一种保持文本内容位置关系的影像生成方法
1.本发明属于临地安防,计算机视觉,人工智能,多模态学习领域,具体涉及到一种保持文本内容位置关系语义的影像生成方法。
背景技术:
2.影像作为一种重要的信息传播媒介,是人类认识世界的重要途径。计算机视觉在工程领域的应用主要通过构建采集设备与分析算法,来赋予计算机感知环境的能力,在包括智能监测、水下安防等场景的临地安防领域有广阔的应用前景。但是建立完善的智能安防体系需要大量的真实影像数据支撑,受限于采集成本,大量特定场景的影像数据很难被获取。因此,一些研究者提出使用小范围的原始影像数据应用生成技术进行数据增广,但目前的无条件生成算法仅能得到与原始影像数据特征类似的结果,无法按照人类意愿对生成影像内容进一步的控制,如何实现对生成影像内容进行有条件的精确控制是当前亟待解决的一个关键问题。相较于影像,文本是一种易获取的信息传播载体,基于文本描述信息生成包含特定内容的影像在一定程度上缓解生成影像内容不受控制的问题。然而,文字与影像间存在着语义鸿沟,如何建立起文本与影像内容间的对应关系,使得生成影像兼具真实性与语义一致性,是当前研究中面临的两个挑战。
3.为了降低文本到影像生成任务的难度,文献“t.xu,p.zhang,q.huang,h.zhang,z.gan,x.huang,and x.he,attngan:fine-grained text to image generation with attentional generative adversarial networks,ieee conference on computer vision and pattern recognition,1316-1324,2018.”将基于文本内容生成影像的实现过程拆分为两个部分。首先,使用深度注意力机制多模态相似度模型理解并学习文本语义与影像特征的对应关系;其次,将学习到的语义信息输入到多阶段的对抗生成网络中以逐级提升生成影像的分辨率。该方法相较于采用单一阶段的生成模型有效地增强了生成影像的质量,同时改善了模型训练过程的稳定性。
4.为了增强生成影像与输入文本的语义一致性,文献“w.li,p.zhang,l.zhang,q.huang,x.he,s.lyu,and j.gao,object-driven text-to-image synthesis via adversarial training,ieee conference on computer vision and pattern recognition,12174-12182,2019.”将影像的生成过程进行了不同维度的拆分。首先,使用边界框生成器与形状生成器基于给定的文本信息获得包含物体类别与位置信息的语义布局图,之后再根据全局的文本特征与局部的单词特征补充语义布局图的细节。该方法在拥有标注好的物体边界框及形状掩模的前提下生成效果较好,但在实践中仅仅使用文本进行输入生成影像仍无法完成对文本中提及的物体种类及位置关系的形象表达。
5.上述两种方法虽然都实现了从文本到影像的生成任务,但都存在一定的局限性。具体表现为对文本描述的语义表达仍旧停留在较浅的层次,上述模型仅能在生成的结果中体现出文本提及的诸如颜色、纹理、种类等表面的语义信息,其生成的影像更像是不同子区域之间的简单组合,诸如数量、位置关系等更高层次的文本语义仍无法在生成的影像内容
中得以体现。高层次语义信息在转化过程中的缺失也在很大程度上限制了文本到影像生成工作的实际应用场景,促进高层次语义信息在生成影像中的合理表达是研究者们目前面临的一大难题。
技术实现要素:
6.要解决的技术问题
7.为了克服现有文本到影像生成实践中对于文本中包含的高层语义信息表达不足的问题,本发明提出了一种保持文本内容位置关系的影像生成方法。
8.技术方案
9.一种保持文本内容位置关系的影像生成方法,其特征在于步骤如下:
10.步骤1:对训练数据进行重新组织
11.1a:对训练数据中的物体位置信息与文本内容进行对齐;
12.1b:对未包含位置关系文本描述的训练数据进行蒸馏处理;
13.1c:对语义图中包含的物体位置信息进行建模,粗糙语义图布局中物体的描述信息有两部分组成,分别是确定放置位置的影像坐标信息及体现物体群体属性的类别信息;如公式(1)所示,通过一个四维向量b
t
来代表序号为t的物体在影像上的位置,其中b
t,x
,b
t,y
分别代表物体在二维影像上以左上角为原点的水平与垂直像素坐标,b
t,w
,b
t,h
分别代表位置框在二维影像上的像素长度及宽度;如公式(2)所示,l
t
是一个采用独热编码的l+1维向量,其元素由0或1组成,且只有一位数字为1,其余全为0,1的位置代表该向量代表的类别,l代表数据集中的物体种类数量,l+1类编码被设置为终止符作为单张影像类别序列的终止符号;如公式(3)所示,两个向量组成的约束信息b
t
可以唯一确定序号为t的物体在语义布局图上的位置;
14.b
t
=[b
t,x
,b
t,y
,b
t,w
,b
t,h
].
ꢀꢀꢀ
(1)
[0015]
l
t
∈{0,1}
l+1
.
ꢀꢀꢀ
(2)
[0016]bt
=(b
t
,l
t
).
ꢀꢀꢀ
(3)
[0017]
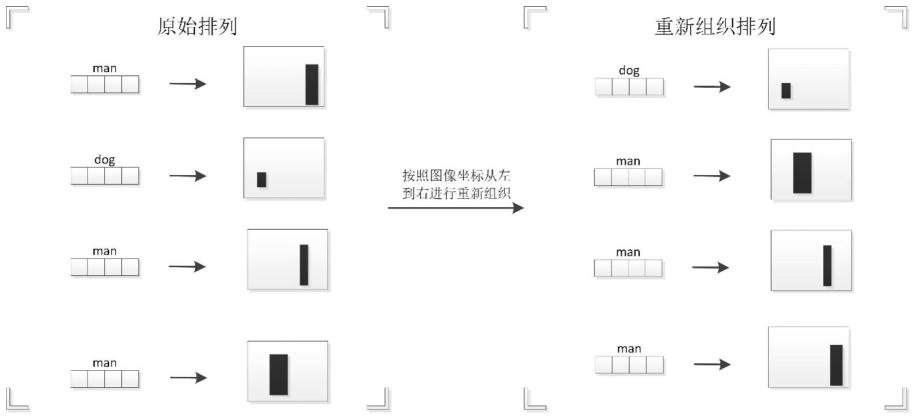
1d:对每张影像中的物体输入预测模型的顺序按照一定规则进行重新排布;所述的排布规则如下:根据标注好的位置框信息计算物体的中心点坐标,按照影像二维平面坐标从左到右,进行递增排布,得出具有位置关系临近依赖的物体位置信息;
[0018]
步骤2:训练保持位置关系语义的物体布局生成模块
[0019]
2a:构建保持位置关系语义的物体布局生成模块,该模块的作用为根据输入的文本约束生成一组体现位置关系语义的物体位置信息列表;模块的处理过程如公式(4)所示,输入为256维的文本特征向量s,由一个预先训练的长短期记忆网络完成对输入自然语言描述的特征提取,g
box
代表一个双向长短期记忆网络;假设每张影像中包含序号1-t的物体,物体布局生成模块需要根据文本特征生成序号为1-t的位置约束信息如公式(5)所示,基于lstm的性质,每个单元的输出取决于前一个单元的输出状态与当前单元的输入,序号t的物体的位置约束信息b
t
的生成依赖于前t-1次生成的位置约束信息b
1:t-1
和文本特征s;序号1-t物体的位置约束信息b
1:t
针对文本特征s的条件概率分布p(b
1:t
∣s)可以分解为前t-1次
生成概率分布的连乘
[0020][0021][0022]
2b:表示序号为t的物体种类信息的向量l
t
与表示位置信息约束的向量b
t
具有强依赖关系,在生成的过程中必须首先确定当前次需要生成的物体的种类信息;如公式(6)所示,在每次生成的过程中,首先从输入文本约束中采样得到一个类别标签l
t
,之后根据该类别标签预测其对应的位置信息b
t
,位置关系信息的生成被分为了两个部分,分别是类别标签的生成及对应物体位置描述的生成,两个步骤都采用lstm结构,当前阶段的生成结果依赖于上一阶段的输出,
·
代表之前所有步骤的生成结果,均使用softmax函数对结果进行归一化处理;
[0023]
p(b
t
∣
·
)=p(b
t
,l
t
∣
·
)=p(l
t
∣
·
)p(b
t
∣l
t
,
·
).
ꢀꢀꢀ
(6)
[0024]
2c:设计一种位置关系敏感的损失函数,如公式(7)所示,b
t
代表训练数据中的位置约束信息,代表布局生成模块输出的位置约束信息,代表物体根据位置约束信息计算出的中心点影像坐标,其中c
t,x
为水平方向坐标,c
t,y
为垂直方向坐标;如公式(8)所示,使用两点之间的水平方向余弦值来描述二者的平面位置关系,其中代表序号为i的物体的中心点坐标,代表序号为j的物体的中心点坐标;如公式(9)所示,代表序号为i的物体根据数据集标注信息计算得到的中心点坐标,在生成序号为t的物体位置约束信息时,损失函数的值为序号t的物体与前序生成的t-1个物体两两配对计算的水平余弦差值的平均值:
[0025][0026][0027][0028]
步骤3:将步骤1得到的训练数据输入到步骤2保持位置关系语义的物体布局生成模块,得到语义布局图,将该语义布局图输入到后序的生成模块中即可完成位置关系语义在最终生成影像内容中的表达。
[0029]
步骤1a具体为:通过对描述文本进行名词提取,以获取其包含的生成物体列表,与原始数据中标注的物体列表求交集。
[0030]
步骤1b具体为:建立位置关系字典,对文本描述进行查找筛选。
[0031]
一种计算机系统,其特征在于包括:一个或多个处理器,计算机可读存储介质,用于存储一个或多个程序,其中,当所述一个或多个程序被所述一个或多个处理器执行时,使得所述一个或多个处理器实现上述的方法。
[0032]
一种计算机可读存储介质,其特征在于存储有计算机可执行指令,所述指令在被
执行时用于实现上述的方法。
[0033]
有益效果
[0034]
本发明提出的一种保持文本内容位置关系的影像生成方法,从训练数据与损失函数两个方面来提升生成模型对于目标位置关系的保持能力,并通过构建定量评价标准验证模型的生成结果。通过在训练的不同阶段加入的位置关系约束,使生成模型对于文本内容中位置关系语义信息的表达能力有所增强,从而有助于模型从更高的语义层级理解文本内容与影像特征之间的关系,提升生成影像的内容布局合理性与语义一致性。
附图说明
[0035]
附图仅用于示出具体实施例的目的,而并不认为是对本发明的限制,在整个附图中,相同的参考符号表示相同的部件。
[0036]
图1是本发明方法针对训练数据基于位置关系进行重新组织的流程图。
[0037]
图2是本发明方法中空间敏感损失函数计算流程图。
[0038]
图3是本发明方法保持文本内容位置关系语义影像生成模型的整体框架图。
具体实施方式
[0039]
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图和实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。此外,下面描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
[0040]
本发明提供一种保持文本内容位置关系语义的影像生成方法。该方法以对抗生成网络为基础,通过在生成过程中的多个步骤引入位置关系约束保证文本中所提及的位置关系在生成的影像内容中得以完整表达。1)在数据准备方面,与现有模型对于预期生成的物体进行随机采样不同,本方法中对原始训练数据进行了语义标注信息蒸馏与位置关系整理两个操作,目的是增强训练数据中包含的位置关系语义信息;2)在训练阶段,除了对训练数据与生成结果进行概率建模规范模型训练外,还通过引入位置关系敏感的损失函数以进一步监督位置信息在生成过程中的表达;3)在验证模型效果方面,借助预先训练的目标检测模型对生成影像中表达出的物体位置关系进行量化评估,从而反映加入的位置关系约束对于影像高层语义表达的效果。
[0041]
本发明解决其技术问题所采用的技术方案是:一种保持文本内容位置关系语义的影像生成方法,包括以下部分:
[0042]
a)训练数据的组织阶段:文本相较于影像具有表达的模糊性与语义的歧义性,故在完成由文本信息到影像信息的转化过程中,我们需要分次逐步提取文本内容中的关键内容并在影像生成的每个阶段对语义信息进行监督及修正。本方法中针对原始ms coco数据集中的文本描述及目标分割标注信息进行了两个维度的重新组织。首先,通过对所有匹配数据对进行数据蒸馏,目的是增强模型对于位置信息的理解能力,减少无关信息对于模型收敛过程中的干扰。具体方法为,对并未包含位置关系描述或位置关系描述模糊的文本-影像匹配对进行了剔除,避免模型在训练过程中学习到错误的位置关系并其训练难度。其次,将生成任务进行拆分为生成语义布局图和生成真实影像两个部分,前者是保证位置关系信
息在后续阶段正确传播的基础。为了生成正确的语义布局图,本方法基于标注信息对模型的输入进行了重新排列,以赋予不同物体位置关系的临近依赖。
[0043]
b)模型的训练阶段:本方法将文本内容生成影像任务拆分为两个阶段。首先,根据输入文本描述生成包含位置关系信息的语义布局图;其次,将语义布局图的位置关系及物体内容进行补充及细化从而生成真实影像。通过复现其他研究者的生成模型,发现当采用原始训练数据中的语义布局信息进行影像生成时,往往可以获得内容清晰、物体排布合理的影像结果,可见获得正确的语义布局信息对于最终生成效果的重大影响。为了提高布局图中文本位置关系语义表达的合理性,本发明在模型的训练阶段引入一种空间关系敏感的损失函数,通过约束生成结果与训练数据中不同目标之间的位置关系来保持位置关系在转化过程中的表达。具体方法为,最小化两个目标在生成结果与训练数据的余弦夹角差值以帮助模型学习文本内容中体现空间关联语义。之后将位置关系增强后的语义关系图输入到影像细化生成模块中,完成文本语义在真实影像内容中的表达。
[0044]
c)模型的评价阶段:借助预先训练的目标检测模型对生成影像进行处理以获得影像中包含的目标种类及目标之间的位置关系。将提取结果与数据集中的标注信息进行比较,计算成功表达的位置关系语义信息的比例,完成对模型位置关系语义信息转化能力的定量评价。
[0045]
为了使本领域技术人员更好地理解本发明,下面结合具体实施例对本发明进行详细说明。
[0046]
参照图1,对训练数据进行重新组织的流程如下:
[0047]
步骤0:对训练数据中的物体位置信息与文本内容进行对齐,目的是去除文本描述中未提及物体的位置信息,增强标注信息与文本语义的一致性。具体方法为,通过对描述文本进行名词提取,以获取其包含的生成物体列表,与原始数据中标注的物体列表求交集。
[0048]
步骤1:对未包含位置关系文本描述的训练数据进行蒸馏处理,目的是增强模型对于位置关系的学习能力。具体做法为建立常用位置关系字典,对文本描述进行查找筛选。
[0049]
步骤2:对语义图中包含的物体位置信息进行建模,粗糙语义图布局中物体的描述信息主要有两部分组成,分别是确定放置位置的影像坐标信息及体现物体群体属性的类别信息。如公式(1)所示,以序号为t的物体为例,我们通过一个四维向量b
t
来代表其在影像上的位置,其中b
t,x
,b
t,y
分别代表物体在二维影像上以左上角为原点的水平与垂直像素坐标,b
t,w
,b
t,h
分别代表位置框在二维影像上的像素长度及宽度。如公式(2)所示,l
t
是一个采用独热编码的l+1维向量,其元素由0或1组成,且只有一位数字为1,其余全为0,1的位置代表该向量代表的类别,l代表数据集中的物体种类数量,l+1类编码被设置为终止符作为单张影像类别序列的终止符号。如公式(3)所示,两个向量组成的约束信息b
t
可以唯一确定序号为t的物体在语义布局图上的位置。
[0050]bt
=[b
t,x
,b
t,y
,b
t,w
,b
t,h
].
ꢀꢀꢀ
(1)
[0051]
l
t
∈{0,1}
l+1
.
ꢀꢀꢀ
(2)
[0052]bt
=(b
t
,l
t
).
ꢀꢀꢀ
(3)
[0053]
步骤3:位置信息的原始标注信息是随机分布的,不含物体之间的相互关系依赖,导致生成的结果忽略了物体之间的位置关系排布。为了赋予不同目标位置关系的临近依赖,本方法对每张影像中的物体输入预测模型的顺序按照一定规则进行重新排布。排布规
则如下:根据标注好的位置框信息计算物体的中心点坐标,按照影像二维平面坐标从左到右,进行递增排布,得出具有位置关系临近依赖的物体位置信息。
[0054]
参照图2,保持位置关系语义的物体布局生成模块的训练过程如下
[0055]
步骤0:构建保持位置关系语义的物体布局生成模块,该模块的作用为根据输入的文本约束生成一组体现位置关系语义的物体位置信息列表。模块的处理过程如公式(4)所示,输入为256维的文本特征向量s,由一个预先训练的长短期记忆网络(lstm,long short-term memory)完成对输入自然语言描述的特征提取,g
box
代表一个双向长短期记忆网络(bi-lstm,bi-directional long short-term memory)。假设每张影像中包含序号1-t的物体,物体布局生成模块需要根据文本特征生成序号为1-t的位置约束信息如公式(5)所示,基于lstm的性质,每个单元的输出取决于前一个单元的输出状态与当前单元的输入,序号t的物体的位置约束信息b
t
的生成依赖于前t-1次生成的位置约束信息b
1:t-1
和文本特征s。序号1-t物体的位置约束信息b
1:t
针对文本特征s的条件概率分布p(b
1:t
∣s)可以分解为前t-1次生成概率分布的连乘
[0056][0057][0058]
步骤1:表示序号为t的物体种类信息的向量l
t
与表示位置信息约束的向量b
t
具有强依赖关系,在生成的过程中必须首先确定当前次需要生成的物体的种类信息。如公式(6)所示,在每次生成的过程中,首先从输入文本约束中采样得到一个类别标签l
t
,之后根据该类别标签预测其对应的位置信息b
t
,位置关系信息的生成被分为了两个部分,分别是类别标签的生成及对应物体位置描述的生成,两个步骤都采用lstm结构,当前阶段的生成结果依赖于上一阶段的输出,
·
代表之前所有步骤的生成结果,均使用softmax函数对结果进行归一化处理。
[0059]
p(b
t
∣
·
)=p(b
t
,l
t
∣
·
)=p(l
t
∣
·
)p(b
t
∣l
t
,
·
).
ꢀꢀꢀ
(6)
[0060]
步骤2:为了保证物体布局生成模块生成结果不仅符合训练数据的条件概率分布,同时还体现出输入文本描述中的位置关系语义,本方法在原有目标函数的基础上加入了一种位置关系敏感的损失函数。如公式(7)所示,以序号为t的物体为例,b
t
代表训练数据中的位置约束信息,代表布局生成模块输出的位置约束信息,代表物体根据位置约束信息计算出的中心点影像坐标,其中c
t,x
为水平方向坐标,c
t,y
为垂直方向坐标。如公式(8)所示,本方法中使用两点之间的水平方向余弦值来描述二者的平面位置关系,其中代表序号为i的物体的中心点坐标,代表序号为j的物体的中心点坐标。如公式(9)所示,代表序号为i的物体根据数据集标注信息计算得到的中心点坐标,在生成序号为t的物体位置约束信息时,损失函数的值为序号t的物体与前序生成的t-1个物体两两配对计算的水平余弦差值的平均值。
[0061]
[0062][0063][0064]
参照图3,构建后续生成模块将语义布局图细化为真实影像,之后定量地评价模型的位置关系语义的表达效果。
[0065]
步骤0:在获取包含位置信息的目标列表后,即可得到期望生成影像中包含目标物体之间的位置关系并构建相应的语义布局图,将该语义布局图输入到后序的生成模块中即可完成位置关系语义在最终生成影像内容中的表达。后序的生成模型结构根据文献“s.hong,d.yang,j.choi,and h.lee,inferring semantic layout for hierarchical text-to-image synthesis,in ieee conference on computer vision and pattern recognition,pp.7986-7994,2018.”进行构建,最终将生成的语义布局图进行补充细化得到真实影像。
[0066]
步骤1:根据文献“t.hinz,s.heinrich,and s.wermter,semantic object accuracy for generative text-to-image synthesis,ieee transactions on pattern analysis and machine intelligence,vol.44,no.3,pp.1552-1565,2022.”提出的对于生成影像中物体种类的评价方法,构建描述文本中位置关系语义定量的评价方法。使用预先训练的目标检测模型yolov3检测生成影像中包含的目标,并将目标列表中的元素进行两两配对,判断其位置关系是否与训练数据的位置关系相同,最终计算位置关系表达的准确率(slra,semantic location relationship accuracy)。计算过程如公式(10)与公式(11)所示,其中n代表目标检测模型检测出的目标数量,代表生成结果中物体i与物体j之间的位置关系,r
i,j
代表数据集中物体i与j之间的位置关系,若二者的位置关系相同,则为1,否则为0。
[0067][0068][0069]
为了详细说明本发明的具体实施方式,接下来以影像数据集ms coco为例进行说明。该数据集被应用于目标检测、分割、影像描述等多个应用场景,其中包含100000余张标注影像,其中训练集包含影像118287张,测试集40670张,验证集5000张。数据集共包含80个目标类别,每张影像的标注信息包括对象级别的实例分割以及类别标签,同时还包含5段不同角度的文字描述。本发明中,使用原始数据划分中的118287张影像与其对应标注信息作为训练数据,之后采用5000张图片及标注信息进行测试验证模型效果。
[0070]
步骤0:根据提取到的文本内容中的名词列表对原始标注数据进行对齐,保留文本中提及物体的位置框信息。原始数据集共包含410622组数据,经过对齐后得到209554组训练数据;
[0071]
步骤1:根据位置关系对原始数据进行数据蒸馏,将描述文本进行分词后进行方位词提取,候选方位词包含above,below,left,right,on,over,under,between,in front of,next to,near等。蒸馏后得到包含位置关系方位词描述的训练数据161697组。
[0072]
步骤2:根据文本描述与物体位置描述信息匹配对进行语义布局信息生成模型训练,并引入位置敏感的位置关系损失函数帮助模型收敛。
[0073]
步骤3:根据文献“s.hong,d.yang,j.choi,and h.lee,inferring semantic layout for hierarchical text-to-image synthesis,in ieee conference on computer vision and pattern recognition,pp.7986-7994,2018.”中提出的生成模型最终将语义布局图转化为真实影像。
[0074]
步骤4:在模型的训练阶段完成后,使用测试集中的描述文本对模型的生成效果进行测试。对于模型生成结果进行两方面的评价,分别是生成影像的质量评价与生成影像与描述文本的语义一致性评价。针对影像生成的质量评价主要通过计算其is指标来实现,该评价方法主要通过考察生成影像中目标的类别可区分度实现。针对生成影像语义一致性的评价主要通过本发明中提出的计算位置关系表达准确率来实现。在具体实施时,由于目前模型对于高层语义的表达能力仍较差,有些位置关系对于二维影像较难判断,故在构建评价体系时使用上方、下方、左侧、右侧四种较为简单的位置关系。最终结合上述两种评价指标验证本发明提出方法对于改善文本到影像生成质量的提升及位置关系语义表达的改进效果。
[0075]
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明公开的技术范围内,可轻易想到各种等效的修改或替换,这些修改或替换都应涵盖在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1