基于姿态估计和Transformer的遮挡行人重识别方法与流程
基于姿态估计和transformer的遮挡行人重识别方法
技术领域
1.本发明涉及行人重识别技术领域,特别是涉及一种基于姿态估计和transformer的遮挡行人重识别方法。
背景技术:
2.行人重识别技术旨在关联不同摄像头下不同场景和视角下的特定行人。在真实的监控场景中,不可避免地会发现行人被遮挡的现象,这对重识别特征的提取带来了很大的挑战。存在遮挡时,由于部分人圣体不可见,因此如何提取鲁棒的局部特征并且利用局部特征进行匹配是解决遮挡行人重识别方法的关键。
3.现有的遮挡行人重识别方法可以分为手工划分和基于人体语义模型的方法。前者通过水平或切块划分的方式,将行人图像划分为多个预设局部区域,在局部区域内提取局部特征,然而手工划分的方法无法对齐人体部件,并且会引入大量背景噪声;后者往往基于人体语义模型,现有的方法往往先利用重识别模型和人体语义模型分别提取重识别特征和人体语义信息,利用人体语义信息对重识别特征进行后处理得到局部特征,这类方法只对重识别模型输出的重识别特征进行处理,没有将人体语义信息结合到重识别特征的提取过程中。
4.现有的遮挡行人重识别方法中的重识别模型大多基于卷积神经网络(cnn)。随着深度学习技术的发展,vision transformer网络中全局多头自注意力机制弥补了传统卷积神经网络难以捕捉全局特征的不足以及解决了下采样带来的信息损失问题。现有的基于vision transformer的遮挡行人重识别方法通过改进自注意力机制来提升特征提取的鲁棒性,但是没有考虑将人体姿态估计信息与自注意力机制进行结合来解决局部特征提取以及人体部件对齐问题。
技术实现要素:
5.本发明的目的是提供一种基于姿态估计和transformer的遮挡行人重识别方法,使用姿态估计提取人体姿态信息,使用姿态信息对人体区域进行划分,引入关键点令牌分别提取行人的关键点特征,利用关键点置信度对关键点距离进行加权得到最终的行人距离,从而提高遮挡场景下行人重识别算法的精度。
6.本发明中提出一种基于姿态估计和transformer的遮挡行人重识别方法,包括如下步骤:
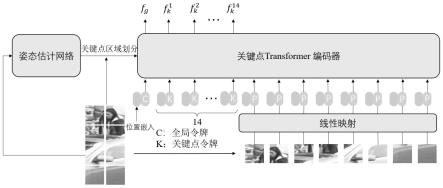
7.划分区域,姿态估计网络提取行人图像中行人的姿态估计信息,得到行人图像中每个人体关键点区域内的最高置信度,将行人图像划分为k个人体关键点区域和1个背景区域;
8.构建基于vision transformer的特征提取网络,提取行人图像的人体全局特征矩阵fg和人体关键点特征矩阵
9.对人体全局特征和人体关键点特征进行匹配,计算人体全局特征距离和k个人体
关键点特征距离,并对人体全局特征距离和关键点特征距离进行加权平均,其距离计算公式为:
[0010][0011]
上式中d()为余弦距离,f
a,g
和f
b,g
分别为给定的行人图像a和行人图像b的人体全局特征矩阵,和分别为给定的行人图像a和行人图像b的第i个人体关键点特征矩阵,和分别为给定的行人图像a和行人图像b第i个关键点区域内的最高置信度,λg和λk为权重因子。
[0012]
在一些实施方式中,划分区域的方法包括如下步骤:
[0013]
设定置信度的阈值δ,
[0014]
使用姿态估计网络提取行人的姿态估计信息,对于行人图像对应的空间中的每一个点,得到相对于k个人体关键点的置信度;
[0015]
提取每个点对应的k个置信度中的最高置信度,判断最高置信度是否大于阈值δ,若大于则将该点划分至当前最高置信度对应的人体关键点区域内,反之则将该点划分至背景区域内。
[0016]
在一些实施方式中,k取值为14,14个人体关键点包括左右手肘、左右手腕、左右肩膀、头、脖子、左右脚踝、左右膝盖以及左右臀。
[0017]
在一些实施方式中,提取行人图像的人体全局特征矩阵fg和人体关键点特征矩阵的过程如下:
[0018]
将行人图像分成固定大小的n个分块,通过线性映射得到n个分块特征,应用划分区域的方法将每个分块特征分入对应的人体关键点区域内;
[0019]
创建1个全局令牌和k个关键点令牌,将1个全局令牌、k个关键点令牌、的n个分块特征拼接得到长度为1+k+n的输入序列,将输入序列送入vision transformer的编码器中;
[0020]
在vision transformer的编码器上构建多头自注意力的计算公式,该公式为:
[0021][0022]
上式中q为查询向量,k为关键向量,v为值向量,d为查询向量的维度,softmax()为softmax函数;
[0023]
将全局令牌和所有分块特征映射到q、k、v对应的空间内,进行多头注意力计算,得到人体全局特征矩阵fg;
[0024]
将关键点令牌和与关键点令牌对应的关键点区域内的分块特征映射到q、k、v对应的空间内,进行多头注意力计算,得到人体关键点特征矩阵
[0025]
在一些实施方式中,所述基于vision transformer的特征提取网络应用了三元组损失函数和分类损失函数优化模型,基于三元组损失函数和分类损失函数调整所述基于vision transformer的特征提取网络的参数,三元组损失函数和分类损失函数优化模型中的损失函数的计算公式包括:
[0026]
人体关键点特征的三元组损失的计算公式:
[0027]
人体关键点特征的分类损失的计算公式:
[0028]
三元组损失函数和分类损失函数优化模型最终的损失函数:三元组损失函数和分类损失函数优化模型最终的损失函数:
[0029]
上式中
[0030]
d(a,p)和d(a,n)分别为锚样本与正样本的特征之间的距离,m为参数;
[0031]
n为样本类别数,zi为输出的分类概率;
[0032]
和分别为人体全局特征的三元组损失和分类损失,和为第i个人体关键点特征的三元组损失和分类损失,λ’g
和λ’k
为权重因子。
[0033]
在一些实施方式中,所述λ’g
和λ’k
的取值分别为0.5和
[0034]
在一些实施方式中,所述λg和λk分别为1和
[0035]
一种处理装置,包括处理器和存储模块,存储模块用于存储程序,所述处理器用于加载程序并执行以实现基于姿态估计和transformer的遮挡行人重识别方法。
[0036]
本发明中叙述的基于姿态估计和transformer的遮挡行人重识别方法具备如下优点:
[0037]
1、使用姿态估计网络得到行人姿态估计信息,根据姿态估计信息将行人图像划分为人体关键点区域和背景区域,有效的从背景和遮挡中分理处可见的人体关键点区域;
[0038]
2、使用关键点令牌提取关键点点特征,可以提取到鲁棒和有判别力的特征;
[0039]
3、有效提升了在遮挡场景下行人重识别的精度。
附图说明
[0040]
图1为本发明的一些实施方式中基于姿态估计和transformer的遮挡行人重识别方法的流程图;
[0041]
图2为本发明的一些实施方式中应用基于姿态估计和transformer的遮挡行人重识别方法进行重识别检索的结果输出图。
具体实施方式
[0042]
预先在姿态估计网络hr-net中设置置信度的阈值δ,通过阈值δ判断点所属区域。
[0043]
结合图1所示的内容,本实施例提出一种基于姿态估计和transformer的遮挡行人重识别方法,包括如下步骤:
[0044]
s1、给定行人图像a和行人图像b;
[0045]
s2、使用姿态估计网络hr-net提取行人的姿态估计信息,姿态估计信息中包括k个人体关键点的置信度,并根据置信度将行人图像a和行人图像b从空间上划分为k个关键点区域和1个背景区域,具体的划分过程包括如下步骤:
[0046]
s21、使用姿态估计网络hr-net提取行人的姿态估计信息,获取行人图像a和行人图像b对应的空间中的每一个点相对于k个人体关键点的置信度;
[0047]
s22、提取每个点对应的k个置信度中的最高置信度,判断最高置信度是否大于阈值δ,若大于则将该点划分至当前最高置信度对应的人体关键点区域内,反之则将该点划分至背景区域内;
[0048]
需要说明的是,
[0049]
置信度的获取可以直接采用现有技术实现,因此在此不做赘述;
[0050]
s3、构建基于vision transformer的特征提取网络,提取行人图像a和行人图像b的人体全局特征矩阵fg和人体关键点特征矩阵具体过程包括如下步骤:
[0051]
s31、将行人图像a和行人图像b分成固定大小的n个分块,通过线性映射得到n个分块特征,应用划分区域的方法(即应用上述的s2、s21以及s22叙述的内容)将每个分块特征分入对应的人体关键点区域内,比如:将行人图像调整大小至(256,128),256和128均代表像素点的个数,将图像分成固定大小的128个分块,通过线性映射得到128个分块特征,然后根据划分区域的方法,将每个分块特征分入对应区域;
[0052]
s32、创建1个全局令牌和k个关键点令牌,将1个全局令牌、k个关键点令牌、的n个分块特征拼接得到长度为1+k+n的输入序列,将输入序列送入vision transformer的编码器中;
[0053]
s33、在vision transformer的编码器上构建多头自注意力的计算公式,该公式为:
[0054][0055]
上式中q为查询向量,k为关键向量,v为值向量,d为查询向量的维度,softmax()为softmax函数;
[0056]
s34、将全局令牌和所有分块特征映射到q、k、v对应的空间内,进行多头注意力计算,计算后输出的cls token即是人体全局特征矩阵fg;
[0057]
s35、将关键点令牌和与关键点令牌对应的关键点区域内的分块特征映射到q、k、v对应的空间内,进行多头注意力计算,计算后输出的cls token即是人体关键点特征矩阵
[0058]
s4、计算人体全局特征距离和k个人体关键点特征距离,并对人体全局特征距离和关键点特征距离进行加权平均获取行人图像间的特征距离,将行人图像间的特征距离与事先设定的特征距离阈值进行对比,判断两个行人图像间的全局特征和人体关键点特征之间是否匹配,假设给定行人图像a和行人图像b,其行人图像a和行人图像b之间的特征距离计算公式为:
[0059][0060]
上式中d()为余弦距离,f
a,g
和f
b,g
分别为行人图像组中行人图像a和行人图像b的
人体全局特征矩阵,和分别为行人图像a和行人图像b的第i个人体关键点特征矩阵,和分别为行人图像a和行人图像b第i个关键点区域内的最高置信度,λg和λk为权重因子。
[0061]
s3中基于vision transformer的特征提取网络应用了三元组损失函数和分类损失函数优化模型,基于三元组损失函数和分类损失函数调整基于vision transformer的特征提取网络的参数,不断的优化基于vision transformer的特征提取网络提取的人体全局特征矩阵和人体关键点特征矩阵,三元组损失函数和分类损失函数优化模型中的损失函数的计算公式包括:
[0062]
人体关键点特征的三元组损失的计算公式:
[0063]
人体关键点特征的分类损失的计算公式:
[0064]
三元组损失函数和分类损失函数优化模型最终的损失函数:三元组损失函数和分类损失函数优化模型最终的损失函数:
[0065]
上式中
[0066]
d(a,p)和d(a,n)分别为锚样本与正样本的特征之间的距离,m为基于vision transformer的特征提取网络的参数;
[0067]
n为样本类别数,zi为输出的分类概率;
[0068]
和分别为人体全局特征的三元组损失和分类损失,和为第i个人体关键点特征的三元组损失和分类损失,λ’g
和λ’k
为权重因子。
[0069]
上述三元组损失函数和分类损失函数优化模型采用的是常用的pk采样和hard mining深度学习难分样本挖掘技术,对于一个批次内的样本(每个批次中包括p个人,每个人k
′
张图,共p*k
′
个样本,p和k
′
的取值可以根据需求设定),对于每一张图做锚样本时,选择与其距离最近的不同id的图作为负样本,选择与其距离最远的相同id的图作为正样本,相同的人的不同的图片设置相同的id,不同的人的图片设置不同的id。
[0070]
在一些具体的实现方式中,
[0071]
人体关键点的数量k取值为14,14个人体关键点包括左右手肘、左右手腕、左右肩膀、头、脖子、左右脚踝、左右膝盖以及左右臀。
[0072]
在一些具体的实现方式中,预先设定姿态估计网络hr-net中设置置信度的阈值δ为0.5。
[0073]
在一些具体的实现方式中,三元组损失函数和分类损失函数优化模型的权重因子λ’g
和λ’k
的取值可分别设置为0.5和
[0074]
查询向量的维度d取值为768;
[0075]
人体全局特征距离和关键点特征距离进行加权平均时的权重因子λg和λk分别为1和
[0076]
比如:将上述的基于姿态估计和transformer的遮挡行人重识别方法应用于存储有多张图片的图库中进行重识别检索,输入一张或指定图库中的一张图片作为基准行人图片,应用上述的基于姿态估计和transformer的遮挡行人重识别方法将图库中的图片与基准行人图片进行重识别,获取与基准行人图片相匹配的图片,并将匹配成功的图片中与基准行人图片之间的特征距离最近的10张图片输出,形成图2所示的结果。
[0077]
在遮挡行人重识别occlude-duke、occluded-reid、partial-reid数据集上应用baseline(现有的行人重识别的基准方法,比如使用发表在iccv2021的transreid:transformer-based object re-identification采用标准vision transformer base为骨干网络,得到的结果)和ours(本发明中叙述的基于姿态估计和transformer的遮挡行人重识别方法)进行识别对比实验,实验数据如下表1所示:
[0078]
表1在occlude-duke,occluded-reid,partial-reid数据集上的实验
[0079][0080]
综上所述,使用本发明提出的方法,在遮挡行人重识别occlude-duke,occluded-reid,partial-reid数据集上分别可以达到66.1,73.4,75.0的rank-1值和57.1,69.4,72.1的map值,有效提高了遮挡行人重识别的精度。
[0081]
在一些具体的实现方式中提出一种处理装置,其包括处理器和存储模块,存储模块用于存储程序,处理器用于加载程序并执行以实现基于姿态估计和transformer的遮挡行人重识别方法。
[0082]
将基于姿态估计和transformer的遮挡行人重识别方法应用于智慧楼宇在线跨摄像头多目标追踪形成智慧楼宇在线跨摄像头多目标追踪方法,
[0083]
智慧楼宇在线跨摄像头多目标追踪方法包括如下步骤:
[0084]
a、对楼宇内监控视频进行数据采集,得到包含多个行人通过多个摄像头采集到的视频片段以及实时视频流,摄像头包括一个标准摄像头和多个对比摄像头;
[0085]
b、利用多目标追踪方法从视频片段和实时视频流中得到行人序列,提取行人重识别特征序列(即图像序列),利用聚类方法得到其代表特征作为对比行人图像;
[0086]
c、应用基于姿态估计和transformer的遮挡行人重识别方法将对比行人图像与事先给定的基准行人图像进行重识别,获取对比行人图像与基准行人图像间的特征距离,对比行人图像与基准行人图像间的特征距离小于设定的特征距离的阈值则将该对比行人图像与基准行人图像匹配成功,得到包含行人全身的矩形检测框,获取包括位置信息和外观信息的行人检测信息,进入步骤e,反之则标识匹配不成功;
[0087]
d、对于标准摄像头获取的视频流,利用所述行人检测信息,继续使用多目标追踪方法,得到与基准行人图像对应的行人轨迹,并获取行人轨迹的特征序列,实现智慧楼宇在线跨摄像头多目标追踪方法。
[0088]
上述步骤中叙述的多目标追踪方法和聚类方法等均可以直接采用现有技术实现,
因此在此不做赘述。
[0089]
对于普通技术人员来说,在不脱离本发明创造构思的前提下,还可以做出若干相似的变形和改进,这些也应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1