一种基于知识库增强的跨域新闻推荐方法
1.本发明涉及人工智能技术领域,尤其涉及一种基于知识库增强的跨域新闻推荐方法。
背景技术:
2.随着互联网的普及,人们已经进入到一个信息爆炸的时代。每天都有海量的新闻产生和发布,人们难以在有限的时间内从大量新闻中找到自己感兴趣的内容,面临严重的新闻信息过载问题。为了帮助用户阅读到自己感兴趣的新闻,新闻推荐系统应运而生,它通过学习用户阅读新闻的历史,挖掘新闻内容之间的关联,提取出用户的兴趣,从而从海量的新闻中为用户个性化地筛选出用户感兴趣的新闻。新闻推荐系统已经广泛地应用在国内外众多新闻平台中,如google news、microsoft news、今日头条、腾讯新闻等,这些系统凭借精准的推荐功能,帮助用户高效的获取新闻信息,获得了大量用户的青睐。随着互联网中出现了大量的高质量资源,包括wikipedia、百度百科等,许多大规模的知识库得以建立,例如freebase、yago、dbpedia等。知识库使用海量的结构化三元组来表示知识。知识库中包含丰富的异构信息,因此可以从知识库中获得从单一领域无法获取的信息。随着越来越多的知识库被构建和完善,知识库中丰富的知识信息可以帮助新闻推荐系统更好地提取新闻之间的高阶关系,从而向用户更加精准地推荐新闻。
3.知识图谱以结构化的方式来叙述客观世界中概念、实体以及它们之间的关联,将互联网的信息叙述成更贴合人类认知世界的形式,提供更好的组织、管理和理解互联网庞大信息的能力。知识图谱促使互联网的信息搜索从传统的数据服务到更为人性化的知识服务。知识图谱在知识组织和展现上都表现出巨大的优势,这使它成为互联网时代的研究热点。
4.知识库在各领域的应用变得越来越广,推荐系统作为一门多领域交叉学科,可以借助其他领域的技术提高推荐系统的性能。因此,将知识库和推荐系统融合起来也是提升推荐系统性能的重要研究方向。基于知识库的推荐系统可以结合多源信息内容,更好地挖掘用户与商品之间的潜在关系,促进电子商务成为基于知识库的推荐系统的重要实践平台。在当今时代,国内外的众多大型公司已经建立知识库并将其用在自身的推荐模式中。
5.基于知识库的推荐系统通过将知识库和推荐系统融合在一起,不仅能达到推荐的目的,也能借助知识库技术来提升推荐的性能。但其在跨域新闻推荐领域的研究还处于理论研究阶段,本发明通过提出一种基于多知识库增强的跨域新闻推荐框架,将知识库在新闻推荐领域中进行推广和应用。
6.现有新闻推荐系统的研究中大量采用了基于语义相似度匹配的新闻推荐算法模型。通过训练语义提取模型,从新闻标题、摘要等非结构化文本信息中抽取与用户兴趣点相关的语义特征,将新闻编码为语义特征向量,并依据候选新闻与用户浏览历史新闻之间的语义相似度来实现个性化推荐。但新闻语言通常是高度浓缩的,由大量知识实体组成,因此此类方法存在三个弊端:
7.跨域问题严重。新闻领域类别数量较多,领域之间即使在语义和用户兴趣点方面有较大相关性,但在文本表述上的区别可能导致数据驱动的深度学习模型过度拟合领域相关但与用户兴趣判别无关的特征,从而导致跨域新闻推荐的准确度下降。
8.无法去除用户兴趣无关特征。新闻文本中包含了大量与用户兴趣无关的内容,这些内容之间的相似性无法用来刻画用户兴趣,反而会对基于语义相似度匹配的模型造成干扰,让模型难以抽取到与用户兴趣相关的语义信息。
9.缺少常识信息。已有的模型只使用语义信息建模用户兴趣,没有使用到知识库中的常识和知识,无法根据常识做相关兴趣点的推理。这些方法只能基于单词的共现或聚类结构来找到新闻的关联性,几乎无法发现新闻之间潜在的知识层级的关联性。新闻的文本中存在着大量的新闻实体,可以链接到知识库中,从而获得实体相关的大量信息作为推荐的特征。如果用户历史阅读过的新闻中包含的实体与某个新闻中的实体有关联,那么用户很可能会对这个新闻感兴趣。融入知识库信息可以更好更精准地向用户推荐感兴趣的新闻。
技术实现要素:
10.为此,本发明首先提出一种基于知识库增强的跨域新闻推荐方法,方法通过引入freebase、wordnet和mind数据集作为输入,从mind数据集中提取新闻内容语料输入基于对抗训练的跨域实体抽取模型,并输出新闻实体名称后,与从freebase中引入的实体共同输入基于多策略集成的新闻实体链接模型,得到最终实体间匹配度得分;将所述最终实体间匹配度得分、mind数据集中提取的所述新闻内容语料,mind数据集中提取的新闻类别信息得到的词汇以及word net中得到词汇三者共同作为多知识图谱增强的新闻推荐模型的输入,经过计算得到对用户兴趣点进行推理及预测,在待选新闻中找出符合用户兴趣点的新闻向用户推荐。
11.方法分为三个部分:
12.一是基于对抗训练的跨域实体抽取模型:通过构建领域判别器与对抗损失函数,引导词嵌入模型学习到与新闻领域无关、但对实体识别及序列标注有价值的单词特征,高质量地实现新闻非结构化文本内容中的跨域实体识别与抽取;
13.二是基于多策略集成的新闻实体链接模型:通过定义四类实体间匹配度度量指标,构建一个集成词干匹配度、符号相似度、语义相似度、实体流行度等多维度信息的实体链接模型,实现了新闻文本抽取所得实体到知识库中实体的映射;
14.三是多知识图谱增强的新闻推荐模型:设计构建了一个融合新闻内容语义表征、新闻实体知识编码、新闻类别与子类别知识编码的推荐系统算法框架,实现利用知识库中的常识信息来对用户兴趣点进行推理及预测。
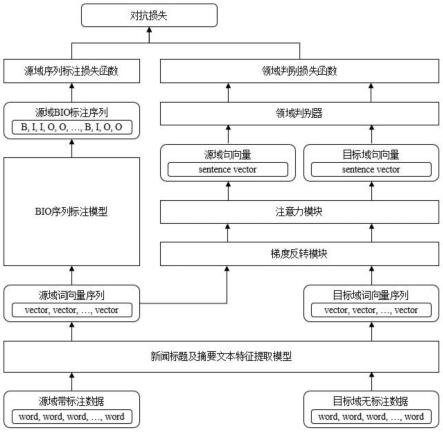
15.所述基于对抗训练的跨域实体抽取模型具体结构为:将源域带标注数据与目标域无标注数据通过新闻标题及摘要文本特征提取模型,分别得到源域词向量序列和目标域词向量序列;源域词向量序列经过bio标注模型得到源域bio标注序列,并使用损失函数计算损失;目标域词向量序列经过梯度翻转模块和注意力模块得到句向量,并使用领域判别计算损失;最终得出损失函数;
16.模型的运算部由两部分构成,分别是生成bio标注的基础分类器,以及使用对抗训
练方法的跨域鉴别器;
17.所述生成bio标注的基础分类器输入源域词向量序列,即给出x=[w1,w2,
…
,wn],经过bio序列标注模型得到源域bio标注序列y=[l1,l2,
…
,ln],对新闻的内容语料x=[w1,w2,
…
wn]进行实体抽取;bio序列标注模型首先将新闻的内容语料中的每个单词w
t
转换成单词的嵌入向量e
t
,得到新闻内容语料的词嵌入向量表示[e1,e2,
…en
];接着,使用文本特征提取器对新闻内容语料中每个单词的词嵌入向量e
t
进行上下文信息提取,得到每个单词的隐层的向量表示h
t
;选用特征提取方面常用的双向长短期记忆模型以及在大规模数据上经过预训练的bert模型作为文本特征提取器;
[0018]
bilstm作为文本特征提取器时,隐层向量表示为:
[0019][0020]
bert模型作为文本特征提取器时,隐层向量表示为:
[0021]ht
=bert(e
t
)
[0022]
进而,对新闻内容语料中各词的词向量经过特征抽取,得到新闻内容语料的特征表示[h1,h2,
…hn
];该特征表示作为实体抽取中的任务分类器的输入,通过线性层和softmax层预测每个单词的bio标注,新闻内容语料中第t个单词所对应标注的概率分布y
t
为:
[0023]yt
=softmax(w
yht
+by)
[0024]yt
是一个三维向量,代表新闻内容语料中第t个词属于bio这三类标注的概率分布。第t个词的bio标注l
t
根据y
t
的分布情况得到:
[0025][0026]
损失函数l的计算方法为:所述使用对抗训练方法的跨域鉴别器输入源域词向量序列和目标域词向量序列,经过梯度反转模块、注意力模块后,分别得到源域句向量和目标域句向量,并输入领域判别器得到领域判别损失函数域句向量,并输入领域判别器得到领域判别损失函数为了特征提取器能够尽可能地提取出领域无关的特征,构建一个对抗损失函数l
adv
。在这个损失函数中,我们为表示新闻内容语料属于源领域还是目标领域设置了变量zi。对于每个新闻内容语料xi,如果它是来自源领域,就置zi=1;如果它是来自目标领域,则置zi=0。对抗损失函数最终的联合损失函数l为基础分类器损失函数l
cr
和跨域对抗鉴别器损失函数l
adv
二者的加和,即l=l
cr
+λ
adv
l
adv
;
[0027]
所述基于多策略集成的新闻实体链接模型采用无监督的实体链接方式,给定一个新闻内容语料抽取所得实体与一个候选知识库实体,预处理后的新闻实体名称将与候选知识库实体名称进行四项匹配度指标的计算,本文定义的这些指标分别为:实体词根匹配度、实体符号匹配度、实体语义匹配度和知识库实体流行度。计算最终实体间匹配度得分。并根据匹配度得分选取最高的n个新闻实体,或者mind的语料或wordnet的词汇,生成出新闻表征向量。
[0028]
所述多知识图谱增强的新闻推荐模型目标是基于用户新闻浏览历史数据计算出用户对候选新闻的预测点击率,根据预测点击率对候选新闻进行排序,最后将排序靠前的
新闻组成新闻推荐列表推荐给用户以满足用户的新闻阅读兴趣,模型的输入为用户i点击浏览过的历史新闻和一篇候选新闻nj;对于每一篇新闻,将新闻原始数据分为新闻内容语料x与新闻类别两部分关键信息项;其中将新闻的内容语料x完成分词作为roberta的输入,然后经过池化层得到新闻的内容文本表征;另外将新闻内容语料x作为前文提出的实体抽取及链接预测模块的输入,结合freebase知识库获得关键的实体信息,然后经过知识编码模块和池化层得到新闻的内容图表征;类别c与子类别subc信息作为结合wordnet知识库的前文提出的实体链接预测模块的输入,获得包含上下位语义关系的类别信息,然后经过知识编码模块得到新闻的类别图表征与子类别图表征;最后将这四部分信息表征融合成深度全面语义的新闻信息表征;
[0029]
通过用户i点击浏览过的历史新闻获得用户i点击浏览过的历史新闻表征通过候选新闻nj获得候选新闻表征e(nj);为了得到用户i关于当前候选新闻nj的用户表征e(i),使用基于注意力的方法,计算候选新闻nj与每一篇历史新闻的相似度将相似度作为权重汇总用户的历史新闻阅读兴趣,生成用户表征e(i);用户表征e(i)和候选新闻表征e(nj)通过点击预测模块计算用户i点击候选新闻nj的概率
[0030]
本发明所要实现的技术效果在于:
[0031]
本发明通过对实体抽取、实体链接、新闻推荐方法的研究,实现了一个可以有效解决跨域推荐问题的知识库增强的新闻推荐系统,并在mind数据集上对各个子模块及完整算法的有效性进行评估。
附图说明
[0032]
图1整体模型框架
[0033]
图2基于对抗训练的跨域实体抽取模型框架
[0034]
图3基于多策略集成的新闻实体链接模型框架
[0035]
图4多知识图谱增强的新闻推荐方法模型框架
具体实施方式
[0036]
以下是本发明的优选实施例并结合附图,对本发明的技术方案作进一步的描述,但本发明并不限于此实施例。
[0037]
本发明提出了一种基于知识库增强的跨域新闻推荐方法。通过引入两项外源知识库:freebase与wordnet,利用知识库中的常识信息辅助新闻中与用户兴趣点相关特征的提取,实现了一个知识增强的新闻推荐系统,同时基于对抗训练方法提升了系统在跨域新闻推荐问题上的有效性。
[0038]
方法通过引入freebase、wordnet和mind数据集作为输入,从mind数据集中提取新闻内容语料输入基于对抗训练的跨域实体抽取模型,并输出新闻实体名称后,与从freebase中引入的实体共同输入基于对抗训练的跨域实体抽取模型,得到最终实体间匹配度得分;将所述最终实体间匹配度得分、mind数据集中提取的所述新闻内容语料,mind数据
集中提取的新闻类别信息得到的词汇以及wordnet中得到词汇三者共同作为多知识图谱增强的新闻推荐模型的输入,经过计算得到对用户兴趣点进行推理及预测,在待选新闻中找出符合用户兴趣点的新闻向用户推荐。
[0039]
freebase是一个类似维基百科的创意分享网站,它也采取了众包的形式,所有内容都由用户添加,它使用一个创造性的共享许可证,可以自由引用。freebase和维基百科最大的区别在于freebase条目是结构化数据,而不像维基百科。此外,freebase更注重数据的质量,为信息的查询和处理提供了便利。根据数据大小,其结构分为三个层:域、类型和主题。目前freebase有5600多万个实体和7000多个关系或属性。freebase在2010年被谷歌收购,并宣布在2015年关闭访问,但它的数据仍然可供研究人员下载和使用。基于freebase的千万量级的实体信息,以及其信息的高质量、开源等特征,因此本任务采用freebase作为新闻实体表征增强的外部知识库。
[0040]
wordnet是美国普林斯顿大学教授乔治
·
阿米蒂格
·
米勒创建的英语词典,它包含语义信息,根据词义将单词分类到集合中。一组具有相同含义的单词被定义为同义词集(synset)。然后在语义上连接和关联来创建一个词汇网络。wordnet目前包含超过11万个概念和20万个连接。wordnet拥有典型的词汇语义上下位结构,可以用于增强新闻类别的树状层级结构特征。
[0041]
mind(microsoft news dataset)数据集是
[0042]
微软亚洲研究院联合微软新闻产品团队在acl 2020上发布的一个大规模的英文新闻推荐数据集。它是从六周内microsoft news用户的匿名化新闻点击记录中构建的,它包含16万多条新闻条目,1500余万次展示记录,以及来自100万匿名用户的2400余万次点击行为。
[0043]
方法分为三个部分:
[0044]
一是基于对抗训练的跨域实体抽取模型:通过构建领域判别器与对抗损失函数,引导词嵌入模型学习到与新闻领域无关、但对实体识别及序列标注有价值的单词特征,高质量地实现新闻非结构化文本内容中的跨域实体识别与抽取;
[0045]
二是基于多策略集成的新闻实体链接模型:通过定义四类实体间匹配度度量指标,构建一个集成词干匹配度、符号相似度、语义相似度、实体流行度等多维度信息的实体链接模型,实现了新闻文本抽取所得实体到知识库中实体的映射;
[0046]
三是多知识图谱增强的新闻推荐模型:设计构建了一个融合新闻内容语义表征、新闻实体知识编码、新闻类别与子类别知识编码的推荐系统算法框架,实现利用知识库中的常识信息来对用户兴趣点进行推理及预测。
[0047]
所述基于对抗训练的跨域实体抽取模型具体结构为:将源域带标注数据与目标域无标注数据通过新闻标题及摘要文本特征提取模型,分别得到源域词向量序列和目标域词向量序列;源域词向量序列经过bio标注模型得到源域bio标注序列,并使用损失函数计算损失;目标域词向量序列经过梯度翻转模块和注意力模块得到句向量,并使用领域判别计算损失;最终得出损失函数;
[0048]
模型的运算部由两部分构成,分别是生成bio标注的基础分类器,以及使用对抗训练方法的跨域鉴别器;
[0049]
所述生成bio标注的基础分类器输入源域词向量序列,即给出x=[w1,w2,
…
,wn],
经过bio序列标注模型得到源域bio标注序列y=[l1,l2,
…
,ln],对新闻的内容语料x=[w1,w2,
…
wn]进行实体抽取;bio序列标注模型首先将新闻的内容语料中的每个单词w
t
转换成单词的嵌入向量e
t
,得到新闻内容语料的词嵌入向量表示[e1,e2,
…en
];接着,使用文本特征提取器对新闻内容语料中每个单词的词嵌入向量e
t
进行上下文信息提取,得到每个单词的隐层的向量表示h
t
;选用特征提取方面常用的双向长短期记忆模型以及在大规模数据上经过预训练的bert模型作为文本特征提取器;
[0050]
bilstm作为文本特征提取器时,隐层向量表示为:
[0051][0052]
bert模型作为文本特征提取器时,隐层向量表示为:
[0053]ht
=bert(e
t
)
[0054]
进而,对新闻内容语料中各词的词向量经过特征抽取,得到新闻内容语料的特征表示[h1,h2,
…hn
];该特征表示作为实体抽取中的任务分类器的输入,通过线性层和softmax层预测每个单词的bio标注,新闻内容语料中第t个单词所对应标注的概率分布y
t
为:
[0055]yt
=softmax(w
yht
+by)
[0056]yt
是一个三维向量,代表新闻内容语料中第t个词属于bio这三类标注的概率分布。第t个词的bio标注l
t
根据y
t
的分布情况得到:
[0057][0058]
损失函数l的计算方法为:所述使用对抗训练方法的跨域鉴别器输入源域词向量序列和目标域词向量序列,经过梯度反转模块、注意力模块后,分别得到源域句向量和目标域句向量,并输入领域判别器得到领域判别损失函数域句向量,并输入领域判别器得到领域判别损失函数为了特征提取器能够尽可能地提取出领域无关的特征,构建一个对抗损失函数l
adv
。在这个损失函数中,我们为表示新闻内容语料属于源领域还是目标领域设置了变量zi。对于每个新闻内容语料xi,如果它是来自源领域,就置zi=1;如果它是来自目标领域,则置zi=0。对抗损失函数最终的联合损失函数l为基础分类器损失函数l
cr
和跨域对抗鉴别器损失函数l
adv
二者的加和,即l=l
cr
+λ
adv
l
adv
;
[0059]
所述基于多策略集成的新闻实体链接模型采用无监督的实体链接方式,给定一个新闻内容语料抽取所得实体与一个候选知识库实体,预处理后的新闻实体名称将与候选知识库实体名称进行四项匹配度指标的计算,本文定义的这些指标分别为:实体词根匹配度、实体符号匹配度、实体语义匹配度和知识库实体流行度。计算最终实体间匹配度得分。并根据匹配度得分选取最高的n个新闻实体,或者mind的语料或wordnet的词汇,生成出新闻表征向量。
[0060]
这里形式化地定义实体词根匹配度为match
rot
,定义实体符号匹配度为match
tok
,定义实体语义匹配度为match
sem
,定义知识库实体流行度为popular
ent
,最终新闻实体名称mention与知识库实体entity间匹配得分score(mention,entity)为:
[0061]
score(mention,entity)
[0062]
=α1×
match
rot
(mention,entity)+α2[0063]
×
match
tok
(mention,entity)+α3×
match
sem
(mention,entity)
[0064]
+α4×
popular
ent
(entity)
[0065]
实体词根匹配度指标算法伪代码如下
[0066][0067][0068]
实体词根匹配度指标算法伪代码
[0069]
实体符号匹配度计算方法为:给定待匹配的新闻实体名称字符串mention=[x1,x2,
…
,xm],其中xi为新闻实体名称字符串的第i个字符,m为新闻实体名称字符串的长度,候选的知识库实体名称字符串entity=[y1,y2,
…
,yn],其中yi为知识库实体名称字符串的第
i个字符,n为知识库实体名称字符串的长度,目标是将mention字符串变成entity字符串的形式,这里定义一个m行n列的二维距离d(m,n)矩阵:
[0070]
d(m,n)=d[i,j],1≤i≤m,1≤j≤n}
[0071]
其中,d[i,j]为矩阵d(m,n)中第i行第j列元素,代表子串mention[1,i]=[x1,x2,
…
,xi]和entity[1,j]=[y1,y2,
…
,yj]之间的最小编辑距离,则d[i,j]处的编辑距离可以表示为由d[i,j-1]、d[i-1,j]以及d[i-1,j-1]三个状态下的编辑距离推导,具体为:
[0072][0073]
其中,mention[i]=xi,entity[j]=yj。
[0074]
由此便可以求得新闻实体名称与知识库实体名称之间的距离d[m,n],再将两个字符串的总长度之和|mention|+|entity|减去该距离再与两个字符串的总长度之和做商便可得到新闻实体名称与知识库实体名称之间的实体符号匹配度指标match
tok
:
[0075][0076]
这里形式化地定义知识库中的实体为entity,其在知识库中作为关系尾实体的三元组数量为edgenum
tail
(entity),作为关系头实体的三元组数量为edgenum
head
(entity),则计算知识库实体流行度指标为:
[0077]
popular
ent
(entity)=edgenum
tail
(entity)+edgenum
head
(entity)
[0078]
所述多知识图谱增强的新闻推荐模型目标是基于用户新闻浏览历史数据计算出用户对候选新闻的预测点击率,根据预测点击率对候选新闻进行排序,最后将排序靠前的新闻组成新闻推荐列表推荐给用户以满足用户的新闻阅读兴趣,模型的输入为用户i点击浏览过的历史新闻和一篇候选新闻nj;对于每一篇新闻,将新闻原始数据分为新闻内容语料x与新闻类别两部分关键信息项;其中将新闻的内容语料x完成分词作为roberta的输入,然后经过池化层得到新闻的内容文本表征;另外将新闻内容语料x作为前文提出的实体抽取及链接预测模块的输入,结合freebase知识库获得关键的实体信息,然后经过知识编码模块和池化层得到新闻的内容图表征;类别c与子类别subc信息作为结合wordnet知识库的前文提出的实体链接预测模块的输入,获得包含上下位语义关系的类别信息,然后经过知识编码模块得到新闻的类别图表征与子类别图表征;最后将这四部分信息表征融合成深度全面语义的新闻信息表征;
[0079]
通过用户i点击浏览过的历史新闻获得用户i点击浏览过的历史新闻表征通过候选新闻nj获得候选新闻表征e(nj);为了得到用户i关于当前候选新闻nj的用户表征e(i),使用基于注意力的方法,计算候选新闻nj与每一篇历史新闻的相似度将相似度作为权重汇总用户的历史新闻阅读兴趣,生成用户表征e(i);用户表征e(i)和候选新闻表征e(nj)通过点击预测模块计算用户i点击候选新闻nj的概率
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1