基于即时编译的脑动力学通用编程系统和编程方法
1.本发明涉及计算机技术领域,尤其涉及一种基于即时编译的脑动力学通用编程系统和编程方法。
背景技术:
2.脑动力学建模已经成为理解大脑工作原理的基本工具和启发新一代人工智能发展的关键途径,目前已成为脑科学和人工智能发展的基础学科。任何一个学科的发展都离不开工具的进步。以人工智能(artificial intelligence,ai)为例,这一轮人工智能的快速发展很大程度上得益于深度学习框架的普及。深度学习框架目前已成为人工智能研究的基础设施,因为它们提供了一个通用的编程接口,能支持研究人员在各个应用领域灵活高效地定义各种ai模型。然而,脑动力学建模这一领域长期以来缺乏一款类似深度学习框架的、允许用户自主灵活编程的、简单易用且灵活高效的、通用的脑动力学编程框架。然而,随着越来越多海量神经数据的产生、模型仿真复杂度的日益增长、建模手段、方法及目标的日趋多样化,我们比以往任何时候都更迫切地需要开发通用的建模工具,以帮助我们轻松构建、模拟、训练和分析多尺度及大尺度的大脑动力学模型。
3.实现通用的脑动力学编程具有本质上的困难,源自于脑动力学模型与深度学习模型存在着诸多显著性差异。首先,脑动力学模型的计算密度一般很低。以经典的泄漏整合发放神经元模型(leaky integrate-and-fire model,lif)来说,其计算主要依赖于加减乘除等访存密集型算子。在深度学习模型内经常使用并可以显著提升设备计算效率的计算密集型算子,诸如卷积和矩阵乘法却很少出现。这意味着纯粹基于计算图的深度学习框架在应用到脑动力学编程时会存在着巨大的计算无关开销,因为算子的启动和数据的传输等会让计算无关开销变得十分显著。其次,脑动力学模型相对于深度学习模型的另一个根本性区别是,前者具有事件驱动和稀疏连接的特性。比如,神经元之间通常以小于20%的概率进行相互连接;在这种稀疏连接下,突触后神经元及突触的状态演化通常由某种神经活动事件(如突触前脉冲)所触发。这一特性使得传统的深度学习算子在脑动力学模型上难以获得最佳的计算性能。因此我们需要真正针对稀疏及事件驱动特性所设计的脑动力学专有算子。
4.当前领域内已有的脑动力学编程方案仍无法让用户真正地获得通用的脑动力学编程框架。已有的编程框架包括neuron、nest、brian2,netpyne和bmtk等。其中,neuron为耶鲁大学开发的一款针对于精细神经元仿真的编程软件;nest为欧盟脑计划开发的一款对于大规模神经动力学仿真的编程软件;brian2为法国巴黎高等师范学院开发的一款轻量级的神经动力学仿真软件;netpyne是基于neuron的描述性语言框架,它能将用户基于字典、列表等进行描述的模型生成为neuron代码;bmtk为美国艾伦脑研究院开发的一款基于neuron、nest等的描述性语言编程框架,能将用户的模型描述生成neuron、nest等上的代码。总体来说,这些脑动力学编程软件主要分为两类:低级编程语言和描述性编程语言。“低级编程语言”的代表是neuron和nest,它们底层基于c++语言进行编写,内置大量编程模型。同时,在用户界面端提供了python的接口,允许用户通过python调用预定义的内置模型。这
equation,fde)求解工具模块、突触连接工具模块和权重初始化工具模块。
17.根据本发明提供的一种基于即时编译的脑动力学通用编程系统,所述脑动力学模型模块包括计算神经科学模型模块和类脑智能计算模型模块中的至少一种。
18.根据本发明提供的一种基于即时编译的脑动力学通用编程系统,所述前端编程层还包括算子自定义接口模块和模型自定义接口模块;
19.所述算子自定义接口模块用于接收输入的自定义的算子信息,以生成对应的算子模块;
20.所述模型自定义接口模块用于接收输入的自定义的模型信息,以生成对应的脑动力学模型模块。
21.根据本发明提供的一种基于即时编译的脑动力学通用编程系统,所述代码编译模块包括即时编译模块、自动并行化模块和自动向量化模块中的至少一种;
22.所述编译指令包括编译方式选择指令和所述脑动力学模型应用的目标设备;
23.所述后端编译层用于根据所述选择的编译方式选择所述即时编译模块、自动并行化模块和自动向量化模块中的至少一种;被选择的模块用于根据所述脑动力学模型应用的目标设备生成适用于所述目标设备的脑动力学模型的二进制机器码。
24.根据本发明提供的一种基于即时编译的脑动力学通用编程系统,所述即时编译模块用于对脑动力学模型根据预设的优化策略进行目标设备无关的编译分析和优化,以及根据所述目标设备进行设备相关的编译分析和优化,并生成适用于所述目标设备的二进制机器码;
25.所述自动并行化模块用于根据所述脑动力学模型应用的目标设备同时生成适用于多个目标设备的脑动力学模型的二进制机器码;
26.所述自动向量化模块用于采用单指令流多数据流并行的方式生成适用于所述目标设备的脑动力学模型的二进制机器码。
27.根据本发明提供的一种基于即时编译的脑动力学通用编程系统,所述后端编译层还包括计算图转换模块;
28.所述计算图转换模块用于将所述脑动力学模型对应的计算图转换为与编程语言无关的中间表达式,所述调用的代码编译模块用于根据所述中间表达式进行代码编译,得到所述脑动力学模型的二进制机器码。
29.另一方面,本发明还提供一种基于脑动力学通用编程系统的编程方法,所述脑动力学通用编程系统包括:前端编程层和后端编译层,所述前端编程层包括预设的多个计算图构建模块,所述后端编译层包括预设的不同功能的代码编译模块;
30.所述编程方法包括:
31.所述前端编程层接收输入的待构建的脑动力学模型对应的计算图构建指令,并根据所述计算图构建指令调用所述预设的多个计算图构建模块中的至少一个,运行调用的计算图构建模块得到所述脑动力学模型对应的计算图;
32.所述后端编译层接收输入的所述脑动力学模型对应的编译指令,以调用所述预设的不同功能的代码编译模块中的至少一个,调用的代码编译模块用于根据所述计算图进行代码编译,得到所述脑动力学模型的二进制机器码。
33.本发明提供的一种基于即时编译的脑动力学通用编程系统,前端编程层根据输入
的计算图构建指令,调用预设的多个计算图构建模块中的至少一个,以构建脑动力学模型对应的计算图;后端编译层用于接收输入的脑动力学模型对应的编译指令,以调用预设的不同功能的代码编译模块中的至少一个,根据构建的计算图进行代码编译,得到脑动力学模型的二进制机器码。因此,本发明的计算图构建过程更加灵活,不受描述性语言的限制,使得本发明的编程系统的通用性较强。
34.另外,本发明的基于即时编译的脑动力学通用编程系统,预设有多个具有成熟功能的计算图构建模块和代码编译模块,在计算图构建过程中和代码编译过程中,根据指令调用对应的模块执行即可,提高了脑动力学模型代码的生成效率。
附图说明
35.为了更清楚地说明本发明或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
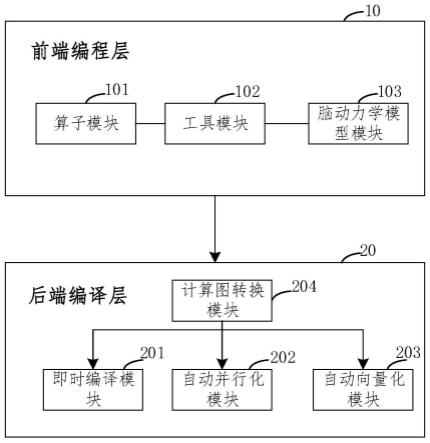
36.图1是本发明提供的脑动力学通用编程系统的结构示意图;
37.图2是本发明提供的算子模块的结构示意图;
38.图3是本发明提供的工具模块的结构示意图;
39.图4是本发明提供的脑动力学模型模块的结构示意图;
40.图5是本发明提供的一种计算图示意图;
41.图6是本发明提供编程系统工作时的流程示意图;
42.图7是本发明提供的脑动力学通用编程方法流程图。
具体实施方式
43.为使本发明的目的、技术方案和优点更加清楚,下面将结合本发明中的附图,对本发明中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
44.本发明提供一种基于即时编译的脑动力学通用编程系统,该系统包括前端编程层和后端编译层,前端编程层包括预设的多个计算图构建模块,后端编译层包括预设的不同功能的代码编译模块。根据不同的待构建的脑动力学模型,调用不用所需的计算图构建模块构建出对应的计算图(即计算机图),然后根据不同的编译需求,调用对应的代码编译模块快速生成脑动力学模型的代码。本发明的计算图构建过程更加灵活,使得本发明的编程系统的通用性较强;在计算图构建过程中和代码编译过程中根据指令调用对应的模块执行即可实现,提高了脑动力学模型代码的生成效率。
45.实施例一:
46.本实施例提供一种基于即时编译的脑动力学通用编程系统,如图1,该编程系统包括:前端编程层10和后端编译层20,前端编程层10包括预设的多个计算图构建模块,后端编译层20包括预设的不同功能的代码编译模块。
47.其中,前端编程层10用于接收输入的待构建的脑动力学模型对应的计算图构建指
令,并根据计算图构建指令调用预设的多个计算图构建模块中的至少一个,运行调用的计算图构建模块得到脑动力学模型对应的计算图。后端编译层20用于接收输入的脑动力学模型对应的编译指令,以调用预设的不同功能的代码编译模块中的至少一个,调用的代码编译模块用于根据计算图进行代码编译,得到脑动力学模型在目标设备上的二进制机器码。
48.本实施例的计算图构建过程更加灵活,使得本发明的编程系统的通用性较强;在计算图构建过程中和代码编译过程中根据指令调用对应的模块执行即可实现,提高了脑动力学模型代码的生成效率。
49.依据本实施例的系统,用户给定脑动力学模型方程,首先基于前端编程层10使用相关算子、工具、和模型来组合形成该模型的编程实现。该编程实现实际上定义了一个计算流图,基于该计算流图,使用后端编译工具来对该计算图进行编译优化、代码生成和硬件部署。
50.其中,计算图构建模块包括算子模块101、工具模块102和脑动力学模型模块103中的至少一种;算子模块101、工具模块102和脑动力学模型模块103中分别预设有不同的计算图构建算子。
51.一般的,一个计算图构建模块包括算子模块101、工具模块102和脑动力学模型模块103中任意一个。换言之,一个计算图构建模块可以认为是一个算子模块101,或者一个计算图构建模块也可以认为是一个工具模块102或者脑动力学模型模块103。
52.其中,本实施例的计算图构建指令包括计算图构建模块选择指令和模型构建参数。前端编程层10用于根据计算图构建模块选择指令调用算子模块、工具模块和脑动力学模型模块中的至少一个,被调用的模块的用于根据模型构建参数以及计算图构建算子,得到脑动力学模型对应的计算图。
53.如图7为本实施例的编程系统的编程流程示意图。其中,如图2,本实施例的算子模块包括:稠密矩阵算子模块、稀疏矩阵算子模块、事件驱动算子模块、自动微分模块中的至少一种。具体的,本实施例中一个算子模块可以理解为包括一种算子,而本实施例包括多个如图2所示的不同类型的算子模块,每个算子模块用于实现不同的算子操作。
54.脑动力学编程往往涉及到一些传统的稠密矩阵相关的计算算子,比如,加减乘除及指数运算等,更涉及到一些专有算子,比如稀疏矩阵相关的计算算子,和事件驱动计算相关的算子。本发明针对脑动力学编程的这一特点提供了完备的算子支持。
55.为了保证传统科学计算逻辑的完备性,该系统的算子模块提供了众多稠密矩阵计算的相关编程算子,包括常见的数组操作、三角函数、算术函数、统计函数、排序函数、线性代数函数、随机采样函数、傅里叶变换函数等等。这些编程算子已经在现有科学计算框架被广泛采用,其实现可以参考成熟的科学计算框架。
56.针对脑动力学模型具有稀疏连接的特性,本系统的算子模块提供了稀疏矩阵相关的算子操作,包括稀疏矩阵乘法、逐元素(element-wise)运算等。
57.针对脑动力学模型具有事件驱动的特性,本系统的算子模块提供了事件驱动计算的算子操作,比如突触前神经元的脉冲事件驱动突触后神经元的计算,神经元稀疏连接下的矩阵加法运算和乘法运算等等。
58.针对脑动力学建模过程中数值优化涉及到函数的一阶导数值或二阶导数值,本系统的算子模块提供了上述各算子的自动微分支持,为每个算子实现相应的微分求导函数。
59.本系统的算子模块不仅提供了上述众多的算子操作,还支持用户自定义算子。特别的,本系统提供了简单灵活的算子自定义接口模块,使得用户能够基于高级编程语言(如python)直接定义基础算子。用户不用使用低级语言进行算子自定义,这样能极大地降低用户学习算子自定义的成本。
60.其中,如图2,本实施例的工具模块包括下述至少一种:ode求解工具模块、sde求解工具模块、dde求解工具模块、fde求解工具模块、突触连接工具模块、权重初始化工具模块和数值优化器模块。具体的,本实施例中一个工具模块可以理解为包括如图3所示的一种工具模块,而本实施例包括多个如图3所示的不同类型的工具模块。
61.脑动力学编程通常涉及各种微分方程的数值求解,突触连接,突触权重的初始化,数值优化器的使用等等。本系统基于上述算子操作提供常用的脑动力学编程工具库。
62.本系统的工具模块提供了脑动力学编程常用的常微分方程(ordinary differential equation,ode)的一般性数值积分方法,包括显式runge-kutta方法、自适应runge-kutta方法、隐式runge-kutta方法,和指数积分方法。
63.本系统的工具模块提供了脑动力学编程常用的随机微分方程(stochastic differential equation,sde)的一般性数值积分方法,支持ito型和straronovich型微分方程的数值积分,支持具有高维wiener随机过程的微分方程的数值积分。
64.本系统的工具模块提供分数阶微分方程(fractional differential equation,fde)的一般性数值积分方法,支持caputo分数阶、gr
ü
nwald-letnikov分数阶和riemann-liouville分数阶微分方程的数值积分。
65.本系统的工具模块提供脑动力学编程常用的时滞微分方程(delay differential equation,dde)的一般性数值积分方法。具体来说,支持时滞常微分方程、时滞随机微分方程、时滞分数阶微分方程的数值积分,各种微分方程的时滞支持常时滞、状态依赖时滞、中立型时滞等的数值积分。
66.本系统的工具模块提供脑动力学编程常用的突触连接方法,包括规则性的连接方法(如一对一连接、全连接、网格连接等)、随机连接方法(如固定概率连接、固定突触前数量连接、固定突触后连接、高斯概率连接、概率距离连接、小世界网络连接、无标度连接、双优无标度连接、幂律连接等),以及支持用户自定义连接。
67.本系统的工具模块提供脑动力学编程常用的权重初始方法,包括规则初始化(如常数初始化、单位阵初始化等)、随机初始化(如正态分布初始化、均匀分布初始化、截尾正态分布初始化、正交矩阵初始化、lecun均匀初始化、lecun正态分布初始化、glorot正态分布初始化、glorot均匀分布初始化、he正态分布初始化、he均匀方差缩放初始化等),以及衰减初始化方法(如高斯衰减初始化、高斯差分衰减初始化等)。
68.本系统的工具模块提供脑动力学编程常用的数值优化器,包括随机梯度下降优化器、rmsprop优化器、adagrad优化器、adadelta优化器、adam优化器、adamax优化器等。
69.其中,如图4,本实施例的脑动力学模型模块103包括计算神经科学模型模块和类脑智能计算模型模块中的至少一种。具体的,本实施例中包括两个脑动力学模型模块,两个脑动力学模型模块分别为计算神经科学模型模块和类脑智能计算模型模块。
70.脑动力学建模目前在各个层次已经提炼出一些经典的神经计算模型,包括神经元模型、突触模型和网络模型。本系统在脑动力学模型模块提供了众多经典的神经计算模型。
71.在一种实施例中,本系统的脑动力学模型模块提供了计算神经科学内众多经典的模型,包括经典的神经元模型,如霍奇金-赫胥黎(hodgkin-huxley,hh)神经元模型、泄漏整合发放(leaky integrate-and-fire,lif)神经元模型、二次整合发放(quadratic integrate-and-fire,qif)神经元模型、指数整合发放(exponential integrate-and-fire,expif)模型、适应性指数整合发放(adaptive exponential integrate-and-fire,adex)模型、izhikevich神经元模型、hindmarsh-rose神经元模型、泛化整合发放(generalized integrate-and-fire,gif)模型等等;经典的突触模型,如电压跳变(voltage-jump)突触模型、指数衰减(exponential decay)突触模型、alpha函数突触模型、双指数衰减(dual exponential decay)突触模型、ampa突触模型、gabaa突触模型、nmda突触模型、gabab突触模型、电突触模型、短时程可塑性(short-term plasticity)突触模型、长时程可塑性(long-term plasticity)突触模型等。
72.在一种实施例中,本系统的脑动力学模型模块提供了类脑计算领域内诸多经典模型,包括连续吸引子网络(continuous attractor neural network)模型、决策网络网络(decision making network)模型、兴奋抑制平衡网络(e/i balanced network)模型、库网络(reservoir computing)模型。
73.本实施例中,若待构建的脑动力学模型对应的方程已经在已有的模型库中(包括“计算神经科学模型”和“类脑智能计算模型”)实现,则直接调用已有的标准模型的实现,即直接调用计算神经科学模型模块和类脑智能计算模型模块。若待构建的脑动力学模型的方程可以拆分为已有模型库中标准模型的组合,则直接组合堆叠现有模型库中的模型来实现用户所规定的模型方程。若待构建的脑动力学模型的方程为非标准模型,也不能完全由标准模型组合形成,那么将能拆分为标准模型的部分依然调用标准模型实现,将非标准模型部分用“前端编程层10”中的算子和工具进行实现。比如,模型中的常微分方程、随机微分方程等等可以使用“ode求解器”、“sde求解器”进行实现,模型中的事件驱动更新可以使用“事件驱动算子”进行实现,模型中的稠密矩阵、稀疏矩阵相关的操作可以使用“稠密矩阵算子”、“稀疏矩阵算子”进行实现。
74.在一种实施例中,前端编程层10还包括算子自定义接口模块和模型自定义接口模块。算子自定义接口模块用于接收输入的自定义的算子信息,以生成对应的算子模块。本系统的工具模块不仅提供了上述丰富的工具库,还支持用户自定义工具库。特别地,用户可基于本系统提供的算子模块进行自由组合从而对想要的工具库进行编程。
75.模型自定义接口模块用于接收输入的自定义的模型信息,以生成对应的脑动力学模型模块。例如,本系统的模型自定义接口模块提供了“dynamicalsystem”接口用于自定义任意的脑动力学模型。“dynamicalsystem”接口提供模块化和组合编程的范式可帮助用户实现任意层次的脑动力学模型。
76.计算图提供了连接前端编程层10和后端编译层20的桥梁,它是前端编程层的输出,也是后端编译层的输入。计算图是一个由算子组成的有向图,其节点要么是输入值,要么对应着算子所定义的数学运算。每一个脑动力学模型的运行将对应一个计算图。如图5提供了一个典型的积分泄露模型的计算图。
77.其中,后端编译层20提供了脑动力学模型的编译、运行和部署。
78.如图1,本实施例中的代码编译模块包括即时编译模块、自动并行化模块和自动向量化模块中的至少一种。具体的,本实施例中包括三个代码编译模块,该三个代码编译模块分别为时编译模块、自动并行化模块和自动向量化模块。
79.其中,本实施例的后端编译层20接收到的编译指令包括编译方式选择指令和脑动力学模型应用的目标设备。一般的,常见的目标设备包括cpu(中央处理器)、gpu(图形处理器)和tpu(即tensor processing unit,张量处理器)。
80.后端编译层20用于根据选择的编译方式选择即时编译模块、自动并行化模块和自动向量化模块中的至少一种;被选择的模块用于根据脑动力学模型应用的目标设备生成适用于目标设备的脑动力学模型的代码。
81.其中,即时编译模块201用于对脑动力学模型根据预设的优化策略进行目标设备无关的编译分析和优化,以及根据目标设备进行设备相关的编译分析和优化,并生成适用于目标设备的二进制机器码。
82.其中,自动并行化模块202用于根据脑动力学模型应用的目标设备同时生成适用于多个目标设备的脑动力学模型的二进制机器码。
83.其中,自动向量化模块203用于采用单指令流多数据流并行的方式生成适用于目标设备的脑动力学模型的二进制机器码。
84.具体的,本系统的即时编译模块201提供了与设备无关的多种分析和优化过程,包括静态单赋值(static single assignment,ssa)、公共子表达式消除(common subexpression elimination,cse)、死代码删除(dead code elimination,dce)、与设备无关的算子融合(operator fusion)、为计算分配运行时内存的缓冲区分析等等。其中,本系统的即时编译提供了与设备相关的多种分析和优化过程,包括有利于gpu计算的算子融合、计算流的划分、适合调用优化库的运算匹配等。
85.本系统提供的自动并行化模块202提供了在多个设备上进行单指令流多数据流(single-instruction stream multiple-data stream,simd)的数据并行处理能力。其每个设备上的编译流程与上述单设备上的即时编译流程一致。
86.本系统提供的自动向量化模块203提供了在单个设备上进行单指令流多数据流的数据并行处理能力。它识别中间表达式中可以向量执行的部分,将标量语句自动转换为相应的simd向量语句。因此将原来需要多次装载的数据一次性装载到向量寄存器,从而提高吞吐量。
87.在一种实施例中,后端编译层20还包括计算图转换模块204。计算图转换模块204用于将脑动力学模型对应的计算图转换为与编程语言无关的中间表达式,调用的代码编译模块用于根据中间表达式进行代码编译,得到脑动力学模型的代码。换言之,本系统的后端编译层得到计算图后,计算图转换模块204首先将计算图转换为中间表达式。中间表达式是一种与编程语言无关的低层级形式,接近机器码。它结构紧凑,包含了控制流信息,更加适合用来做静态分析。本系统提供的中间表达式支持控制流信息。
88.本实施例的本系统提供的后端编译层20提供了单一设备上的即时编译,多个设备上的并行计算编译,和单个设备上的自动向量化编译。在后端编译中,针对用户指定的需要即时编译的代码,首先将模型计算图转换为与编程语言无关的中间表达式。其后,将中间表示进行多遍优化,优化具体包括:与设备无关的分析和优化和设备相关的分析和优化。针对
用户指定的需要自动向量化的循环代码,首先将模型计算图转换为与编程语言无关的中间表达式。其后将标量语句自动转换为相应的simd向量语句。针对用户指定的需要自动并行化的代码,首先将模型计算流图转换为与编程语言无关的中间表达式。其后,在每个设备上执行与上述即时编译一致的优化和分析。
89.本系统提供的代码生成使用llvm(构架编译器)进行低级中间表示的代码生成。在cpu、gpu、tpu等设备上,代码生成层发出有效计算优化后的中间表示的llvm ir(intermediate representation,中间表示),然后调用llvm从llvm ir中发出原生代码。
90.本实施例的编程系统和现有的方案相比主要具有以下优势:
91.1、根据不同的待构建的脑动力学模型,调用不用所需的计算图构建模块构建出对应的计算图,然后根据不同的编译需求,调用对应的代码编译模块快速生成脑动力学模型的代码,使得本发明的编程系统的通用性较强。
92.2、在计算图构建过程中和代码编译过程中根据指令调用对应的模块执行即可实现,系统中定义的所有模型都可以进行即时编译,以实现高性能的运行速度,提高了脑动力学模型代码的生成效率。
93.3、设有算子自定义接口模块和模型自定义接口模块,即系统前端编程层中的许多核心工具模块和脑动力学模型模块都可以通过继承基类来直接定制,可扩展性强,减少了编程的工作量。
94.实施例二:
95.本实施例提供一种基于脑动力学通用编程系统的编程方法,脑动力学通用编程系统包括:前端编程层10和后端编译层20,前端编程层10包括预设的多个计算图构建模块,后端编译层20包括预设的不同功能的代码编译模块。
96.其中,如图7,基于脑动力学通用编程系统的编程方法包括:
97.步骤701:前端编程层接收输入的待构建的脑动力学模型对应的计算图构建指令,并根据计算图构建指令调用所述预设的多个计算图构建模块中的至少一个,运行调用的计算图构建模块得到所述脑动力学模型对应的计算图。
98.步骤702:后端编译层接收输入的脑动力学模型对应的编译指令,以调用预设的不同功能的代码编译模块中的至少一个,调用的代码编译模块用于根据计算图进行代码编译,得到脑动力学模型在目标设备上的二进制机器码。
99.其中,本实施例的编程方法可与上述实施例一中的变成系统对照理解,此处不再赘述。
100.以上所描述的装置实施例仅仅是示意性的,其中所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本实施例方案的目的。本领域普通技术人员在不付出创造性的劳动的情况下,即可以理解并实施。
101.通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到各实施方式可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件。基于这样的理解,上述技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品可以存储在计算机可读存储介质中,如rom/ram、磁碟、光盘等,包括若干指
令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行各个实施例或者实施例的某些部分所述的方法。
102.最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1