一种城市轨道交通应急处置推荐方法与流程
本发明属于城市轨道交通大数据环境下的应急处理,具体涉及一种城市轨道交通应急处置推荐方法。
背景技术:
1、城市轨道交通网络化运营后,各线路之间存在着复杂的相互影响关系,突发事件对某条线路造成的负面影响将会直接或间接的影响到线网中的其它线路。现有的针对突发事件的应急处理大都采用数字化应急预案方式,在突发事件出现时根据出现的事件类型选择事前确定的静态应急预案,通过接报、事件分级、预案调用、指令下达、评估等处理流程完成应急处置;上述现有的应急处理方式存在应急预案僵化,应急预案配置繁琐,应急预案配置与应急联动设备联系不紧密,应急处置结果或应急演练评估结果无法灵活地为后面的应急处置提供有效参考的问题。
2、马尔可夫链是概率论和数理统计中具有马尔可夫性质且存在于离散的指数集和状态空间内的随机过程,适用于连续指数集的马尔可夫链被称为马尔可夫过程,马尔可夫链可通过转移矩阵和转移图定义,除马尔可夫性外,马尔可夫链可能具有不可约性、常返性、周期性和遍历性。一个不可约和正常返的马尔可夫链是严格平稳的马尔可夫链,拥有唯一的平稳分布;遍历马尔可夫链的极限分布收敛于其平稳分布。
3、马尔可夫决策过程是序贯决策的数学模型,用于在系统状态具有马尔可夫性质的环境中模拟智能体可实现的随机性策略与回报。马尔可夫决策过程基于一组交互对象,即智能体和环境进行构建,所具有的要素包括状态、动作、策略和奖励,在马尔可夫决策过程的模拟中,智能体会感知当前的系统状态,按策略对环境实施动作,从而改变环境的状态并得到奖励,奖励随时间的积累被称为回报。马尔可夫链被应用于蒙特卡罗方法中,形成马尔可夫链蒙特卡罗方法。
4、循环神经网络是一种深度神经网络,是指在全连接神经网络的基础上增加了前后时序上的关系,可以更好地处理与时序相关的问题。循环神经网络是一种对序列数据有较强的处理能力的网络,在网络模型中不同部分进行权值共享使得模型,可以扩展到不同样式的样本,可以将很长的序列进行泛化,得到需要的结果。
技术实现思路
1、针对于上述现有技术的不足,本发明的目的在于提供一种城市轨道交通应急处置推荐方法,以解决现有的应急处理方式存在应急预案僵化,应急预案配置繁琐,应急预案配置与应急联动设备联系不紧密,应急处置结果或应急演练评估结果无法灵活地为后面的应急处置提供有效参考的问题。
2、为达到上述目的,本发明采用的技术方案如下:
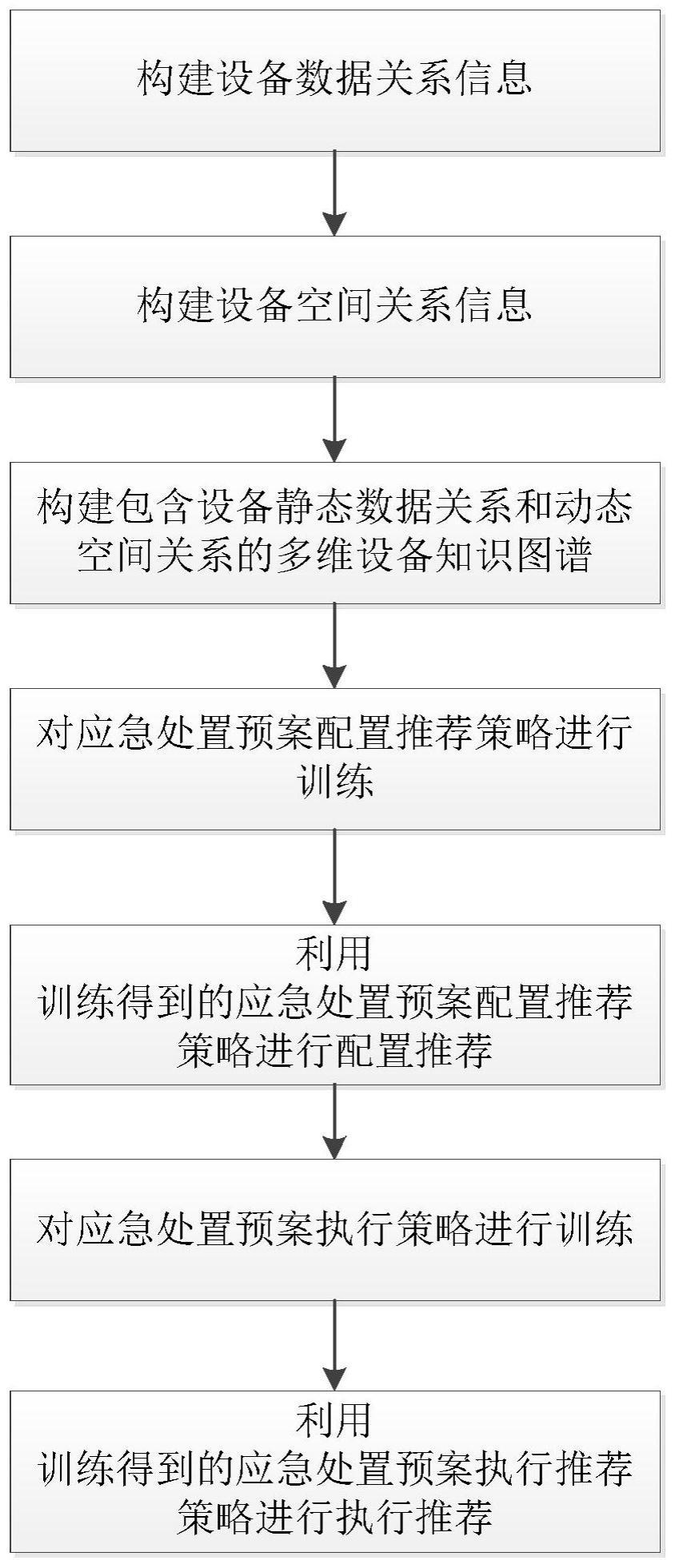
3、本发明的一种城市轨道交通应急处置推荐方法,步骤如下:
4、1)从城市轨道交通生产系统获取城市轨道交通应急处置设备基本信息,构建设备数据关系信息;
5、2)从城市轨道交通bim系统获取城市轨道交通应急处置设备基本空间信息,构建设备空间关系信息;
6、3)基于上述的设备数据关系信息和设备空间关系信息,构建包含设备静态数据关系和动态空间关系的多维设备知识图谱;
7、4)构建城市轨道交通应急处置预案配置推荐环境,利用强化学习中的马尔可夫决策过程、蒙特卡罗方法以及rnn循环神经网络算法相结合的方式对应急处置预案配置推荐策略进行训练;
8、5)利用步骤4)训练得到的应急处置预案配置推荐策略进行配置推荐;
9、6)构建城市轨道交通应急处置预案执行的智能体atagt、环境atenv、执行策略atply、奖惩函数atrwd,利用强化学习中的马尔可夫决策过程、蒙特卡罗方法以及rnn循环神经网络算法相结合的方式对应急处置预案执行推荐策略进行训练;
10、7)利用步骤6)训练得到的应急处置预案执行推荐策略进行执行推荐。
11、进一步地,所述步骤1)具体包括:
12、11)确定城市轨道交通线路的各个车站、车辆段、停车场的综合监控系统及变电所的综合自动化系统的设备类型、协议格式、解析格式;
13、12)按设备类型查询所需的环境与设备监控系统、电力监控系统、通信管理单元、列车自动监控系统、火灾报警系统、自动售检票系统的机电设备数据关系信息;
14、13)获取并根据协议格式解析设备标签、设备类型、模拟点信息、数字点信息、限值、告警信息、错误信息、从属关系、顺序关系、着色关系的机电设备数据关系信息;
15、14)获取并根据协议格式解析设备基本空间关系信息;
16、15)构造设备模型结构,添加设备数据关系信息,并存入用于城市轨道交通应急处置数据库。
17、进一步地,所述步骤2)具体包括:
18、21)从城市轨道交通应急处置数据库选择设备基本信息;
19、22)根据设备基本信息从城市轨道交通bim系统查询设备空间模型;
20、23)根据设备空间模型bim协议解析获得设备空间模型的具体信息;
21、24)从具体信息获取所需设备的详细空间信息,进入步骤25);若城市轨道交通bim系统中不存在所需设备的详细空间信息,则手动输入设备的详细空间信息后,进入步骤25);
22、25)重构设备模型结构,添加设备的详细空间信息,形成设备关系信息模型和设备空间信息模型,并存入城市轨道交通应急处置数据库。
23、进一步地,所述步骤3)具体包括:
24、31)从城市轨道交通应急处置数据库查询设备关系信息模型和设备空间信息模型;
25、32)基于设备关系信息模型,构建以重构后的设备模型为点,以设备之间关系为边的设备静态知识图谱图;
26、33)将包含但不限于设备从属关系、设备组别关系、设备顺序关系、设备着色关系、设备控制关系的设备静态数据加入所述设备静态知识图谱图;
27、34)根据城市轨道交通应急处置数据库中存储的设备n维空间信息,使用空间区域分割方法和闵可夫斯基距离计算局部空间区域内的各设备之间的距离,构建设备动态空间关系;
28、
29、其中,p,q为设备,ρ为正整数,g为按空间区域分割方法分割成的区域,h为与区域g绑定的参变量,根据推荐结果通过反向传播方式进行优化更新;
30、35)根据静态数据关系与动态空间关系,构建包含设备静态数据关系和动态空间关系的多维设备知识图谱;
31、36)将构建的包含设备静态数据关系和动态空间关系的多维设备知识图谱存入城市轨道交通应急处置知识图谱库。
32、进一步地,所述步骤4)具体包括:
33、41)构建城市轨道交通应急处置预案配置的智能体cfagt,进行应急预案配置;
34、42)构建环境cfenv和环境响应函数cfrpfn,根据空间分割的区域和设备动态空间关系d(p,q)进行计算,当两设备不属于同一区域时,环境响应函数cfrpfn返回削弱;当d(p,q)>h时,返回不变;当d(p,q)≤h时,返回增加;
35、43)构建奖惩函数cfrwd,根据历史积累的应急预置配置推荐序列cfrdrs{rs1,rs2,rs3…,rsn}、用户选择结果cfchrs和环境响应函数cfrpfn,对智能体cfagt的act动作(包括打开设备、关闭设备、广播、实时视频)进行价值反馈;奖惩函数当cfchrs不在cfrdrs中时,n=1,否则n=2;result(cfchrs)表示选择结果,factor表示适配因子,其为大于0、小于/等于1的小数;e表示历史积累数据计算的数学期望值;
36、44)利用rnn循环神经网络算法配置策略cfply,t表示时刻,xt表示t时刻的应急处置数据,st表示t时刻配置策略cfply的输出,yt表示t时刻预测应急处置输出,配置策略cfply的输入有两个来源,一个是当前的xt输入,另一个是前一个状态隐层配置策略cfply的输出st-1,w、u、v为参数;st=tanh(uxt+wst-1);yt=softmax(vst);根据rnn前向传播算法和后向传播算法,得到w、u、v为参数;
37、45)智能体cfagt选取一条历史积累的应急预置配置推荐信息,根据配置策略cfply选择配置act动作进行配置执行;
38、46)环境cfenv通过环境响应函数cfrpfn对接收到的配置act动作进行响应,并由奖惩函数cfrwd计算奖惩值;
39、47)将计算得到的奖惩值输入到配置策略cfply,并根据配置策略cfply计算方式更新配置策略cfply的参数;
40、48)利用蒙特卡罗方法随机抽样选择重复步骤45)-47)训练得到应急预置配置推荐策略。
41、进一步地,所述步骤5)具体包括:
42、51)根据用户选择条件,配置智能体cfagt从用户配置的动作序列中选取其中一个act动作;
43、52)配置智能体cfagt通过配置策略cfply对所选的act动作进行配置;
44、53)配置奖惩函数cfrwd计算所选act动作的奖惩值,并进行记录;
45、54)重复步骤51)-53),得到配置动作序列的每个act动作的奖惩值,并按照从大到小排序;
46、55)根据设置数,按顺序将所设置数量的act动作返回给用户;
47、56)用户从返回的act动作序列中选择一个动作,作为配置结果;
48、57)记录预案步骤、每步操作推荐及配置结果,并把全部方案配置信息存入城市轨道交通应急处置数据库。
49、进一步地,所述步骤6)具体包括:
50、61)构建城市轨道交通应急处置预案执行的智能体atagt,进行应急预案执行;
51、62)构建环境atenv和环境响应函数atrpfn,根据空间分割的区域和设备动态空间关系d(p,q)进行计算,当两设备不属于同一区域时,atrpfn返回削弱;当d(p,q)>h时,返回不变;当d(p,q)≤h时,返回增加;
52、63)构建奖惩函数atrwd,根据历史积累的应急预置配置推荐序列atrdrs{rs1,rs2,rs3…,rsn}、用户选择结果atchrs和环境响应函数atrpfn,对智能体atagt的act动作进行价值反馈;奖惩函数当atchrs不在atrdrs中时,n=1,否则n=2;result(atchrs)表示选择结果,factor表示适配因子,其为大于0、小于/等于1的小数;e表示历史积累数据计算的数学期望值;
53、64)利用rnn循环神经网络算法执行策略atply,t表示时刻,xt表示t时刻的应急处置数据,st表示t时刻配置策略atply的输出,yt表示t时刻预测应急处置输出,执行策略atply的输入有两个来源,一个是当前的xt输入,另一个是上一个状态隐层执行策略atply的输出st-1,w、u、v为参数;st=tanh(uxt+wst-1);yt=softmax(vst);根据rnn前向传播算法和后向传播算法,得到w、u、v为参数;
54、65)智能体atagt选取一条历史积累的应急预置执行推荐信息,根据执行策略atply选择执行act动作进行执行;
55、66)环境atenv通过环境响应函数atrpfn对接收到的配置act动作进行响应,并由奖惩函数atrwd计算奖惩值;
56、67)将计算得到的奖惩值输入到执行策略atply,并根据执行策略atply计算方式更新执行策略atply的参数;
57、68)利用蒙特卡罗方法随机抽样选择重复步骤65)-67)训练得到应急预置执行推荐策略。
58、进一步地,所述步骤7)具体包括:
59、71)执行智能体atagt,按照配置结果和实际应急发生事情的类型和位置,根据所述动态空间关系,初步筛选应急联动设备序列;
60、72)执行智能体atagt从配置的执行动作序列中选取其中一个act动作;如果act动作涉及应急联动设备则进入步骤73);如果不涉及具体联动设备,则通过执行奖惩函数atrwd计算act动作奖惩值;
61、73)从应急联动设备序列中选择一个设备;
62、74)奖惩函数atrwd计算所选act动作和设备的奖惩值,并进行记录;
63、75)在所选act动作不变的情况下,选择应急联动设备序列的下一个设备,并通过执行奖惩函数atrwd计算奖惩值,进行记录;
64、76)根据设置act动作类型,选择将设备的奖惩值通过加权平均、期望值、部分累加方式,计算act动作奖惩值;
65、77)重复步骤72),得到执行动作序列的每个act动作的奖惩值,并按照从大到小排序;
66、79)根据设置数,按顺序将所设置数量的执行推荐动作返回给用户;
67、710)从返回推荐动作选择一个执行,并在预案执行后,获取用户评分;
68、711)记录预案执行步骤、每步操作推荐及执行结果和评分,并把全部执行信息存入城市轨道交通应急处置数据库。
69、本发明的有益效果:
70、本发明基于空间区域分割方法和闵可夫斯基距离实现了设备静态数据关系动态空间关系多维设备知识图谱,应用强化学习中的马尔可夫决策过程、蒙特卡罗方法和深度学习的循环神经网络算法,通过应急配置推荐学习简化了应急预案配置,通过应急执行推荐加强了应急预案与应急联动设备之间的联系,并且应急处置结果或应急演练评估结果能够为后面的应急处置提供有效参考。
- 还没有人留言评论。精彩留言会获得点赞!