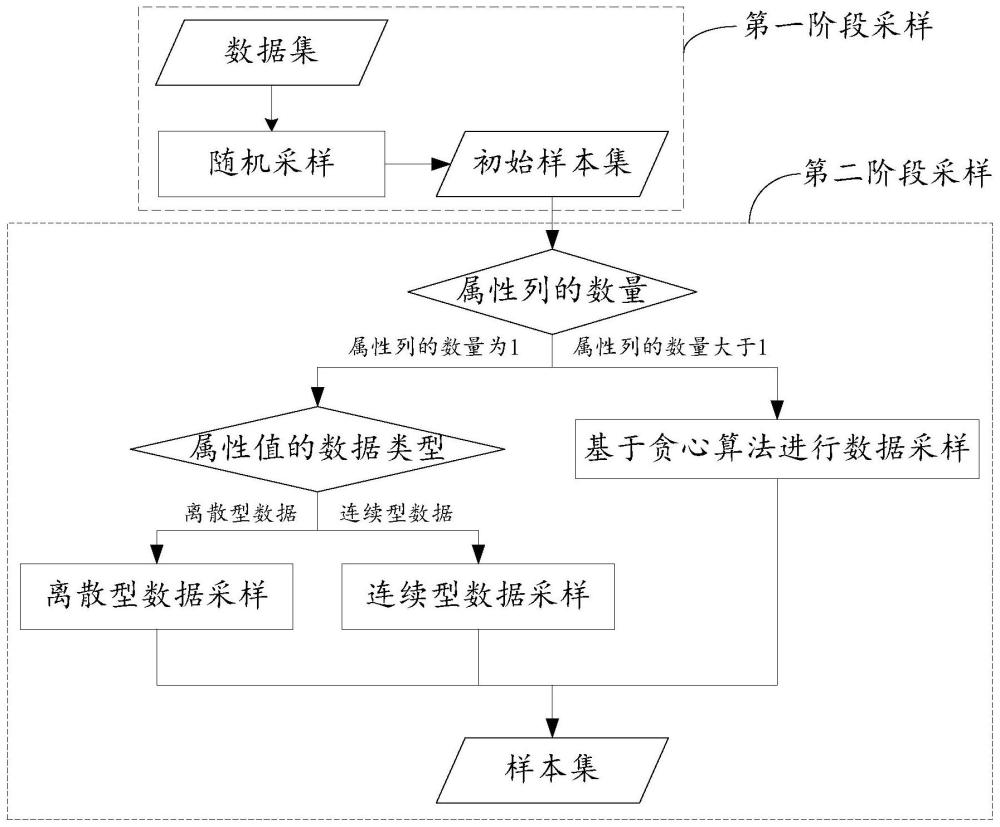
3、具体地,数据采样系统可以获取数据集,然后确定该数据集中属性列的数量和属性值的数据类型,接着,数据采样系统可以根据该数据集中属性列的数量和属性值的数据类型,从该数据集中采样获得样本集。
4、该方法基于大量原始数据中属性列的数量和属性值的数据类型进行数据采样,从而获取接近全局数据分布的样本数据,能够提升样本数据的代表性,同时使得样本数据更加适用于数据预览场景,便于用户根据样本数据进行后续的数据处理。
5、在一些可能的实现方式中,数据采样系统还可以向用户呈现样本集,或者根据样本集,通过人工智能ai算法进行数据分析。
6、通过该方法采样获得的样本集可以用于数据预览或数据处理等多个场景,用户可以通过数据预览了解数据集的数据分布情况,或者通过样本集确定对数据集的后续处理操作。
7、在一些可能的实现方式中,属性列的数量为1,属性值的数据类型为离散型时,数据采样系统可以根据数据集中属性列对应的多种属性值在数据集中出现的比例,采样获得样本集。
8、针对单属性列的离散型数据,该方法可以根据属性值出现的比例进行数据采样,提升样本数据的代表性。
9、在一些可能的实现方式中,数据集中包括n行数据,样本集包括m行数据,样本集为数据集的子集,数据采样系统可以获取多种属性值中第i种属性值在数据集中出现的第一次数,接着根据数据集和样本集的大小之比与数据第一次数的乘积,确定第i种属性值在样本集中出现的次数。
10、针对单属性列的离散型数据,该方法采样获得的样本集能够表示数据集中多种属性值的分布情况,从而便于用户了解数据集中的全局数据分布。
11、在一些可能的实现方式中,该乘积为整数时,数据采样系统可以确定第i种属性值在样本集中出现的次数为该整数。该乘积非整数时,数据采样系统可以根据样本集与数据集在该乘积向上取整和向下取整后的距离差,将该乘积向上取整或向下取整后的整数确定为第i种属性值在样本集中出现的次数。
12、针对单属性列的离散型数据,当出现属性值在样本集中出现的次数为非整数时,该方法通过借鉴kl散度的思想,对向上取整和向下取整后的样本集的距离进行评估,从而确定样本集中属性值出现的次数,如此,能够减小样本集中数据分布情况与初始样本集中数据分布情况的不同程度。
13、在一些可能的实现方式中,属性列的数量为1,属性值的数据类型为连续型时,数据采样系统可以将属性列对应的多个属性值排序,接着从排序后的序列中,按照目标间隔选取数据获得样本集。
14、针对单属性列的连续型数据,该方法以目标间隔在属性值排序后的序列中选取样本集,从而使得样本集能够反映数据集中的数据分布情况,保证样本集中数据具有代表性。
15、在一些可能的实现方式中,属性列的数量大于1时,数据采样系统可以根据多个属性列中各个属性列对应的属性值的数据类型,选取各个属性列的第一列样本集合,接着从数据集中选取m行数据,获得初始行样本数据。其中,初始行样本数据中各个属性列对应的属性值形成各个属性列的第二列样本集合。针对m行数据之外的目标行数据,数据采样系统可以确定目标行替换初始行样本数据中的一行数据时至少一个属性列的第一列样本集合与第二列样本集合的距离,并根据该距离,确定是否执行对初始行样本数据的替换操作,获得样本集。
16、针对多属性列的数据,该方法基于贪心算法进行数据采样,通过目标行替换初始行样本数据,使得采样得到的样本集的数据分布情况更接近数据集中的数据分布情况,如此,提升样本数据的代表性。
17、在一些可能的实现方式中,当至少一个属性列的第一列样本集合与第二列样本集合的距离之和大于替换前各个属性列的第一列样本集合与第二列样本集合的距离之和,数据采样系统可以拒绝执行目标行替换初始行样本数据中的一行数据的操作。
18、针对多属性列的数据,该方法在进行替换操作后的样本集无法更好地反映初始样本集中的数据分布情况时,不进行替换操作,从而保证样本数据能够更好地反映出数据集中的数据分布情况。
19、在一些可能的实现方式中,至少一个属性列包括第i列,第i列对应的属性值为离散型时,数据采样系统可以确定第i列的各种属性值在第i列的第一列样本集合和替换后的第二列样本集合中出现次数的差值,接着根据该差值的绝对值之和,确定目标行替换初始行样本数据中的一行数据时至少一个属性列的第一列样本集合与第二列样本集合的距离。
20、针对多属性列中的离散型数据,该方法通过借鉴ks统计量的思想,基于替换前后属性值出现次数的差值确定距离,以判断是否执行替换操作,从而采样获得样本集,能够提升样本数据的代表性。
21、在一些可能的实现方式中,至少一个属性列包括第i列,第i列对应的属性值为连续型时,数据采样系统可以将第i列的第一列样本集合和替换后的第二列样本集合按照相同方式排序,并确定排序后的第一列样本集合中元素与排序后的第二列样本集合中相应的元素的差值,接着,数据采样系统可以根据该差值的绝对值之和,确定目标行替换初始行样本数据中的一行数据时至少一个属性列的第一列样本集合与第二列样本集合的距离。
22、针对多属性列中的连续型数据,该方法通过借鉴ks统计量的思想,基于替换前后元素的差值确定距离,以判断是否执行替换操作,从而采样获得样本集,能够提升样本数据的代表性。
23、在一些可能的实现方式中,数据采样系统可以对数据集进行两阶段采样。其中,第一阶段采样可以采用随机采样,第二阶段采样可以根据数据集中属性列的属相和属性值的数据类型进行采样。如此,可以有效降低原始数据集的数据规模,使得计算资源有限的设备也可以对数据集进行后续第二阶段采样,从而在大数据场景下实现数据预览的功能。
24、在一些可能的实现方式中,该方法可以用于数据准备,使得用户可以基于样本集确定对数据集的处理操作,由于样本集接近数据集中全局数据分布,该方法可以提升用户数据准备效率。
25、在一些可能的实现方式中,该方法可以用于机器学习训练数据的选取,由于用户可以通过样本集了解数据集中的数据分布情况,该方法可以使得用户选取具有代表性的数据进行数据标注。
26、第二方面,本技术提供了一种数据采样系统。所述系统包括:
27、获取模块,用于获取数据集;
28、确定模块,用于确定所述数据集中属性列的数量和属性值的数据类型;
29、采样模块,用于根据所述属性列的数量以及所述属性值的数据类型,从所述数据集中采样获得样本集。
30、在一些可能的实现方式中,所述系统还包括:
31、交互模块,用于向用户呈现所述样本集;或者,
32、数据分析模块,用于根据所述样本集,通过人工智能ai算法进行数据分析。
33、在一些可能的实现方式中,所述采样模块具体用于:
34、所述属性列的数量为1,所述属性值的数据类型为离散型时,根据所述数据集中所述属性列对应的多种属性值在所述数据集中出现的比例,采样获得样本集。
35、在一些可能的实现方式中,所述数据集中包括n行数据,所述样本集包括m行数据,所述样本集为所述数据集的子集,所述采样模块具体用于:
36、获取所述多种属性值中第i种属性值在所述数据集中出现的第一次数;
37、根据所述数据集和所述样本集的大小之比与所述数据第一次数的乘积,确定所述第i种属性值在所述样本集中出现的次数。
38、在一些可能的实现方式中,所述采样模块具体用于:
39、所述乘积为整数时,确定所述第i种属性值在所述样本集中出现的次数为所述整数;
40、所述乘积非整数时,根据所述样本集与所述数据集在所述乘积向上取整和向下取整后的距离差,将所述乘积向上取整或向下取整后的整数确定为所述第i种属性值在所述样本集中出现的次数。
41、在一些可能的实现方式中,所述采样模块具体用于:
42、所述属性列的数量为1,所述属性值的数据类型为连续型时,将所述属性列对应的多个属性值排序;
43、从排序后的序列中,按照目标间隔选取数据获得样本集。
44、在一些可能的实现方式中,所述采样模块具体用于:
45、所述属性列的数量大于1时,根据多个属性列中各个属性列对应的属性值的数据类型,选取各个属性列的第一列样本集合;
46、从所述数据集中选取m行数据,获得初始行样本数据,所述初始行样本数据中各个属性列对应的属性值形成各个属性列的第二列样本集合;
47、针对所述m行数据之外的目标行数据,确定所述目标行替换所述初始行样本数据中的一行数据时至少一个属性列的第一列样本集合与第二列样本集合的距离;
48、根据所述距离,确定是否执行对所述初始行样本数据的替换操作,获得样本集。
49、在一些可能的实现方式中,所述采样模块具体用于:
50、当所述至少一个属性列的第一列样本集合与第二列样本集合的距离之和大于替换前各个属性列的第一列样本集合与第二列样本集合的距离之和,拒绝执行所述目标行替换所述初始行样本数据中的一行数据的操作。
51、在一些可能的实现方式中,所述采样模块具体用于:
52、所述至少一个属性列包括第i列,所述第i列对应的属性值为离散型时,确定所述第i列的各种属性值在所述第i列的第一列样本集合和替换后的第二列样本集合中出现次数的差值;
53、根据所述差值的绝对值之和,确定所述目标行替换所述初始行样本数据中的一行数据时至少一个属性列的第一列样本集合与第二列样本集合的距离。
54、在一些可能的实现方式中,所述采样模块具体用于:
55、所述至少一个属性列包括第i列,所述第i列对应的属性值为连续型时,将所述第i列的第一列样本集合和替换后的第二列样本集合按照相同方式排序;
56、确定排序后的第一列样本集合中元素与排序后的第二列样本集合中相应的元素的差值;
57、根据所述差值的绝对值之和,确定所述目标行替换所述初始行样本数据中的一行数据时至少一个属性列的第一列样本集合与第二列样本集合的距离。
58、第三方面,本技术提供了一种计算设备集群。所述计算设备集群包括至少一台计算设备,所述至少一台计算设备包括至少一个处理器和至少一个存储器。所述至少一个处理器、所述至少一个存储器进行相互的通信。所述至少一个处理器用于执行所述至少一个存储器中存储的指令,以使得计算设备或计算设备集群执行如第一方面或第一方面的任一种实现方式所述的数据采样方法。
59、第四方面,本技术提供了一种计算机可读存储介质,所述计算机可读存储介质中存储有指令,所述指令指示计算设备或计算设备集群执行上述第一方面或第一方面的任一种实现方式所述的数据采样方法。
60、第五方面,本技术提供了一种包含指令的计算机程序产品,当其在计算设备或计算设备集群上运行时,使得计算设备或计算设备集群执行上述第一方面或第一方面的任一种实现方式所述的数据采样方法。
61、本技术在上述各方面提供的实现方式的基础上,还可以进行进一步组合以提供更多实现方式。
- 还没有人留言评论。精彩留言会获得点赞!