一种基于存内CNN中间缓存调度的存储器的制作方法
一种基于存内cnn中间缓存调度的存储器
技术领域
1.本发明涉及复用cnn调度运算技术领域,尤其涉及一种基于存内cnn中间缓存调度的存储器。
背景技术:
2.大数据时代下,现有的计算结构在面对数据密集型的应用时,会因为大量的数据搬运和带宽的限制带来能耗和延迟上的提高,使得数据上的向量并行受制于存储器读写带宽。为了解决访存和数据搬运造成的能耗和延迟,存内计算突破了传统冯诺依曼瓶颈,实现了存储单元与逻辑单元的融合,是实现智能计算的主要技术路线之一。学界提出了基于sram的算术逻辑运算电路,在存储器中实现算术逻辑运算。现有基于sram的算术逻辑运算电路因为计算模式比较单一,在面对外界输入和存储单元之间运算的场景时,电路的性能会受到限制,当前的存内计算技术主要面临着硬件资源复用等问题。
3.卷积神经网络是一种带有卷积结构的深度神经网络,卷积结构可以减少深层网络占用的内存量,也可以减少网络的参数个数,缓解模型的过拟合问题。卷积核是卷积层的重要组成部分。特征提取器是卷积核的本质,其主要作用是自动提取输入信号的深层信息。卷积层由多个特征面组成,每个特征面由多个神经元组成,它的每一个神经元通过卷积核与上一层特征面的局部区域相连。上一层的特征图被一个可学习的卷积核进行卷积,然后通过一个激活函数,就可以得到输出特征图。每个神经元局部连接上一层的神经元,并且共享权值,然后输出数据里的每个神经元通过共享权重去卷积图像后再加上共享偏置得到的,如果没有用共享权值,那么一个神经元需要对应一个卷积核一个偏置,而现在是每个神经元对应的是同一个卷积核同一个偏置,使得参数量大幅下降,适合于存内的数据复用。现有的数据搬运是在逻辑运算单元与存储单元之间,大量的数据搬运和带宽的限制带来能耗和延迟上的提高,使得数据上的向量并行受制于存储器读写带宽。
技术实现要素:
4.鉴于上述的分析,本发明实施例旨在提供一种基于存内cnn中间缓存调度的存储器,用以解决现有访存和数据搬运造成的能耗和延迟的问题。
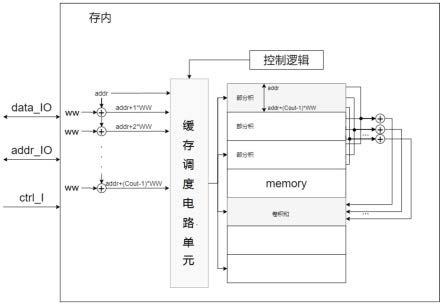
5.一方面,本发明实施例提供了一种基于存内cnn中间缓存调度的存储器,包括控制逻辑单元、缓存调度电路单元和memory存储模块;所述缓存调度电路单元包括运算逻辑单元、第一加法器、选择器和中间fifo缓存单元;
6.所述控制逻辑单元,用于根据时钟信号和外部输入的有效标志信号输出选择信号和使能信号;
7.所述运算逻辑单元,用于对输入数组的元素和卷积核的权重进行卷积运算,输出对应的卷积结果至选择器;
8.所述第一加法器,用于基于使能信号,对所述卷积结果和所述中间fifo缓存单元输出的数据进行加和,输出加和结果至选择器或基于使能取反信号输出加和结果至所述
memory存储模块;
9.所述选择器,用于基于所述选择信号,选择输出所述卷积结果或所述加和结果;
10.所述中间fifo缓存单元,用于根据所述使能信号选择是否将选择器输出的数据写入所述中间fifo缓存单元以及选择是否输出所存储的数据;
11.所述memory存储模块,用于根据外部指令信号和存储地址存储并计算经第一加法器输出的所述加和结果。
12.进一步的,所述memory存储模块包括memory存储单元、第三加法器和临时缓存区;
13.所述memory存储单元,包括n部分,每部分存储的部分积是一行元素卷积结果,用于根据所述外部指令信号和存储地址存储或读取部分积;其中卷积核大小为n*n;
14.所述第三加法器,用于将memory存储单元读取的部分积对应卷积结果进行相加得到完整卷积结果并存入临时缓存区中。
15.进一步的,所述第三加法器和临时缓存区的数量与卷积核数量一致,均有cout个,每个第三加法器对对应卷积核的每一部分卷积结果进行相加存入对应临时缓存区中。
16.进一步的,所述外部指令信号包括memory读指令信号memory-rd和memory写指令信号memory-wr;
17.当memory-rd=1,memory-wr=0时,memory存储单元按顺序分别读取元素与每一个卷积核卷积后的n部分数据至第三加法器;经第三加法器做加和运算输入至对应临时缓存区;
18.当memory-rd=0,memory-wr=1时,临时缓存区中的数据存储至memory中;
19.当memory-rd=0,memory-wr=0时,memory存储单元不操作。
20.进一步的,当所述缓存调度电路进行n*n卷积核大小的运算,所述中间fifo缓存单元的存储大小为n。
21.进一步的,所述使能信号包括fifo读使能信号和fifo写使能信号;
22.fifo读使能信号用于控制中间fifo缓存单元读出数据;
23.fifo写使能信号用于控制中间fifo缓存单元写入数据或输出至中间缓存调度电路单元的输出端。
24.进一步的,设置选择信号为sel,fifo读使能信号为rd_en,fifo写使能信号为wr_en;当用于进行3*3大小卷积核的运算,有效标志信号为1时,控制逻辑单元输出的选择信号和使能信号包括三个阶段:
25.起始阶段:第一周期:sel=0,rd_en=0,wr_en=1;
26.第二周期:sel=1,rd_en=1,wr_en=1;
27.第三周期:sel=0,rd_en=0,wr_en=1;
28.循环阶段:第四周期:sel=0,rd_en=1,wr_en=0;
29.第五周期:sel=1,rd_en=1,wr_en=1;
30.第六周期:sel=0,rd_en=0,wr_en=1;
31.…
32.结束阶段:最后一个周期:sel=0,rd_en=1,wr_en=0;
33.进一步的,所述数据选择信号sel为0时,控制选择器选择卷积结果到中间fifo缓存单元,所述数据选择信号sel为1时,控制选择器选择卷积结果和中间fifo缓存单元中最
前面的数据之和到中间fifo缓存单元;
34.所述fifo读使能信号rd_en为1时,中间fifo缓存单元进行一次读操作,将中间fifo缓存单元最前面的数据输出至第一加法器,使卷积结果和该读取数据经加法器输入至选择器,fifo读使能信号rd_en为0时,中间fifo缓存单元不读取;
35.所述fifo写使能信号wr_en为1时,中间fifo缓存单元进行一次写操作,将输入的数据写入到中间fifo缓存单元最后,fifo写使能信号wr_en为0时,中间fifo缓存单元不写入,此时写使能取反~wr_en=1有效,标志第一加法器输出结果至缓存调度电路单元的输出端有效,即第一加法器输出结果至memory存储模块。
36.进一步的,所述卷积核的数量为1个,第三加法器数量为1个,临时缓存区数量为1个,所述memory存储单元有3个部分积,memory存储单元按顺序存储中间缓存调度电路单元输出端输出的各个运算周期的计算结果datah;根据memory读指令信号,memory存储单元分别读取每部分中对应元素的部分积到临时缓存区,根据memory写指令信号,memory存储单元将临时缓存区中的数据写回memory存储单元;其中,h为运算周期的序数;在每个运算周期里包括三组相邻元素对应卷积的卷积结果和。
37.进一步的,所述中间缓存调度电路单元的数量为3个,卷积核的数量为cout个;第三加法器和临时缓存区数量均为cout个,3个所述中间缓存调度电路单元的输入端分别输入卷积核的三行权重以及均输入第一行的元素,3个所述中间缓存调度电路单元并行完成,并由对应的输出端依次输出对应的各个运算周期的计算结果datah1、datah2、datah3;所述计算结果datah1、datah2、datah3分别存入memory存储单元的3个部分积,并根据卷积核序数顺序排列,根据memory读指令信号,memory存储单元分别读取每个卷积核每部分中对应元素的部分积到对应临时缓存区;根据memory写指令信号和存储地址,memory存储单元将临时存储中的数据写回memory存储单元;其中,1-3为中间缓存调度电路单元的序数。
38.与现有技术相比,本发明至少可实现如下有益效果之一:
39.1、本技术基于存内向量处理单元的形式,部分卷积运算过程在memory中进行,减少了存储单元与外部计算之间的总线,节省了memory和处理器之间的总线带宽,且带宽并不会对内部的并行计算带来限制,在中间缓存调度电路装置中可以充分利用卷积向量的可配置性,通过在多个周期实现对任意长度参数的卷积支持。
40.2、简化了中间缓存的调度逻辑,通过先入先出的fifo策略与简单的循环逻辑控制,减少了采用sram或者寄存器堆当作中间缓存的控制复杂度。
41.本发明中,上述各技术方案之间还可以相互组合,以实现更多的优选组合方案。本发明的其他特征和优点将在随后的说明书中阐述,并且,部分优点可从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过说明书以及附图中所特别指出的内容中来实现和获得。
附图说明
42.附图仅用于示出具体实施例的目的,而并不认为是对本发明的限制,在整个附图中,相同的参考符号表示相同的部件。
43.图1为本技术存内cnn的中间缓存调度存储器整体架构图;
44.图2为本技术中间缓存电路架构图;
45.图3为卷积加速模块实现模型图;
46.图4为缓存运算逻辑计算图;
47.图5为现有的simd方式计算图;
具体实施方式
48.下面结合附图来具体描述本发明的优选实施例,其中,附图构成本技术一部分,并与本发明的实施例一起用于阐释本发明的原理,并非用于限定本发明的范围。
49.本发明的一个具体实施例,公开了一种基于存内cnn中间缓存调度的存储器,如图1和图2所示,
50.包括控制逻辑单元、缓存调度电路单元和memory存储模块;所述缓存调度电路单元包括运算逻辑单元、第一加法器、选择器和中间fifo缓存单元;
51.所述控制逻辑单元,用于根据时钟信号和外部输入的有效标志信号输出选择信号和使能信号;
52.所述运算逻辑单元,用于对输入数组的元素和卷积核的权重进行卷积运算,输出对应的卷积结果至选择器;
53.所述第一加法器,用于基于使能信号,对所述卷积结果和所述中间fifo缓存单元输出的数据进行加和,输出加和结果至选择器或基于使能取反信号输出加和结果至所述memory存储模块;
54.所述选择器,用于基于所述选择信号,选择输出所述卷积结果或所述加和结果;
55.所述中间fifo缓存单元,用于根据所述使能信号选择是否将选择器输出的数据写入所述中间fifo缓存单元以及选择是否输出所存储的数据;
56.所述memory存储模块,用于根据外部指令信号和存储地址存储并计算经第一加法器输出的所述加和结果。
57.具体的,所述中间fifo缓存单元是先入先出队列,简化了调度的策略。
58.具体的,基于存内cnn中间缓存调度的存储器其中间缓存调度电路单元和memory存储模块均在memory存内单元中;输入数组和卷积核在进入存储器中后先在中间缓存调度电路单元中进行计算,运算逻辑分为起始阶段、循环阶段和结束阶段;中间缓存调度电路单元输出的data值输入到memory存储单元,由memory存储单元进行存储并取卷积核行大小的相应列相加再存储存储于临时缓存区;即从运算逻辑单元到中间fifo缓存单元,在从中间fifo缓存单元进入memory存储单元,不用出整个memory存内单元,减小了memory存内单元和处理器之间总线带宽。
59.具体的,所述运算逻辑单元包括cin个乘法器和一个第二加法器;
60.第i个所述乘法器用于进行ai与wi的乘法运算;其中,ai为元素中的第i个值,wi为权重中的第i个值;i∈[1,cin];
[0061]
所述第二加法器,用于得到cin个所述乘法器输出结果的加和,将所述加和结果作为对应的卷积结果输出。
[0062]
具体的,如图4所示,根据缓存运算逻辑确定输入运算逻辑单元的元素和卷积核的权重;所述有效标志信号用于控制运算逻辑单元是否写入元素、卷积核的权重;所述有效标志信号为0时,不写入,为1时写入。
[0063]
具体的,缓存运算逻辑是为了减少输入数组中元素a的搬移,选择使用一个中间fifo缓存单元,单边变化卷积核权重w,进而得到输入数组的一行元素与卷积核的一行权重的卷积结果。
[0064]
具体的,以缓存运算逻辑输入元素和权重的规律为:
[0065]
第一周期输入值:第一行第一列元素和第一行第一列权重;
[0066]
第二周期输入值:第一行第二列元素和第一行第二列权重;
[0067]
第三周期输入值:第一行第二列元素和第一行第一列权重;
[0068]
第四周期输入值:第一行第三列元素和第一行第三列权重;
[0069]
第五周期输入值:第一行第三列元素和第一行第二列权重;
[0070]
第六周期输入值:第一行第三列元素和第一行第一列权重;
[0071]
……
[0072]
倒数第三周期输入值:第一行倒数第二列元素和第一行第三列权重;
[0073]
倒数第二周期输入值:第一行倒数第二列元素和第一行第二列权重;
[0074]
倒数第一周期输入值:第一行倒数第一列元素和第一行第三列权重;
[0075]
从第七周期开始,每隔3个周期元素输入值向右移动一个,权重以第四周期到第六周期的输入方式为一个循环。
[0076]
具体的,所述缓存运算逻辑包括按行依次调取输入数组中的每一列元素,并根据该元素与卷积核的移动关系,得到该元素对应的若干卷积结果;其中,卷积核的每一个元素为权重。
[0077]
具体的,所述一个逻辑运算单元的输入和卷积结果输出表示为:
[0078][0079]
其中,a为一个元素,w为一个权重。
[0080]
进一步的,当所述缓存调度电路进行n*n卷积核大小的运算,所述中间fifo缓存单元的存储大小为n。
[0081]
进一步的,所述使能信号包括fifo读使能信号和fifo写使能信号;
[0082]
fifo读使能信号用于控制中间fifo缓存单元读出数据;
[0083]
fifo写使能信号用于控制中间fifo缓存单元写入数据或输出至中间缓存调度电路单元的输出端。
[0084]
进一步的,设置选择信号为sel,fifo读使能信号为rd_en,fifo写使能信号为wr_en;当用于进行3*3大小卷积核的运算,有效标志信号为1时,控制逻辑单元输出的选择信号和使能信号包括三个阶段:
[0085]
起始阶段:第一周期:sel=0,rd_en=0,wr_en=1;
[0086]
第二周期:sel=1,rd_en=1,wr_en=1;
[0087]
第三周期:sel=0,rd_en=0,wr_en=1;
[0088]
循环阶段:第四周期:sel=0,rd_en=1,wr_en=0;
[0089]
第五周期:sel=1,rd_en=1,wr_en=1;
[0090]
第六周期:sel=0,rd_en=0,wr_en=1;
[0091]
…
[0092]
结束阶段:最后一个周期:sel=0,rd_en=1,wr_en=0;
[0093]
循环阶段的控制信号以第四周期到第六周期为一个循环。
[0094]
进一步的,所述数据选择信号sel为0时,控制选择器选择卷积结果到中间fifo缓存单元,所述数据选择信号sel为1时,控制选择器选择卷积结果和中间fifo缓存单元中最前面的数据之和到中间fifo缓存单元;
[0095]
所述fifo读使能信号rd_en为1时,中间fifo缓存单元进行一次读操作,将中间fifo缓存单元最前面的数据输出至第一加法器,使卷积结果和该读取数据经加法器输入至选择器,fifo读使能信号rd_en为0时,中间fifo缓存单元不读取;
[0096]
所述fifo写使能信号wr_en为1时,中间fifo缓存单元进行一次写操作,将输入的数据写入到中间fifo缓存单元最后,fifo写使能信号wr_en为0时,中间fifo缓存单元不写入,此时写使能取反~wr_en=1有效,标志第一加法器输出结果至缓存调度电路单元的输出端有效,即第一加法器输出结果至memory存储模块。
[0097]
具体的,控制逻辑单元输出的选择信号和使能信号控制选择器和中间fifo缓存单元的具体情况为:
[0098]
起始阶段:第一周期:sel=0,rd_en=0,wr_en=1,~wr_en=0;此时,所述运算逻辑单元输出卷积结果
①
,经选择器选择,并写入中间fifo缓存单元;
[0099]
第二周期:sel=1,rd_en=1,wr_en=1,~wr_en=0;此时,所述运算逻辑单元输出卷积结果
②
输入所述第一加法器,所述中间fifo缓存单元读出存储的数据
①
和卷积结果
②
经所述第一加法器加和输出
①
+
②
至所述选择器,所述选择器选择加和结果
①
+
②
,所述中间fifo缓存单元写入加和结果
①
+
②
;
[0100]
第三周期:sel=0,rd_en=0,wr_en=1,~wr_en=0;此时,所述运算逻辑单元输出的卷积结果
③
经选择器选择,并写入中间fifo缓存单元;
[0101]
循环阶段:第四周期:sel=0,rd_en=1,wr_en=0,~wr_en=1;此时,所述运算逻辑单元输出的卷积结果
④
输入第一加法器,所述中间fifo缓存单元读出存储的数据
①
+
②
和卷积结果
④
经所述第一加法器加和输出
①
+
②
+
④
至所述缓存调度电路单元的输出端;
[0102]
第五周期:sel=1,rd_en=1,wr_en=1,~wr_en=0;此时,所述运算逻辑单元输出的卷积结果
⑤
输入所述第一加法器,所述中间fifo缓存单元读出存储的数据
③
和卷积结果
⑤
经所述第一加法器加和输出
③
+
⑤
至所述选择器,所述选择器选择加和结果
③
+
⑤
,所述中间fifo缓存单元写入加和结果
③
+
⑤
;
[0103]
第六周期:sel=0,rd_en=0,wr_en=1,~wr_en=0;此时,所述运算逻辑单元输出的卷积结果
⑥
经选择器选择,并写入中间fifo缓存单元;
[0104]
…
[0105]
结束阶段:最后一个周期:sel=0,rd_en=1,wr_en=0,~wr_en=1;此时,所述运算逻辑单元输出的卷积结果
○
m输入第一加法器,所述中间fifo缓存单元读出存储的最前面数据和卷积结果
○
m经所述第一加法器加和输出最前面数据+
○
m至所述缓存调度电路单元的输出端;完成第一个行卷积;
[0106]
循环阶段的控制信号以第四周期到第六周期为一个循环。
[0107]
进一步的,所述memory存储模块包括memory存储单元、第三加法器和临时缓存区;
[0108]
所述memory存储单元,包括n部分,每部分存储的部分积是一行元素卷积结果,用
于根据所述外部指令信号和存储地址存储或读取部分积;其中卷积核大小为n*n;
[0109]
所述第三加法器,用于将memory存储单元读取的部分积对应卷积结果进行相加得到完整卷积结果并存入临时缓存区中。
[0110]
进一步的,所述第三加法器和临时缓存区的数量与卷积核数量一致,均有cout个,每个第三加法器对对应卷积核的每一部分卷积结果进行相加存入对应临时缓存区中。
[0111]
进一步的,所述外部指令信号包括memory读指令信号memory-rd和memory写指令信号memory-wr;
[0112]
当memory-rd=1,memory-wr=0时,memory存储单元按顺序分别读取元素与每一个卷积核卷积后的n部分数据至第三加法器;经第三加法器做加和运算输入至对应临时缓存区;
[0113]
当memory-rd=0,memory-wr=1时,临时缓存区中的数据存储至memory中;
[0114]
当memory-rd=0,memory-wr=0时,memory存储单元不操作。
[0115]
具体的,由于指令只能执行一条,不会同时出现memory-rd=1,memory-wr=1。
[0116]
具体的,存储器输入端还包括地址接口,用于接收存储地址,其中addr是第一个卷积核的部分积地址线,addr+ww是第二个卷积核的部分积地址线,addr+2ww是第三个卷积核的部分积地址线,
……
,addr+(cout-1)addr是第cout个卷积核的部分积地址线;addr0、add1、addr2分别是每个卷积核的部分积地址线;
[0117]
cout个卷积核在中间逻辑运算单元卷积后输出端输出的卷积结果卷积根据存储地址分别存入memory存储单元,
[0118]
当memory-rd=1、memory-wr=0时,memory存储单元按顺序分别读取地址为addr0、addr1、addr2的第一个卷积核(1,1)的三部分memory数据至第三加法器1,加和得到卷积核sum1并存在临时缓存区reg1里面;读取地址为addr0+ww、addr1+ww、addr2+ww的第二个卷积核(1,1)的三部分memory数据至第三加法器2,经第三加法器2加和后缓存到临时缓存区reg2里面,
……
,读取地址为addr0+(cout-1)ww、addr1+(cout-1)ww、addr2+(cout-1)ww的第cout个卷积核(1,1)的三部分memory数据至第三加法器cout,将结果缓存在临时缓存区reg_cout里面。下一次读指令中,在另外一个周期里,cout个卷积核各元素三部分同时相加;读取地址为addr0、addr1、addr2的第一个卷积核(1,2)的三部分memory数据至第三加法器1,以此类推。
[0119]
当memory-rd=0、memory-wr=1时,将临时缓存区reg1里面的数据存储到存储器memory里面。(1,1)的数据经第三加法器1加和后得到的结果在临时缓存区reg1里面,输入memory存储单元地址为此时的addr0;经第三加法器2加和后得到的结果在临时缓存区reg2里面,输入memory存储单元地址为此时的addr0+ww;
……
,经第三加法器cout加和后得到的结果在reg_cout里面,输入memory存储单元地址为此时的addr0+(cout-1)*ww。在下一个存储命令中,也就是不同的周期里,(1,2)的数据经第三加法器1加和后得到的结果在reg1里面,输入memory存储单元地址为此时的addr0,以此类推。
[0120]
当memory-rd=0、memory-wr=0时,存储器不做操作。
[0121]
其中ww为字长,一般为4byte或8byte。
[0122]
在一个可能的实施方式中,中间缓存调度电路单元的数量为1个,所述卷积核的数量为1个,第三加法器和临时缓存区数量均为1个,所述memory存储单元有3个部分积,所述
中间缓存调度电路单元分时接收各个运算周期的元素和权重,并由所述输出端依次输出各个运算周期的计算结果datah;memory存储单元按顺序存储中间缓存调度电路单元输出端输出的各个运算周期的计算结果datah;根据memory读指令信号,memory存储单元分别读取每部分中对应元素的部分积到临时缓存区,根据memory写指令信号,memory存储单元将临时缓存区中的数据写回memory存储单元;其中,h为计算周期的序数;在每个运算周期里包括三组相邻元素对应卷积的卷积结果和。
[0123]
具体的,如图1所示,中间缓存调度单路单元数量为1个时,支持存内cnn的中间缓存调度电路装置为部分复用策略;所述一个运算周期的计算结果data表示输入数组和卷积核每个步长下完整卷积结果的1/3,将该完整卷积结果输入至memory存储单元,在memory存储单元中存储;
[0124]
当输入数组中的一行元素依次调取结束后,开始输入输入数组第二行的元素和卷积核对应行的权重,并将结果依次输入memory存储单元;当三行元素均卷积结束,在memory存储单元中将对应列的数据进行加和得到输入数组与卷积核在行方向上的第一行卷积结果;
[0125]
卷积核在列方向按步长为1下移一格,根据上述方式得到输入数组与卷积核在行方向上的第二行卷积结果;以此类推。
[0126]
具体的,在采用部分复用策略时,可以复用的数据包括:
[0127]
input_map*cin*kernel_row+cin*kernel_size*cout*input_map;
[0128]
当采用3*3大小的卷积核时,可以简化成:
[0129]
input_map*cin*3+cin*9*cout*input_map;
[0130]
其中,input_map为输入数组的大小,cin为输入元素和权重的通道数,kernel_row为卷积核行,kernel_size为卷积核的大小;cout为输入数组与卷积核的输出通道数;
[0131]
在存储阶段可以复用的数据包括:
[0132]
1*1*cout*output_map*kernel_row;
[0133]
当采用3*3大小的卷积核时,可以简化成:
[0134]
cout*output_map*3;
[0135]
其中,output_map为输入数组和卷积核卷积后得到的新的数组的大小。
[0136]
在另一种可能的实施方式中,所述中间缓存调度电路单元的数量为3个,卷积核的数量为cout个;第三加法器和临时缓存区数量均为cout个;3个所述中间缓存调度电路单元的输入端分别输入卷积核的三行权重和以及均输入第一行的元素,3个所述中间缓存调度电路单元并行完成,并由对应的输出端依次输出对应的各个运算周期的计算结果datah1、datah2、datah3;所述计算结果datah1、datah2、datah3分别存入memory存储单元的3个部分积,并根据卷积核序数顺序排列,根据memory读指令信号,memory存储单元分别读取每个卷积核每部分中对应元素的部分积到对应临时缓存区;根据memory写指令信号和存储地址,memory存储单元将临时存储中的数据写回memory存储单元;其中,1-3为中间缓存调度电路单元的序数。
[0137]
具体的,中间缓存调度单路单元数量为3个时,支持存内cnn的中间缓存调度电路装置为完全复用策略;对第一行元素做卷积时,仅用到一个中间缓存调度电路单元,其输入端输入第一行元素和第一行权重;对第二行元素做卷积时,用到两个中间缓存调度电路单
元,第1个中间缓存调度电路单元的输入端输入第二行元素和第一行权重,第2个中间缓存调度电路单元的输入端输入第二行元素和第二行权重;对第三行元素做卷积时,用到三个中间缓存调度电路单元,第1个中间缓存调度电路单元的输入端输入第三行元素和第一行权重,第2个中间缓存调度电路单元的输入端输入第三行元素和第二行权重,第3个中间缓存调度电路单元的输入端输入第三行元素和第三行权重;从第三行元素开始,每一行元素同时被三个中间缓存调度电路单元分别和三行权重卷积;对倒数第二行元素做卷积时,用到2个中间缓存调度电路单元,第1个中间缓存调度电路单元的输入端输入倒数第二行元素和第三行权重,第2个中间缓存调度电路单元的输入端输入第二行元素和第二行权重;对倒数第一行元素做卷积时,仅用到一个中间缓存调度电路单元,其输入端输入倒数第一行元素和第三行权重;
[0138]
进行每一行元素的卷积时,所用到的中间缓存电路单元同时进行输出对应的各个运算周期的计算结果至memory存储单元,即同时计算输入数组的一行元素与卷积核每行权重的卷积,以后不在需要重复读取输入数组的该行元素;在memory存储单元中将对应列的数据进行加和得到输入数组与卷积核的卷积结果。
[0139]
具体的,在采用完全复用策略时,可以复用的数据包括:
[0140]
input_map*cin+cin*kernel_size*cout*input_map*kernel_row;
[0141]
当采用3*3大小的卷积核时,可以简化成:
[0142]
input_map*cin+cin*9*cout*input_map*3;
[0143]
在存储阶段可以复用的数据包括:
[0144]
1*1*cout*output_map;
[0145]
当采用3*3大小的卷积核时,可以简化成:
[0146]
cout*output_map*3。
[0147]
具体的,完全复用策略相对于部分复用策略更加完全的复用了输入数组,完全复用策略只需读取一次输入数组的行元素,减少了在计算完成后重复回来读取的取数功耗,并且并行计算能够减少在运算逻辑单元的计算时间;部分复用策略需要分多次读取输入数组的行元素,在计算完一行元素后重复回来读取行元素,相较于完全服用策略增大了读取数距的功耗;但是完全复用相对于部分复用策略也存在缺点:完全复用策略的中间fifo缓存单元大小需要kernel_size*1*1*cout,在3*3的卷积核中约等于9*cout;而部分复用策略中间fifo缓存单元大小仅需要kernel_row*1*1*cout,在3*3的卷积核中约等于3*cout;因此完全复用策略中中间fifo缓存单元的容量面积比部分复用策略增加了三倍。在具体实现中可以根据应用电路的需要在面积与功耗中间进行权衡。
[0148]
具体的,上述支持存内cnn的中间缓存调度电路装置中仅描述了一个卷积核与输入数组的卷积缓存装置,实际应用中不局限于一个卷积核,如图1和图2所示,多个卷积核可共享一个输入数组,当有cout个卷积核时,输入数组和cout个卷积核的输出通道为cout,即有cout个中间缓存调度电路装置。
[0149]
具体的,输入数组的大小为input_col*incup_row*cin,卷积核大小为kernel_row*kernel_rcol*cin,cout个卷积核共享1个输入数组,得到新的数组为output_col*outcup_row*cout。
[0150]
与现有技术相比,本实施例提供的调度方案通过增加中间缓存减少了数据多次访
存所带来的功耗与延时,利用存内技术大规模提高访存的并行性,通过并行的方法增大数据计算效率。并且本方案简化了中间缓存的调度逻辑,通过先入先出的fifo策略与简单的循环逻辑控制,减少了采用sram或者寄存器堆当作中间缓存的控制复杂度。
[0151]
本领域技术人员可以理解,实现上述实施例方法的全部或部分流程,可以通过计算机程序来指令相关的硬件来完成,所述的程序可存储于计算机可读存储介质中。其中,所述计算机可读存储介质为磁盘、光盘、只读存储记忆体或随机存储记忆体等。
[0152]
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1