一种基于固定类别中心的样本选择方法与流程
1.本发明涉及细粒度图像分类技术领域,具体为一种基于固定类别中心的样本选择方法。
背景技术:
2.细粒度图像分类在深度学习发展的浪潮下已经成为了一个热门研究方向。细粒度图像分类主要是针对子类进行的分类,难点在于区分各子类间的细微差别,在尺度或视点变化、复杂背景和遮挡,以及不同姿态下能准确识别出子类别。早期的细粒度图像分类方法一般都是采用基于人工设计特征进行分类,人工设计特征的局限性影响了细粒度分类的性能。此外,人工设计特征依赖于大量的精确的人工标注信息,这更加限制了细粒度图像分类算法的发展。
3.由于深度神经网络所表现出来的强大的特征提取能力,细粒度图像分类不再需要依靠精确的人工标注信息,仅依靠图像类别标签就可以实现分类,这使得细粒度图像分类技术迅猛发展。而网络图像数据集内部含有噪声标签,由于深度神经网络强大的学习能力,标签噪声的存在会误导神经网络的训练,大大影响网络训练的性能。最直接的处理标签噪声的方法是样本选择方法。样本选择方法拟挑选出干净样本并将干净样本送入网络进行后续训练,以减少噪声标签的影响。常规的样本选择方法基于小损失技巧(如co-teaching),没有充分考虑细粒度数据集的细粒度特征,当正确标记和错误标记的样本的损失分布大部分重叠时,小损失技巧不能很好地工作。
技术实现要素:
4.本发明的目的在于提供一种基于固定类别中心的样本选择方法,以解决上述背景技术提出的问题。
5.为实现上述目的,本发明提供如下技术方案:一种基于固定类别中心的样本选择方法,包括固定类别中心,样本选择和网络更新,具体步骤如下:s1.将样本集划分为两个集合:干净样本集与噪声集;s2.同时训练两个对等深度神经网络,两个深度神经网络分别从干净样本中学习在超球面上均匀分布的类别中心并固定;s3.再各自挑选出与类别中心有较大余弦相似度的样本作为干净样本;s4.最后每个深度神经网络使用对等深度神经网络挑选出的干净样本来更新网络。
6.进一步的,在s1中,将样本集划分为两个集合:干净样本集与噪声集,样本集;其中干净样本集又包含简单样本与硬样
本,在接下来的步骤中将挑选出干净样本集并且更好的利用硬样本进行训练,其中是第i个训练样本,是的标签;由于网络图像是含噪的,以小损失方法挑选出二分之一的样本用于生成类别中心,挑选方式如下:(6.1)通过利用上述方式生成每个类的预定义中心,最终生成均匀分布的类中心。
7.更进一步的,损失函数如下: (6.2)(6.3)(6.4)其中(6.2)为交叉熵损失,m为每个类之间的余弦间隔,s用于提高收敛速度,方程(6.3)是输出特征与预定义中心之间的最小损失函数,是输出特征,是相应的标号,是指预定义的类中心,其中n≥1是一个可以调整的超参数,n取2。
8.进一步的,在s2中,为了更好的学习模糊图像,利用特征归一化来约束特征的l2范数;常规的l2约束的softmax输出如下:
ꢀꢀ
(6.5)上式中,与分别为深度神经网络f1(f2)的最后一层的全连接层的参数与提取的特征,使用预训练生成的类别中心来初始化全连接层的参数,并使用l2范数来约束全连接层的参数与提取特征;最终得到样本特征与类别中心的余弦相似度:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6.6)。
9.更进一步的,归一化之后,使用一个超参数s来缩放余弦值,则经过归一化的softmax层的输出为:(6.7)经过归一化后,特征在超球面上以角度分布,最后一个全连接层的参数为预训练生成的每个类的中心;网络全连接层的输出为图片特征与每个类中心的余弦距离,记录每张图片与其相应类中心的余弦相似度:
ꢀꢀ
(6.8)为第个样本与其类别中心的余弦距离;挑选出与类别中心有着高余弦相似度的样本,挑选公式如下:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6.9)其中,为一个可校正的丢弃率,经过挑选的图片送入对等网络更新网络。
10.更进一步的,在s3中,对softmax层的输出进行平滑处理,平滑后的单张图片的交叉熵损失为:
ꢀꢀ
(6.10)其中,为平滑标签向量,的取值如下:(6.11) (6.12)最终使用更新网络。
11.与现有技术相比,本发明的有益效果是:本发明提出了一个固定类别中心的算法,与其他的小损失样本选择方法不同,ssfcc在进行样本选择之前最大化各子类的类间距离,大大的避免了不同细粒度子类间的样本的特征分布重合,进而提高样本选择的准确率;采
用平滑后的交叉熵损失来进行网络的反向传播。与常规的交叉熵损失相比,平滑后的交叉熵损失可以避免网络的“过度自信”,特别是在含噪条件下,标签平滑可以缓解网络由于错误预测而导致性能下降的问题。
附图说明
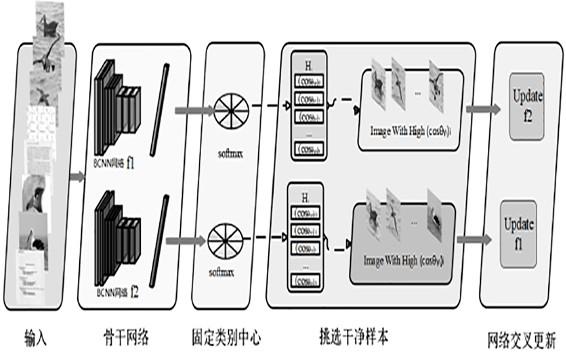
12.图1为bcnn网络示意图;图2为本发明ssfcc 网络主体结构示意图。
具体实施方式
13.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
14.实施例一请参照图1和2所示,本发明为一种基于固定类别中心的样本选择方法(sample selection based on fixed class center),简称ssfcc,本方法与现有方法的不同之处在于本方法考虑到细粒度数据集类间距离小的特点,在对图像进行样本选择之前首先学习样本的类别中心,并最大化各样本类别中心之间的距离。
15.首先,将样本集划分为两个集合:干净样本集与噪声集,样本集;其中干净样本集又包含简单样本与硬样本。在接下来的步骤中将挑选出干净样本集并且更好的利用硬样本进行训练,其中是第i个训练样本,是的标签。
16.在本实施例中,从统计模式识别的传统观点来看,维度降低的主要目标是生成最大类间距离和最小类内距离的低维表达式;如果类内方差较大,类间距离较近,则不同类之间会出现重叠,从而导致分类错误,受pedcc算法的启发,对于类间距离较近的细粒度数据集,本发明所提方法生成在超球面上均匀分布的类别中心,这一阶段被称为预训练阶段;对于单个网络,预训练阶段的目标是生成均匀分布的c个类别中心,以最大化类间距离。
17.pedcc算法是基于超球面上类电荷能量最低的物理模型生成的,将投影到超球面上的c个类别中心比做c个电荷点,超球面上的c个电荷点之间有排斥力,排斥力推动电荷运动,当运动最终达到平衡,超球面上的点停止运动时,c个点最终均匀分布在超球面上。
18.由于网络图像是含噪的,以小损失方法挑选出二分之一的样本用于生成类别中心,挑选方式如下:(6.1)
通过利用上述方式生成每个类的预定义中心,最终生成均匀分布的类中心,损失函数如下: (6.2)(6.3)(6.4)其中(6.2)为交叉熵损失,m为每个类之间的余弦间隔,s用于提高收敛速度,方程(6.3)是输出特征与预定义中心之间的最小损失函数,是输出特征,是相应的标号,是指预定义的类中心,其中n≥1是一个可以调整的超参数,n取2。
19.利用这个损失函数,可以人为地控制每个类的输出特征分布,使特征空间中的特征类之间的距离最大,类内的距离最小。
20.在本实施例中,由于网络图像是含噪的,直接使用网络图像进行训练会影响分类性能,挑选出干净样本进行训练可以缓解网络图像中标签的影响,ranjan等人在2017年上传于arxiv网站的l2-constrained softmax loss for discriminative face verification文章中指出l2约束的softmax当面临图像质量不平衡问题时,会通过增加高质量图像特征的l2范数来最小化softmax损失,而忽略模糊特征,为了更好的学习模糊图像,本方法利用特征归一化来约束特征的l2范数。常规的l2约束的softmax输出如下:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6.5)上式中,与分别为深度神经网络f1(f2)的最后一层的全连接层的参数与提取的特征;使用预训练生成的类别中心来初始化全连接层的参数,并使用l2范数来约束全连接层的参数与提取特征,最终得到样本特征与类别中心的余弦相似度:
ꢀꢀꢀ
(6.6)
归一化之后,使用一个超参数s来缩放余弦值,则经过归一化的softmax层的输出为:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6.7)经过归一化后,特征在超球面上以角度分布,最后一个全连接层的参数为预训练生成的每个类的中心。网络全连接层的输出为图片特征与每个类中心的余弦距离。本方法记录每张图片与其相应类中心的余弦相似度:
ꢀꢀ
(6.8)为第个样本与其类别中心的余弦距离。征归一化可以使网络更好的从模糊图像中学习,类似于硬示例挖掘,由于模糊图像的l2范数较低。在特征归一化之后,相对于具有大范数的特征,具有小范数的特征将获得更高的梯度。因此,这样处理使得网络在反向传播中好的利用模糊图像。
21.arpit等人发表在2017年机器学习国际会议international conference on machine learning上的文章a closer look at memorization in deep networks中提出深度神经网络倾向于优先学习简单干净的样本,然后才在后续的训练中逐渐拟合模糊的训练样本和噪声样本。受arpit等人的启发,由于网络是从干净样本中学习到类别中心,干净样本与类别中心有着更大的余弦相似度。本方法挑选出与类别中心有着高余弦相似度的样本。挑选公式如下:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6.9)其中,为一个可校正的丢弃率。经过挑选的图片送入对等网络更新网络。
22.在本实施例中,传统的softmax损失函数仅根据当前的训练数据对分类层参数进行调整,不约束分类层的权重和输出层的特征。在计算特征与权值之间的余弦距离时,不可避免地会受到权值和特征系数的影响,从而降低了预测精度,本网络在分类层与全连接层之间进行一次归一化,将余弦相似度归一化到0与1之间,有效的避免了权值和特征系数的影响。
23.han等人发表在2018年国际会议advances in neural information processing systems上的robust training of deep neural networks with extremely noisy labels文章中表示由于两个网络具有不同的学习能力,它们可以过滤噪声标签引入的不同类型的错误,因此本方法通过两个随机初始化的网络分别从网络数据集中学习,对于单个网络,神经网络最后一个分类层的权值由预训练生成的类中心初始化,在训练过程中不
发生变化。深度神经网络f1(f2)将挑选出来的干净集送入对等深度神经网络f2(f1)进行学习,随着网络学习能力的增强,两个网络挑选出来的干净集将趋于一致。
24.由于对于网络数据集来说,数据集中的正确标签不一定是样本的真实标签。因此在网络预测过程中,网络的“正确预测”不一定预测出真实的标签。lukasik等人在2020年发表在机器学习国际会议international conference on machine learning上的文章does label smoothing mitigate label noise中证明标签平滑可以避免在标签噪声存在的情况下对“正确预测”过于自信的问题,标签平滑为最终的激活产生更紧密的聚类和更大的类别间的分离的同时,提高了数据的干净和噪声部分的区分准确性。受lukasik等人的启发,本方法对softmax层的输出进行平滑处理,平滑后的单张图片的交叉熵损失为:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6.10)其中,为平滑标签向量,的取值如下:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6.11)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6.12)最终使用更新网络。
25.本发明算法流程如下:输入:训练集d训练总次数:预训练次数:预定义类别中心:丢弃率迭代次数输出:更新两个网络,随机初始化网络参数:
根据公式(6.5)更新网络与类别中心根据公式(6.5)更新网络与类别中心else:使用初始化网络的分类层的参数,并固定使用初始化网络的分类层的参数,并固定根据公式(6.7)计算样本与类别中心的余弦相似度根据公式(6.9)挑选出干净样本集,根据公式(6.12)使用干净样本集更新网络根据公式(6.12)使用干净样本集更新网络 。
26.尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1