一种基于深度相机的速度与力量反馈系统
本发明涉及电子信息,尤其涉及一种基于深度相机的速度与力量反馈系统。
背景技术:
1、在竞技训练实践中,对竞技目标表现能力变化过程的量化分析与评估,是教练员了解训练效果、修正训练计划、科学控制训练进程的主要途径。大数据时代背景下,如何在高水平运动队运用数字化设备技术开展体能训练与监控,帮助运动员竞技目标表现能力在确定时间点上的稳定实现,是提高竞技训练科学性和精准性的重要问题。目前在高水平运动队体能训练中,数字化监控方法与手段主要集中在力量训练、速度训练、耐力训练、体能状态监控以及体能大数据管理平台的应用。体能训练是所有竞技体育项目的根基,其中速度与力量训练是其核心。但是目前针对体能训练中速度与力量的训练技术或方法要么依靠教练的视觉观察,要么依靠运动员自身的感觉不断摸索。或者是借助辅助设备譬如gymaware来对运动员训练过程中的速度与力量进行监控,但是此类设备需要依靠绳子等依附在运动员身上或者是负荷重量上,容易对运动员的运动过程造成一定的干扰。如何在不绑定任何其他设备的同时将速度与力量训练过程中产生的姿态、速度、力量、功率等核心技术指标数字化,进而对运动员日常训练进行科学化指导以提高训练效率和减少运动伤害成为教练员面临的首要难题。
技术实现思路
1、本发明的目的是为了解决现有技术中存在的缺点,而提出的一种基于深度相机的速度与力量反馈系统,通过合理的结构搭配相关算法无接触捕获运动员在体能训练过程中产生的姿态、速度、力量、功率等核心技术指标,并将其数字化,指导科学化训练。
2、为了实现上述目的,本发明采用了如下技术方案:
3、一种基于深度相机的速度与力量反馈系统,包括图像采集模块、人体捕捉模块、运动监测模块和速度和力量计算模块;
4、所述图像采集模块运用内置视觉传感器分别对运动员和运动员外部环境监测,图像采集模块可同时完成彩色图像和深度图像的采集;所述图像采集模块由两个深度相机组成,按照十字型将两个深度相机进行横竖安装固定;
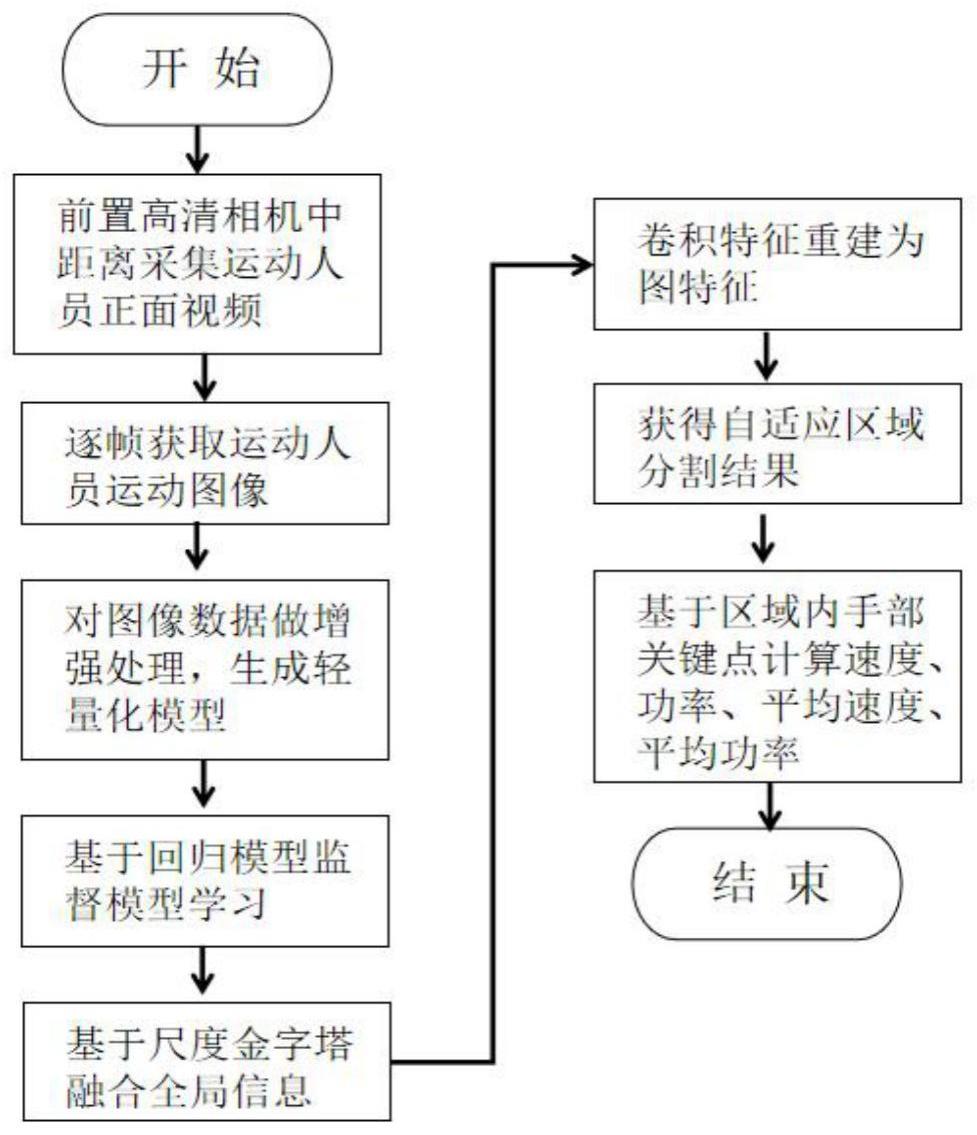
5、所述人体捕捉模块用于高效定位人体16个关键点,以exc-pose算法为核心,具体包括轻量化“e”型结构编码层和rle-decoder基于回归模型监督学习方法的解码层;
6、所述运动监测模块用于判断真伪运动,采用人体捕捉模块定位的手部关键点生成手部区域,在该区域内以exc二分类器进行真伪运动判断;
7、所述力量计算模块用于计算相关训练信息,采用多帧融合的卡尔曼滤波算法计算;
8、所述速度与力量反馈系统的具体步骤如下:
9、s1:在两台intel real sense d435高清相机所采集的彩色与深度视频中,逐帧获取带有运动员的图像,对图像进行增强处理;
10、s2:使用基于对数似然估计与回归模型的非接触式轻量级人体检测算法进行人体检测,分割出图像中人体区域;
11、s3:将检测出的人体区域,提取手部关键点的坐标值,并转换为运动技术指标如速度、功率平均速度和平均功率。
12、优选地,所述人体捕捉模块中,exc-pose算法包括目标检测和姿态检测,主要由pd-shufflenet编码层和rle-decoder解码层组成。其中pd-shufflenet通过三分之结构能够提取更加精细的底层特征,rle-decoder通过残差对数似然估计和重参数化,针对提取到的底层特征进行基于回归的模型监督学习直接回归出目标关键点的坐标值。
13、优选地,由姿态检测出的16个关键点与坐标信息,通过运动检测模块进行筛选得到的手部关键点坐标handn(xn,yn),在手部关键点的基础上逐帧生成手部自适应外接矩形区域,此区域可随着运动人员的走进或者走远而自动调整大小,始终保证杠铃位于区域内;运动检测模块在加入exc二分类器后,判断任意一帧内是否处于手持杠铃运动状态。
14、优选地,输入图像后,经过一次卷积操作和最大池化操作,然后通过由不同数量shuffle单元堆叠而成的stage2、stage3、stage4三个阶段,其中每个阶段第一个模块采用stride=2的shuffle单元来实现降采样功能,stage2和stage4均由一个stride=2的shuffle单元和3个stride=1的shuffle单元堆叠而成。本文设计的pd-shufflenet将网络分成三分支,构成“e”型结构,这些分支分别对目标底层特征进行学习。具体操作是:在stage2结束后,把stage3和stage4复制两份组成3分支“e”型结构,其中stage3-1、stage3-2、stage3-3在采用stride=2的shuffle单元后,分别继续堆叠5个、7个、9个stride=1的shuffle单元,然后接一个stage4,使网络学习不同程度的底层特征。
15、优选地,rle-decoder采用基于回归的模型监督学习方法直接学习出目标关节点的坐标。针对e-shufflenet编码层学习到的图像特征i,解码层通过回归模型来预测目标关节点出现在位置x的概率,其概率分布用pθ(x|i)来表示,其中θ表示模型学习的参数。整个监督过程就是学习优化模型参数θ使得模型预测的结果在标签μg处的概率最大。通过极大似然估计该模型的损失函数可以描述为:
16、
17、式中,lmle为损失函数,θ为优化模型参数,pθ(x|i)为概率分布,i为图像特征,μg为标签,为分布的方差,为样本均值。
18、采用了标准化流模型可以将简单分布变换为任意复杂分布,标准化流模型就将一个简单分布p(z)转化为一个可学习的函数x=fφ(z),从而来表示一个复杂的分布pφ(x),标准化流的直观展示如下:
19、
20、
21、…
22、
23、式中,p1(xi),p1(xi),...,pk-1(xi),pk(xi)表示第1次,第2次,...,第k-1,第k次变化后的分布函数,t(zi)为初始的函数,为第1次,第2次,...,第k次的变换矩阵;
24、模型变换过程中,为了使流模型拟合最优的底层分布可分为三种类型:简单分布项如高斯分布残差对数似然估计项以及常数项s,如下式所示:
25、
26、在训练过程中,不依赖于流模型,因此能够加快模型的训练过程。当训练结束时,回归模型学习到的平移缩放参数就固定了,本发明是在n(0,i)标准分布上进行变换的,在推理阶段,平移缩放系数可以直接看作是最终预测的坐标值。
27、优选地,将pd-shufflenet三个分支分别学习到人体16个关节点的坐标值所对应的置信度作为输入传递给特征聚合单元。然后进行concat操作,将这三个结果合并成一个3×16的矩阵,其中每一行代表不同分支,每一列代表该分支不同关节点坐标的置信度。然后进行split操作,即把这个矩阵案列切分成16个1×3的矩阵,其中每个矩阵代表人体姿态某一部位三种不同置信度的堆叠,如a0即三个分支学习到的头部关节点坐标的置信度。然后通过max函数输出a0,a1,a2,...,a17中最大置信度对应的关节点坐标a0,a1,a2,...,a17。最后进行concat操作即得到一个全新的人体姿态16个坐标点对应的坐标。对每个分支所产生的结果进行基于权重的智能通道集成,由于是三分支结构,集成过程公式如下式:
28、
29、式中,i代表第i通道,ts为最终集成的特征,ti为第i条通道内的待融合特征值,ci为第i条通道,ki%代表每条通道生成的特征占所有通道的比重。
30、优选地,通过姿态检测算法获得16个关节点后,定义连续帧内手部关键点hand0(x0,y0),hand1(x1,y1),hand2(x2,y2),...,handn(xn,yn),其中hand0点获取的坐标基于运动员初始运动时的手部位置,handn点获取的坐标基于运动员最终运动时刻手部关键点的位置;通过深度相机携带的视觉传感器与红外传感器,逐帧获取所记录关键点的深度值z0(x0,y0),z1(x1,y1),z2(x2,y2),...,zn(xn,yn);由于近大远小原则,基于手部的roi自适应正方形框的边长,与此时的深度值坐标呈现线性关系,可用下式方程组表示:
31、
32、式中,l0,l1,l2,...,ln表示逐帧获取基于手部的roi自适应正方形框的边长,a代表边长l与深度值的相对变化率,z0,z1,z2,...,zn代表某时刻手部关键点对应的深度值信息,b代表位置改变时造成的偏差修正量;
33、从方程组获得一组最佳匹配(a0,b0),对于任意帧内的roi自适应正方形框的边长l与其所对应的手部深度值存在关系,如下式:
34、l=a0z+b0
35、基于l的变化,灵活调整所做的roi自适应正方形的大小,实时跟踪并且捕捉杠铃杆,在捕捉到杠铃杆的基础上,引入resnet网络加入注意力机制,判断是否处于手持杠铃运动状态。
36、优选地,在手部关键点基础上加入exc二分类器,为分类模块构建一个遍历的框架用于判断是否抓住杠铃,同时使用残差块来解决图像处理过程中的退化和梯度消失问题;针对距离相机的远近将影响目标区域的大小从而影响分类网络的准确性,引入多尺度金字塔模块以改善模型对多尺度特征的提取能力尤其是小目标,扩张金字塔结构在捕获多尺度信息和高密度提取特征方面有很大的改进,体现在使用扩张率1、2、4的扩张卷积为resnet的底层创建了新的多尺度特征,其中的block模块可在多尺度金字塔模块之前通过卷积得到,对得到的3种卷积特征进行两两融合,利通道注意力机制获取任意两张组合时的彼此权重,将权重矩阵与对应的卷积特征相乘拼接后得到最终的融合特征,以提高远距离的手部分类性能。
37、优选地,通过在连续帧中逐帧所记录的基于手部关键点的深度值z0(x0,y0),z1(x1,y1),z2(x2,y2),...,zn(xn,yn),逐一展开深度筛查,设定深度上限值,并且设定深度下限值;任意时刻,某一帧基于手部关键点所获得的深度同时满足大于深度最小值zmin、小于深度最大值zmax,即可认为运动员处于合理运动区域,如下:
38、zmin≤zn(xn,yn)≤zmax
39、式中,zmin,zmax代表深度最小值和深度最大值,zn(xn,yn)代表某一帧里手部关键点的深度值,xn,yn代表某一帧里手部关键点的横、纵坐标值。
40、优选地,对图像处理模块获得的十帧图像作为一组,读取实时的高度变化,在k-1时刻,存在如下两个矩阵:最佳估计ak和协方差矩阵bk如下所示:
41、
42、
43、式中,height与velocity为此时的高度与速度,在后续的公式中使用hv指代这两个变量,∑ij表示各个向量元素之间的协方差,此处ij为pv间的任意两两组合,共4种组合方式;
44、在原始估计是正确的前提下,在k时刻时的高度与速度的测量值可通过以下公式表达出来:
45、
46、
47、式中,ak,ak-1分别代表k时刻和k-1时刻的信息,tk代表变换矩阵,δt为经过的时间;
48、考虑到测量值与预测值受外界因素的干扰,将预测值高斯分布与测量值高斯分布分别得出并相乘,即可得到最终预测的高斯分布,如下式:
49、
50、b′k=bk-k′hkbk
51、
52、ak为引入外界干扰后的最佳估计,bk为引入外界干扰后的协方差矩阵,k′为修正后的卡尔曼系数,ak′为下一时刻预测值的最佳估计,bk′为下一时刻预测值的协方差矩阵,rk为传感器测量值的均值矩阵,zk为传感器测量值的协方差矩阵,hk为测量值修正矩阵,velocity′即为下一时刻杠铃的速度,height′为下一时刻杠铃的高度。
53、与现有技术相比,本发明具有以下有益效果:
54、1、本发明将彩色图像与深度图像结合作为算法的输入,并通过算法与智能电脑进行数据处理,有效解决了训练数据的获取需要佩戴外设的问题。
55、2、本发明的训练方式是基于速度的力量训练,通过速度判断运动员的爆发力和力量,避免运动员因盲目的负荷增加而受伤。
56、3、本发明提出了自创的exc-pose姿态检测算法,在轻量化编码层的的基础上,引入基于回归模型的检测方案,同时采用本发明提出的“e”型结构搭建解码层使检测出来的姿态不仅准确,而且减少过程的计算量,提升检测速度。
57、4、本发明提出了通过人体关键点划分感兴趣区域算法,并利用多尺度金字塔加入resnet网络,形成多尺度特征,划分较远距离的感兴趣区域。
58、5、本发明采用的人体捕捉模块和运动检测模块,能够实时监测人体并记录数据,从而提高运动员的力量水平,提高在运动项目中的成绩。
59、6、本发明在一定程度上大大减少了教练的负担,可以通过传感器准确且高效地获取运动员的运动指标,极大促进了我国智慧体育的发展。
- 还没有人留言评论。精彩留言会获得点赞!