基于类别加权网络的眼底照片分类方法与装置
1.本发明属于图片分类及眼科医学技术领域,具体涉及一种基于类别加权网络的眼底照片分类方法与装置。
背景技术:
2.视觉是人们认识世界,获取知识最主要的信息接受器,然而随着社会的发展,人们在工作和生活上的用眼压力日渐增加,此外,不少常见的疾病也会间接对眼部组织造成损害,眼健康成为人们不可忽视的挑战。能够引发眼部并发症的最常见的一种疾病,便是糖尿病(diabetes mellitus, dm),他是我们这个时代最严重和最常见的慢性疾病之一。根据国际糖尿病联合会(international diabetes federation, idf)最新的统计数据显示,2021 年全球 20-79 岁人群的糖尿病患病率估计为10.5%(5.366 亿人),到2045 年将上升至12.2%(7.832 亿人)。由糖尿病引发的眼部并发症被称为糖尿病视网膜病变(diabetic retinopathy, dr),他是造成成年人失明的主要原因,其主要的病灶包括微动脉瘤(mas)、“点状”或“斑点状”出血(hes)、硬性渗出(ex)、棉絮斑(cws)和新生血管(nv)等。而中国糖尿病患者中dr患病率为18.45%,也就是说几乎每5个糖尿病人中,就有一个面临失明的风险。中国乃至世界的防盲治盲工作都十分严峻。
3.基于机器学习和人工智能的计算机辅助诊断技术发展至今,已经有大量的研究人员投入到了相关的工作中,涉及的医疗领域也多种多样,能够帮助医生更加精确、高效地诊断病人的病情。这一技术在dr筛查领域的发展就是其中一个重要的方向。例如、(1)糖网病变程度的分级研究;(2)糖网病灶及有关结构的分割研究;(3)糖网病变判断可解释性研究等。加快机器学习技术深入应用到眼科,有可能彻底改变现有的疾病诊断系统,计算机辅助诊断技术将有效缓解眼科医生的工作压力,提高临床工作的效率,也有助于大规模人口疾病的筛查,为缓解医疗资源短缺提供新的解决途径。
4.然而在根据眼底视网膜图像来对患病程度进行分类判断的过程中,仍然存在着诸多问题:首先,由于dr数据集有其医学属性的特殊性,我们在数据集的数量和质量上都面临着较大的考验。传统的深度学习算法通常需要大量的数据支撑,但是网络上公开的dr数据集如ddr, aptos和messidor-2,都远远达不到足够的规模。同时,不同数据集还存在着分级标准不一致,不统一的问题,较为细致的糖网的分级通常分为五级,分别是正常、轻度,中度、重度和增殖性糖网。即使在相同的标准下,不同组织不同专业水平的医生也会对病情分类的结果做出不同的判断,所以我们无法将不同数据集合并起来使用。在单个数据集中,眼底图片的来源也五花八门,颜色、清晰度、对比度、亮度、尺寸、眼球完整度等各不相同,质量层次不齐。第二,dr数据集存在严重的数据失衡现象,包括数量上的不平衡以及难易程度上的不平衡。通常正常眼底的数量会占到总数据量的一半左右,甚至更高,而占比最少的数据可能只有其1/20~1/30。这种不平衡会导致机器学习模型在训练的过程中忽略对少数类别的特征学习,而更加关注多数类别的样本,最终导致模型效果较差,准确率虚高的问题。dr数据集中,还会遇到某类数据在数量少的同时,还难以被区分,如dr1和dr3,而dr4虽然数量
较少,但是比较容易被区分。
5.基于上述dr数据集存在的问题,导致机器学习在dr分类任务中仍不够准确,其存在较大的改进空间。因此,本发明提出了一种基于类别加权网络的眼底照片分类方法与装置,以用于辅助筛查糖网病,提高dr分类准确率。
技术实现要素:
6.本发明旨在至少解决现有技术中存在的技术问题之一,提供一种基于类别加权网络的眼底照片分类方法与一种基于类别加权网络的眼底照片分类装置。
7.本发明的一方面,提供一种基于类别加权网络的眼底照片分类方法,所述方法包括下述步骤:读取多个眼底照片数据及其标签;将所述眼底照片数据及其标签输入类别加权网络,训练并构建类别加权网络模型,包括:对所述眼底照片数据进行初步特征提取,得到初步提取特征图;对所述初步提取特征图分别以通道维度、像素维度、类别维度进行特征提取,分别得到通道特征图,像素特征图和类别特征图;将所述通道特征图,所述像素特征图和所述类别特征图进行融合,得到目标特征图;将所述目标特征图转化为与所述眼底照片标签对应的类别识别结果;读取待识别的眼底照片数据;将所述待识别的眼底照片数据输入所述类别加权网络模型,将所述模型输出概率最大的类别作为所述眼底照片的类别结果。
8.可选的,所述对所述眼底照片数据进行初步特征提取,得到初步提取特征图,包括:使用改造的预训练网络对所述眼底照片进行初步的特征提取,得到所述初步提取特征图;其中,所述改造的预训练网络不包括预训练网络最后的全连接层。
9.可选的,所述对所述初步提取特征图以通道维度进行特征提取,得到通道特征图,包括:使用像素维度的全局平均池化,以得到忽略像素维度的特征,经过conv_block得到通道权重分布,其中,conv_block的结构的具体关系式如下:其中,cb表示conv_block层,x表示输入conv_block层的特征图,conv表示1*1的卷积层,作为过渡层,其输出通道数与输入数据x的通道数相同,bn表示batch normalization,relu和sigmoid分别表示relu激活函数和sigmoid激活函数,他们为网络引入非线性因素;采用通道特征提取器对初步特征图以通道维度进行特征提取,得到通道特征图,
其中,所述通道特征提取器的结构的具体关系式如下:其中,fc表示通道特征图;fb表示初步提取特征图;gap
p
表示在像素维度做全局平均池化;cb表示conv_block层;表示矩阵点乘,经过cb层后得到的通道权重分布与初步提取特征图fb相点乘。
10.可选的,所述对所述初步提取特征图以像素维度进行特征提取,得到像素特征图,包括:使用通道维度的全局平均池化,以得到忽略通道维度的特征,经过conv_block得到像素权重分布;采用像素特征提取器对初步特征图以像素维度进行特征提取,得到像素特征图,其中,所述像素特征提取器的结构的具体关系式如下:其中,f
p
表示像素特征图;gapc表示通道维度的全局平均池化;fb表示初步提取特征图;cb表示conv_block层;表示矩阵点乘,经过cb层后得到的通道权重分布与初步提取特征图fb相点乘。
11.可选的,所述对所述初步提取特征图以类别维度进行特征提取,得到类别特征图,包括:采用1*1的卷积层,将初步提取特征图fb的通道扩充为k层,得到fk,k的具体关系式如下:其中,n表示图片的类型数,ki表示第i类分配的通道数,k为所有类型的通道总数;对具有k个通道的特征图fk按类型通道池化,以得到忽略通道维度特征的特征图fk,所述忽略通道维度特征的特征图fn共有n层通道,每层通道指示一个类型的特征,具体关系式如下:其中,fb表示初步提取特征图,convk表示k个1*1的卷积层,gmpk表示对每层通道执行一次最大池化;对fn在像素维度做全局平均池化,以得到忽略像素维度的特征图,经过conv_block得到类型权重分布,再与fn点乘,以得到初步的类型特征图;具体关系式如下:对执行通道维度的全局平均池化和conv_block得到最终的类型权重分布,具体关系式如下:其中,f
t
为类型特征图,gapc表示在通道维度做全局平均池化,cb表示conv_block层,表示矩阵点乘,经过cb层后得到的通道权重分布与初步提取特征图fb相点乘。
12.可选的,所述类型权重采用计算类型梯度范数的方式得到,具体关系式如下:其中,gi表示第i类的类型梯度范数,ni表示第i类的样本数,l
t
表示样本t经过模型后产生的cross entropy loss,out
t
表示i类的样本t经过模型计算后的直接输出;令p=softmax(out),y表示样本的one-hot向量表示,对类型梯度范数的计算进行简化,具体关系式如下:根据不同类型梯度范数gi的大小比例,以得到所述类型权重的大小比例。
13.可选的,所述将所述通道特征图,所述像素特征图和所述类别特征图进行融合,得到目标特征图,并将所述目标特征图转化为与所述眼底照片标签对应的类型识别结果,包括:将所述目标特征图经过全局平均池化层和全连接层得到最终的输出;具体关系式如下:其中,out为模型最终的输出值,为一个batch*n维的向量,向量元素的值代表了对应位置模型识别类型的可能性,选取最大值的位置下标,作为模型最终的类型识别结果;表示对不同矩阵间对应位置的元素求平均值,fch和fcn表示全连接层,fch的输出通道数为输入通道数的一半,fcn的输出通道数为分类数n。
14.可选的,所述读取多个眼底照片数据及其标签之前,还包括:对所述眼底照片进行随机上下翻转、随机左右翻转和随机旋转处理中至少一者的增强处理,以得到增强后的眼底照片。
15.可选的,所述将所述眼底照片数据及其标签输入类别加权网络,训练并构建类别加权网络模型之后,还包括:对所述眼底照片的类型识别结果与其真实标签进行比较计算交叉熵损失,并反向传播更新所述模型参数;所述交叉熵损失的具体关系式如下:其中,x[class]代表输入数据x实际所属类别,x[j]代表模型对于输入数据x所属类别j的识别结果。
[0016]
本发明的另一方面,提供一种基于类别加权网络的眼底照片分类装置,包括:第一读取单元、第二读取单元、模型形成单元、类别输出单元;其中,
所述第一读取单元,用于读取多个眼底照片数据及其标签;所述模型形成单元,用于将所述眼底照片数据及其标签输入类别加权网络,训练并构建类别加权网络模型;其中,所述模型形成单元还包括:基本特征提取器、通道特征提取器、像素特征提取器、类别特征提取器以及特征转化器;所述基本特征提取器,用于对所述眼底照片数据进行初步特征提取,得到初步提取特征图;所述通道特征提取器,用于对所述初步提取特征图以通道维度进行特征提取,得到通道特征图;所述像素特征提取器,用于对所述初步提取特征图以像素维度进行特征提取,得到像素特征图;所述类别特征提取器,用于对所述初步提取特征图以类别维度进行特征提取,得到类别特征图;所述特征转化器,用于将所述通道特征图,所述像素特征图和所述类别特征图进行融合,得到目标特征图,并将所述目标特征图转化为与所述眼底照片标签对应的类别识别结果;所述第二读取单元,还用于读取待识别的眼底照片数据;所述类别输出单元,用于将所述待识别的眼底照片数据输入所述类别加权网络模型,将所述模型输出概率最大的类别作为所述眼底照片的类别结果。
[0017]
本发明提供一种基于类别加权网络的眼底照片分类方法与装置,本发明的类别加权网络模型通过对不同类别数据给予不同的类别权重,从而实现了不同难易程度数据间的平衡。更进一步的,在不同类别权重的确定上,本发明还提出通过计算类型梯度范数来提供参考,避免了在所述模型训练阶段,需要根据研究人员的过往经验和反复实验来手动调整权重参数的大量时间、精力上的消耗。
附图说明
[0018]
图1为本发明一实施例的基于类别加权网络的眼底照片分类方法的流程框图;图2为本发明一实施例的类别加权网络的结构示意图;图3为本发明一实施例的基于类别加权网络的眼底照片分类装置的结构框图。
具体实施方式
[0019]
为使本领域技术人员更好地理解本发明的技术方案,下面结合附图和具体实施方式对本发明作进一步详细描述。显然,所描述的实施例是本发明的一部分实施例,而不是全部的实施例。基于所描述的本发明的实施例,本领域普通技术人员在无需创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护范围。
[0020]
除非另外具体说明,本发明中使用的技术术语或者科学术语应当为本发明所属领域内具有一般技能的人士所理解的通常意义。本发明中使用的“包括”或者“包含”等既不限定所提及的形状、数字、步骤、动作、操作、构件、原件和/或它们的组,也不排除出现或加入一个或多个其他不同的形状、数字、步骤、动作、操作、构件、原件和/或它们的组。此外,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指
示技术特征的数量与顺序。
[0021]
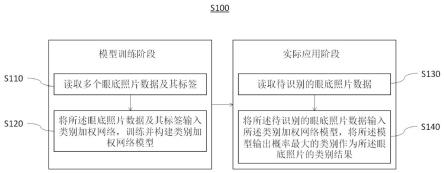
如图1和图2所述,本发明提供一种基于类别加权网络的眼底照片分类方法s100,具体包括步骤s110~s140:需要说明的是,本实施例的分类方法包括两个阶段,分别为模型训练阶段和模型实际应用阶段,其中,模型训练阶段包括步骤s110~s120,模型实际应用阶段包括步骤s130~s140,也就是说,先建立识别眼底照片类别的分类模型,再基于该分类模型对眼底照片的类别进行识别,基于眼底照片的识别结果可以得到糖尿病视网膜病变等级,即实现对糖尿病视网膜病变的筛查。
[0022]
s110、读取多个眼底照片数据及其标签。
[0023]
具体的,本实施例不仅需要读取眼底照片数据,还需要读取眼底照片对应的标签,可以传入由训练数据文件路径和训练数据标签数据组成的列表,并通过opencv-python(cv2)库打开对应的图片,将读取的数据传输给后续任务。
[0024]
需要说明的是,本实施例的眼底照片标签包括糖尿病视网膜病变的五个病重程度等级,分别记作dr0-dr4。在模型训练阶段,读取完毕后,还需要对眼底照片数据进行数据增强。
[0025]
作为进一步地优选方案,本发明在训练阶段对眼底照片进行随机上下翻转、随机左右翻转和随机旋转处理。也就是说,对眼底照片进行数据扩增与增强的预处理,以形成增强数据集,再对增强数据集中的眼底照片数据进行读取。
[0026]
s120、根据眼底照片数据及其标签训练并构建类别加权网络模型,该构建形成的模型作为眼底照片的分类模型,以对眼底照片的类别进行智能识别。
[0027]
具体的,先将眼底照片数据输入到类别加权网络中,进行类型识别训练;再将识别结果与真实标签一起作为损失函数的参数进行损失计算,通过反向传播更新模型参数;循环上述操作,直到损失趋于稳定,不再下降,得到构建完成的类别加权网络模型。
[0028]
s130、读取待识别的眼底照片数据。
[0029]
具体的,通过opencv-python(cv2)库打开对应的图片,将读取的数据传输给后续任务。
[0030]
需要说明的是,实际应用过程中,读取眼底照片数据后,不进行数据增强处理,而是直接将原图输入类别加权网络模型中进行类型识别。
[0031]
s140、将待识别的眼底照片数据输入类别加权网络模型,将模型输出概率最大的类别作为眼底照片的类别结果。
[0032]
需要说明的是,实际应用过程中,对识别结果不进行损失计算,不对模型参数进行更新。
[0033]
进一步需要说明的是,本发明使用的类别加权网络,通过对不同类别数据给予不同规模的学习通道,从而实现了不同难易程度数据间的平衡,提高了眼底照片类型识别的准确度,不同于常见的在损失计算过程中进行数据平衡,本发明在模型结构层面实现了数据平衡,网络结构如图2所示。
[0034]
更进一步的,在不同类别权重的确定上,本发明通过计算类型梯度范数,避免了在训练过程中,需要根据研究人员的过往经验和反复实验来手动调整权重参数的大量时间、精力上的消耗。
[0035]
具体的,步骤s120中的网络建模的过程如下:第一、使用基本特征提取器对眼底照片进行初步特征提取,得到初步提取特征图fb。
[0036]
需要说明的是,基本特征提取器可以使用任何当前成熟的预训练网络,如resnet,inceptionnet,densenet,以及谷歌公司近几年新提出的efficeientnet等,并对其加以改造。
[0037]
具体的,改造包括:删除原有网络最后的全连接层,使网络不直接给出分类结果,而是对所述眼底照片进行初步的特征提取,得到初步提取特征图。
[0038]
第二、使用通道特征提取器对初步提取特征图通道维度的特征进行提取,得到通道特征图fc。
[0039]
具体的,其使用像素维度的全局平均池化和conv_block得到通道权重分布;conv_block的结构的具体关系式如下:其中,cb表示conv_block层,x表示输入conv_block层的特征图,conv表示1*1的卷积层,作为过渡层,其输出通道数与输入数据x的通道数相同,bn表示batch normalization,relu和sigmoid分别表示relu激活函数和sigmoid激活函数,他们为网络引入非线性因素;通道特征提取器的结构的具体关系式如下:其中,fb表示眼底照片p经过基本特征提取器之后,得到初步提取特征图;gap
p
表示在像素维度做全局平均池化,其使模型在此处忽略像素维度的特征,而更加专注于不同通道维度特征带给模型的影响;cb表示上述conv_block层,表示矩阵点乘,经过cb层后得到的通道权重分布与初步提取特征图fb相点乘,最终得到通道特征图fc。
[0040]
第三、使用像素特征提取器对初步提取特征图像素维度的特征进行提取,得到像素特征图f
p
。
[0041]
具体的,它使用通道维度的全局平均池化和conv_block得到像素权重分布,像素特征提取器的结构的具体关系式如下:其中,cb,fb和含义与上述的关系式相同,gapc表示通道维度的全局平均池化,它将特征图中的各个通道间取平均值,压缩至1个通道,使模型忽略通道维度的特征,而更加专注于不同像素对模型的贡献;经过cb层后得到的像素权重分布与初步提取特征图fb相点乘,得到像素特征图f
p
。
[0042]
第四、使用类别特征提取器于对初步提取特征图类型维度的特征进行提取,得到类型特征图f
t
。
[0043]
具体的,用1*1的卷积层,先将初步提取特征图fb的通道扩充为k层,得到fk,k的具体关系式如下:
其中,n表示图片的类型数,ki表示第i类分配的通道数,即类型权重,k为所有类型的通道总数,即总权重;模型可以对第i个类别通过ki个通道提取特征,ki的值越大,模型则能够从更多的角度去理解和提取特征;针对不同难易程度的数据给予不同的类型权重,可以在模型层面对数据进行平衡。
[0044]
然后对具有k个通道的特征图fk按类型通道池化,得到忽略通道维度特征的特征图fn;该忽略通道维度特征的特征图fn共有n层通道,每层通道指示一个类型的特征,具体关系式如下:其中,fb表示初步提取特征图,convk表示k个1*1的卷积层,gmpk表示对每层通道执行一次最大池化,即按类型通道池化,最终得到忽略通道维度特征的fn。
[0045]
然后对fn在像素维度做全局平均池化,进一步忽略其在像素维度的特征,让其仅专注于学习类型维度上的特征。经过conv_block得到类型权重分布,再与fn点乘,可得到初步的类型特征图。具体关系式如下:其中,表示初步的类型特征图,其他符号含义与前文记载的关系式相同;最后,对执行通道维度的全局平均池化和conv_block得到最终的类型权重分布,具体关系式如下:其中,f
t
为得到的类型特征图,其他符号含义与上述关系式相同。
[0046]
第五、使用特征转化器对不同维度的特征图进行融合,得到最终的特征图,再将最终的特征图转化为对眼底照片标签的对应类型识别结果。
[0047]
具体的,对上述通道特征图fc,像素特征图f
p
,以及类型特征图f
t
经过全局平均池化层和全连接层等得到最终的输出;具体关系式如下:其中,fc,f
p
,f
t
,relu和gap
p
的含义与上述关系式相同,表示对不同矩阵间对应位置的元素求平均,fch和fcn都表示全连接层,前者的输出通道数为输入通道数的一半,后者的输出通道数为分类数n;out为模型最终的输出,是一个batch*n维的向量,向量元素的值代表了对应位置模型识别类型的可能性大小,选取最大的值的位置下标,作为模型最终的识别结果。
[0048]
更进一步地,为了避免了在训练过程中,需要根据研究人员的过往经验和反复实验来手动调整权重参数的大量时间、精力上的消耗,本发明通过计算类型梯度范数,对类型权重的设置提供参考,具体关系式如下:其中,gi表示第i类的类型梯度范数,ni表示第i类的样本数,l
t
表示样本t经过模型后产生的cross entropy loss,out
t
表示i类的样本t经过模型计算后的直接输出(未经过
softmax层);令p=softmax(out),y表示样本的one-hot向量表示,又由于就可以对类型梯度范数的计算进行简化,具体关系式如下:根据不同类型梯度范数gi的大小比例,可以得到类型权重的大小比例。
[0049]
需要说明的是,本实施例在计算类型梯度范数时,需要先将类别加权网络初始的类型权重统一设置为5,再将眼底照片数据输入到类别加权网络中,进行类别识别过程的训练;再将识别结果与真实标签一起作为损失函数的参数进行损失计算,通过反向传播更新模型参数;循环上述操作,直到损失趋于稳定,不再下降,得到初步收敛的类别加权网络模型。根据此模型可以计算相应眼底照片数据的类型梯度范数。
[0050]
进一步需要说明的是,本发明在训练阶段得到类型识别结果后,还需要对模型进行更新,以选择效果最好的作为最终的眼底照片分类模型,因此,在上述建模之后,对眼底照片的类型识别步骤s120还包括有以下步骤:第六、将眼底照片的识别结果与其真实标签进行比较计算交叉熵损失,并反向传播更新模型参数。循环损失计算与参数更新的过程,直到损失趋于稳定,不再下降,得到类别加权网络模型,其中,采用交叉熵损失函数计算损失,具体关系式如下:其中,x[class]代表输入数据x实际所属类别,x[j]代表模型对于输入数据x所属类别j的识别结果。
[0051]
仍需要说明的是,训练阶段中每一轮损失计算都会用来更新模型,本实施例每隔一定轮数保存一次模型,最终选择效果最好的一个作为最终的眼底照片分类模型。而实际应用阶段,模型仅输出眼底照片的分类结果,无需更新自身,故无需计算损失。当然,如果后期输入数据逐渐增加,希望进一步更新模型,也可在已有模型基础上,继续训练,重新选择效果更好的模型。
[0052]
本实施例基于上述过程构建了眼底照片分类模型,以用于筛选眼底照片对应的糖网病的病变程度,基于形成的模型对待识别眼底照片进行类型识别的过程s130~s140包括:读取待筛查的眼底照片数据;采用上述构建的类别加权网络模型,将读取的眼底照片数据输入类别加权网络模型,对待识别的眼底照片数据进行类型识别,将模型输出概率最大的类别作为眼底照片的类别结果。
[0053]
如图3所示,本发明的另一方面,提供一种基于类别加权网络的眼底照片分类装置200,包括:第一读取单元210、模型形成单元220、第二读取单元230以及类别输出单元240;其中,第一读取单元210,用于读取多个眼底照片数据及其标签,即在模型训练阶段时,需要利用第一读取单元读取眼底照片的数据及对应标签,以用于后续的模型训练;
模型形成单元220,用于将眼底照片数据及其标签输入类别加权网络,训练并构建类别加权网络模型,即该模型作为眼底照片的分类模型,以对眼底照片的类别进行识别;其中,模型形成单元220还包括:基本特征提取器221、通道特征提取器222、像素特征提取器223、类别特征提取器224以及特征转化器225;基本特征提取器221,用于对眼底照片数据进行初步特征提取,得到初步提取特征图;通道特征提取器222,用于对初步提取特征图以通道维度进行特征提取,得到通道特征图;像素特征提取器223,用于对初步提取特征图以像素维度进行特征提取,得到像素特征图;类别特征提取器224,用于对初步提取特征图以类别维度进行特征提取,得到类别特征图;特征转化器225,用于将通道特征图,像素特征图和类别特征图进行融合,得到目标特征图,并将目标特征图转化为与眼底照片标签对应的类别识别结果;第二读取单元230,还用于读取待识别的眼底照片数据;类别输出单元240,用于将待识别的眼底照片数据输入至上述构建形成的类别加权网络模型,将模型输出概率最大的类别作为眼底照片的类别结果。
[0054]
需要说明的是,在模型训练阶段,本实施例的第一读取单元不仅需要读取眼底照片数据,还需要读取眼底照片对应的标签,可以传入由训练数据文件路径和训练数据标签数据组成的列表,并通过opencv-python(cv2)库打开对应的图片,将读取的数据传输给后续任务。在模型实际应用阶段时,第二读取单元仅读取眼底照片的数据,利用前文训练形成的模型对该眼底照片数据的标签类别进行识别。
[0055]
进一步需要说明的是,本实施例的眼底照片标签包括糖尿病视网膜病变的五个病重程度等级,分别记作dr0-dr4。在模型的训练阶段,利用第一读取单元读取完毕后,还需要对眼底照片数据进行数据增强。也就是说,本实施例的装置还包括有增强单元250(如图3所示),在训练阶段,利用增强单元对眼底照片进行随机上下翻转、随机左右翻转和随机旋转处理,即对眼底照片进行数据扩增与增强的预处理,以形成增强数据集,再对增强数据集中的眼底照片数据进行读取。
[0056]
更进一步地,本实施例使用基本特征提取器对眼底照片进行初步特征提取,得到初步提取特征图fb。其中,所使用的基本特征提取器可以使用任何当前成熟的预训练网络,如resnet,inceptionnet,densenet,以及谷歌公司近几年新提出的efficeientnet等,并对其加以改造。
[0057]
具体的,改造包括:删除原有网络最后的全连接层,使网络不直接给出分类结果,而是对眼底照片进行初步的特征提取,得到初步提取特征图。
[0058]
更进一步地,本实施例使用通道特征提取器对初步提取特征图通道维度的特征进行提取,得到通道特征图fc的具体过程如下:使用像素维度的全局平均池化和conv_block得到通道权重分布;conv_block的结构的具体关系式如下:
其中,cb表示conv_block层,x表示输入conv_block层的特征图,conv表示1*1的卷积层,作为过渡层,其输出通道数与输入数据x的通道数相同,bn表示batch normalization,relu和sigmoid分别表示relu激活函数和sigmoid激活函数,他们为网络引入非线性因素;通道特征提取器的结构的具体关系式如下:其中,fb表示眼底照片p经过基本特征提取器之后,得到初步提取特征图;gap
p
表示在像素维度做全局平均池化,其使模型在此处忽略像素维度的特征,而更加专注于不同通道维度特征带给模型的影响;cb表示上述conv_block层,表示矩阵点乘,经过cb层后得到的通道权重分布与初步提取特征图fb相点乘,最终得到通道特征图fc。
[0059]
更进一步地,本实施例使用像素特征提取器对初步提取特征图像素维度的特征进行提取,得到像素特征图f
p
的具体过程如下:使用通道维度的全局平均池化和conv_block得到像素权重分布,像素特征提取器的结构的具体关系式如下:其中,cb,fb和含义与上述的关系式相同,gapc表示通道维度的全局平均池化,它将特征图中的各个通道间取平均值,压缩至1个通道,使模型忽略通道维度的特征,而更加专注于不同像素对模型的贡献;经过cb层后得到的像素权重分布与初步提取特征图fb相点乘,得到像素特征图f
p
。
[0060]
更进一步地,本实施例使用类别特征提取器于对初步提取特征图类型维度的特征进行提取,得到类型特征图f
t
。
[0061]
具体的,用1*1的卷积层,先将初步提取特征图fb的通道扩充为k层,得到fk,k的具体关系式如下:其中,n表示图片的类型数,ki表示第i类分配的通道数,即类型权重,k为所有类型的通道总数,即总权重;模型可以对第i个类别通过ki个通道提取特征,ki的值越大,模型则能够从更多的角度去理解和提取特征;针对不同难易程度的数据给予不同的类型权重,可以在模型层面对数据进行平衡。
[0062]
然后对具有k个通道的特征图fk按类型通道池化,得到忽略通道维度特征的特征图fn;该忽略通道维度特征的特征图fn共有n层通道,每层通道指示一个类型的特征,具体关系式如下:其中,fb表示初步提取特征图,convk表示k个1*1的卷积层,gmpk表示对每层通道执行一次最大池化,即按类型通道池化,最终得到忽略通道维度特征的fn。
[0063]
然后对fn在像素维度做全局平均池化,进一步忽略其在像素维度的特征,让其仅
专注于学习类型维度上的特征。经过conv_block得到类型权重分布,再与fn点乘,可得到初步的类型特征图。具体关系式如下:其中,表示初步的类型特征图,其他符号含义与前文记载的关系式相同;最后,对执行通道维度的全局平均池化和conv_block得到最终的类型权重分布,具体关系式如下:其中,f
t
为得到的类型特征图,其他符号含义与上述关系式相同。
[0064]
更进一步地,为了避免了在训练过程中,需要根据研究人员的过往经验和反复实验来手动调整权重参数的大量时间、精力上的消耗,本发明通过计算类型梯度范数,需要对上述类型权重的设置提供参考,即本实施例的模型形成单元还包括有权重设置模块,具体关系式如下:其中,gi表示第i类的类型梯度范数,ni表示第i类的样本数,l
t
表示样本t经过模型后产生的cross entropy loss,out
t
表示i类的样本t经过模型计算后的直接输出(未经过softmax层);令p=softmax(out),y表示样本的one-hot向量表示,又由于就可以对类型梯度范数的计算进行简化,具体关系式如下:根据不同类型梯度范数gi的大小比例,可以得到类型权重的大小比例。
[0065]
需要说明的是,本实施例在计算类型梯度范数时,需要先将类别加权网络初始的类型权重统一设置为5,再将眼底照片数据输入到类别加权网络中,进行类型识别训练;再将识别结果与真实标签一起作为损失函数的参数进行损失计算,通过反向传播更新模型参数;循环上述操作,直到损失趋于稳定,不再下降,得到初步收敛的类别加权网络模型。根据此模型可以计算相应眼底照片数据的类型梯度范数。
[0066]
更进一步的,本实施例使用特征转化器对不同维度的特征图进行融合,得到最终的特征图,再将最终的特征图转化为对眼底照片标签的综合类型识别结果,具体过程如下:对上述通道特征图fc,像素特征图f
p
,以及类型特征图f
t
经过全局平均池化层和全连接层等得到最终的输出;具体关系式如下:其中,fc,f
p
,f
t
,relu和gap
p
的含义与上述关系式相同,表示对不同矩阵间对应位置的元素求平均,fch和fcn都表示全连接层,前者的输出通道数为输入通道数的一半,后者的输出通道数为分类数n;out为模型最终的输出,是一个batch*n维的向量,向量元素的值代表了对应位置模型识别类型的可能性大小,选取最大的值的位置下标,作为模型最终的
类型识别结果。
[0067]
需要说明的是,本发明在训练阶段得到眼底照片分类结果后,还需要对模型进行更新,以选择效果最好的作为最终的眼底照片分类模型,因此,本实施例的模型形成单元还包括有更新模块,利用该更新模块对模型更新的过程如下:将眼底照片的识别结果与其真实标签进行比较计算交叉熵损失,并反向传播更新模型参数。循环损失计算与参数更新的过程,直到损失趋于稳定,不再下降,得到类别加权网络模型,其中,采用交叉熵损失函数计算损失,具体关系式如下:其中,x[class]代表输入数据x实际所属类别,x[j]代表模型对于输入数据x所属类别j的识别结果。
[0068]
仍需要说明的是,训练阶段中每一轮损失计算都会用来更新模型,本实施例每隔一定轮数保存一次模型,最终选择效果最好的一个作为最终的眼底照片分类模型。而实际应用阶段,模型仅输出眼底照片的分类结果,无需更新自身,故无需计算损失。当然,如果后期输入数据逐渐增加,希望进一步更新该模型,也可在已有模型基础上,继续训练,重新选择效果更好的模型。
[0069]
下面将结合具体实施例进一步说明基于类别加权网络的眼底照片的分类方法:实施例1本示例对具有糖尿病视网膜病变的眼底照片的类别进行识别,包括如下步骤:s1、计算类型梯度范数,为类别加权网络的类型权重设置提供参考,即在使用网络前确定类型梯度范数;s2、读取眼底照片数据和标签,对眼底照片数据进行数据增强;s3、使用基本特征提取器对眼底照片进行初步特征提取,得到初步提取的特征图;s4、使用通道特征提取器对初步提取的特征图通道维度的特征进行提取,通道特征图;s5、使用像素特征提取器对初步提取的特征图像素维度的特征进行提取,得到像素特征图;s6、使用类别特征提取器于对初步提取的特征图类型维度的特征进行提取,得到类型特征图;s7、使用特征转化器对不同维度的特征图进行融合,得到最终的特征图,再将最终的特征图转化为对眼底照片标签的综合识别结果;s8、将眼底照片的识别结果与其真实标签进行比较计算所述交叉熵损失,并反向传播更新所述模型参数;循环损失计算与参数更新的过程,直到损失趋于稳定,不再下降,得到类别加权网络模型;s9、读取待筛查的眼底照片数据,输入类别加权网络模型,将模型输出概率最大的类别作为所述眼底照片的类别结果。
[0070]
本发明提供一种基于类别加权网络的眼底照片的分类方法与装置,具有以下有益
效果:第一、本发明提出的基于类别加权网络的分类方法与装置,通过对不同类别数据给予不同规模的学习通道,从而实现了不同难易程度数据间的平衡。不同于常见的在损失计算过程中进行数据平衡,本发明在模型结构层面实现了数据平衡。
[0071]
第二、本发明在不同类别权重确定的基础上,提出了一个简单有效的方案,即通过计算类型梯度范数,避免了在实验过程中,需要根据研究人员的过往经验和反复实验来手动调整权重参数的大量时间、精力上的消耗。而这些消耗将随着类别数量的增加和数据规模的扩大呈现指数级别的增长。
[0072]
第三、本发明提出的基于类别加权网络的分类方法与装置,从三个不同的维度对眼底照片数据进行特征提取,提高了模型特征提取的性能与泛化能力,并且降低数据格式不统一所带来的影响。
[0073]
可以理解的是,以上实施方式仅仅是为了说明本发明的原理而采用的示例性实施方式,然而本发明并不局限于此。对于本领域内的普通技术人员而言,在不脱离本发明的精神和实质的情况下,可以做出各种变型和改进,这些变型和改进也视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1