基于异构图表示学习的软件缺陷自动定位方法
1.本发明涉及软件维护领域,尤其涉及一种基于异构图表示学习的软件缺陷定位方法。
背景技术:
2.软件在人们的生活中起着重要作用。它被广泛应用于各个领域,如医疗、游戏娱乐、航空航天等。然而,软件固有的复杂性导致软件缺陷不可避免。软件缺陷一旦被发现,开发者需要确定缺陷出现的位置并进行修复。未及时修复的软件缺陷不但会影响用户的使用体验,还会造成人力物力的巨大损失。据统计,在软件开发中约有42%的经费用于投入与软件缺陷相关的工作,而在维护阶段发现缺陷的成本是开发阶段的100倍。因此,研究如何帮助开发人员更好更快地修复缺陷具有重要的意义。
3.已有的缺陷定位方法按照是否需要执行测试用例,可分为两类:静态缺陷定位方法和动态缺陷定位方法。静态缺陷定位方法通过分析缺陷报告和程序代码并提取特征,利用特定模型确定可疑的程序模块,并将其推荐给开发人员以辅助定位;动态缺陷定位方法通过搜集测试用例的执行信息和运行结果,对被测程序的内在结构进行分析,以确定缺陷语句在被测程序内的可能位置。相比于静态缺陷定位方法,动态缺陷定位方法是基于测试用例的覆盖信息来实现缺陷定位,通常能够获得更好的效果。
技术实现要素:
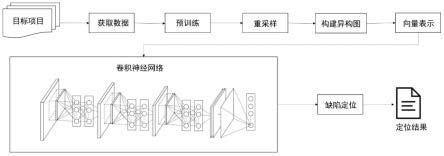
4.本发明的目的是为了解决现有软件缺陷定位方法对各类信息利用低下的问题,提供一种基于异构图表示学习的软件缺陷自动定位方法,可以有效地帮助开发人员定位软件缺陷。
5.为实现上述目的,本发明的技术方案是:
6.步骤(1)获取缺陷定位所需数据:
7.子步骤1-1,从目标项目中获取测试用例的集合t=(test1,test2,
…
,testn),和所包含的方法的集合m=(method1,method2,
…
,methodm),其中n和m分别代表测试用例个数和方法的个数。
8.子步骤1-2,使用开源工具javaagent和asm,对代码进行动态插桩,即在每个方法中插入特定代码,一旦该方法被测试用例调用,将会打印出方法名,最终根据输出信息可以得到测试用例的代码覆盖信息。
9.子步骤1-3,通过github获取项目的历史日志,从中提取项目的历史修改信息。若两个方法methoda和methodb(a≠b)在同一版本被修改,则将其表示为一个配对mpair=《methoda,methodb》,所有的配对组成集合mp。
10.子步骤1-4,使用开源工具tinypdg获取目标代码中各方法的调用关系,若两个方法methoda和methodb(a≠b)之间存在调用关系,则表示为一个配对cpair=《methoda,methodb》,表示methoda调用了methodb,所有的配对组成集合cp。
11.步骤(2)将方法集和测试用例集均采用两种不同的方式进行处理:
12.子步骤2-1,将所有方法源代码和测试用例源代码当作文本进行处理,利用byte pair encoding(bpe)算法对文本进行分词,构建关键词字典tok={token1,token2,
…
,token
len1
},其中len1表示字典包含关键词的个数。每个方法和测试用例可以表示为一个token序列。
13.子步骤2-2,使用开源工具javaparser将所有方法源代码和测试用例源代码转换为抽象语法树(abstract syntax tree,ast),所有抽象语法树包含的结点形成集合nod=(node1,node2,
…
,node
len2
),其中len2表示结点的数量。
14.步骤(3),利用word2vec词嵌入技术,对项目中所有方法和测试用例文本进行训练,得到每个tokeni(i=1,2,
…
len1)的词向量同时使用node2vec结点嵌入技术,对所有抽象语法树进行训练,得到每个结点nodej(j=1,2,
…
,len2)的向量
15.步骤(4)对小类样本进行重采样,使得失败测试用例和成功测试用例的数量、存在缺陷的方法和没有缺陷的方法的数量达到一致,并且,构建新添加的方法和测试用例之间的覆盖关系,即对原方法和原测试用例的覆盖信息进行复制。
16.步骤(5)构建异构图g=(v,e),其中v表示顶点的集合,e表示边的集合,且v包含两种类型的顶点v
method
和v
test
,e包含四种类型的边e
pass
、e
fail
、e
modify
和e
call
。
17.子步骤5-1,将m中的每个方法抽象为顶点v
method
∈v,其属性表示为attr(v
method
)=(vector
mtext
,vector
mast
),其中),其中为方法文本信息的向量表示,量表示,为方法结构信息的向量表示,len3表示方法文本所包含的token数量,len4表示方法对应抽象语法树所包含的结点数量。
18.子步骤5-2,将t中的每个测试用例抽象为顶点v
test
∈v,其属性表示为attr(v
test
)=(vector
ttext
,vector
tast
),其中),其中为测试用例文本信息的向量表示,的向量表示,为测试用例结构信息的向量表示,len5表示测试用例文本所包含的token数量,len6表示测试用例对应抽象语法树所包含的结点数量。
19.子步骤5-3,若通过的测试用例覆盖了某个方法,则在两顶点之间点添加一条边e
pass
∈e;若失败的测试用例覆盖了某个方法,则在两顶点之间添加一条边e
fail
∈e。
20.子步骤5-4,根据集合mp中的配对,在对应方法顶点之间添加一条边e
modify
∈e;根据集合cp中的配对,在对应方法顶点之间添加一条边e
call
∈e。
21.经过以上步骤,成功将各类信息整合为一张异构图。
22.步骤(6)针对顶点v∈v,通过对所有向量各维度累加求平均的方式,形成顶点v的属性向量表示vector
attr
。
23.步骤(7)在图g中,对于顶点v,将所有与该顶点通过某一种类型边连接的各邻居顶点的属性向量,通过累加求平均的方式,形成该顶点的类型向量表示。最后得到四种类型向量表示,即vector
pass
、vector
fail
、vector
modify
、vector
call
。
encoding(bpe)算法对文本进行分词,构建关键词字典tok={token1,token2,
…
,token
len1
},其中len1表示字典的长度。每个方法和测试用例可以表示为一个token序列。
39.2-2使用开源工具javaparser将所有方法源代码和测试用例源代码转换为抽象语法树(abstract syntax tree,ast)。所有抽象语法树包含的结点形成集合nod=(node1,node2,
…
,node
len2
),其中len2表示结点的数量。
40.步骤(3),利用word2vec词嵌入技术,对项目中所有方法和测试用例文本进行训练,得到每个tokeni(i=1,2,
…
len1)的词向量同时使用node2vec结点嵌入技术,对所有抽象语法树进行训练,得到每个结点nodej(j=1,2,
…
,len2)的向量本发明中词向量和结点向量的维度设置128。
41.步骤(4)对小类样本进行重采样,使得失败测试用例和成功测试用例的数量、存在缺陷的方法和没有缺陷的方法的数量达到一致,并且,构建新添加的方法和测试用例之间的覆盖关系,即对原方法和原测试用例的覆盖信息进行复制。
42.步骤(5)构建异构图g=(v,e),其中v表示顶点的集合,e表示边的集合,且v包含两种类型的顶点v
method
和v
test
,e包含四种类型的边e
pass
、e
fail
、e
modify
和e
call
。
43.5-1将m中的每个方法抽象为顶点v
method
∈v,其属性表示为attr(v
method
)=(vector
mtext
,vector
mast
),其中),其中表示文本信息的向量表示,表示,表示结构信息的向量表示,len3表示方法文本所包含的token数量,len4表示方法对应抽象语法树所包含的结点数量。
44.5-2将t中的每个测试用例抽象为顶点v
test
∈v,其属性表示为attr(v
test
)=(vector
ttext
,vector
tast
),其中),其中表示为文本信息的向量表示,表示,表示结构信息的向量表示,len5表示测试用例文本所包含的token数量,len6表示测试用例对应抽象语法树所包含的结点数量。
45.5-3若通过的测试用例覆盖了某个方法,则在两顶点之间添加一条边e
pass
∈e;若失败的测试用覆盖了某个方法,则在两顶点之间添加一条边e
fail
∈e。
46.5-4根据集合mp中的配对,在对应方法顶点之间添加一条边e
modify
∈e;根据集合cp中的配对,在对应方法顶点之间添加一条边e
call
∈e。
47.步骤(6)针对顶点v∈v,通过对所有向量各维度累加求平均的方式,形成顶点v的属性向量表示,具体计算公式如下;
[0048][0049]
其中f0(v)表示聚合后顶点v的属性向量,vector
text
表示顶点v的文本信息向量表示,即vector
mtext
和vector
ttext
,vector
ast
表示顶点v的结构信息向量表示,即vector
mast
和vector
tast
。
[0050]
步骤(7)在图g中,对于顶点v,将所有与该顶点通过某一种类型边连接的各邻居顶点的属性向量,通过累加求平均的方式,形成该顶点的类型向量表示。最后得到四种类型向量表示,具体计算公式为:
[0051][0052]
其中k=1,2,3,4分别对应边类型e
pass
、e
fail
、e
modify
和e
call
,nk(v)表示通过第k种类型的边与顶点v连接的所有顶点的集合,fk(v)表示该集合所有顶点聚合后形成的顶点v的类型向量。
[0053]
步骤(8)针对顶点v∈v,将该顶点的属性向量表示和四种类型向量表示利用注意力机制进行聚合,获得该方法顶点的最终向量表示,具体计算公式如下:
[0054][0055][0056]
其中vector
final
表示方法结点最终的向量表示,αj表示注意力机制学习到的每种类型信息的权重,表示级联操作。
[0057]
步骤(9)基于convolutional neural networks(cnn)构建预测模型,其中所有方法顶点的最终向量表示作为模型的输入,学习方法向量表示所包含的特征,最后使用sigmoid对cnn的输出进行正则化处理,获得每个方法的可疑分数,即每个方法存在缺陷的概率。本发明cnn模型共包含3个卷积层和三个全连接层,三个卷积层卷积核的维度分别设置为16、16、32,每个全连接层的维度为1024。
[0058]
步骤(10)所有方法按照可疑分数降序排序,获得最后的推荐结果。
[0059]
实施例1的实验证明:
[0060]
为证明本发明的有效性,本发明使用top-k、mean first rank(mfr)、mean average rank(mar)作为评价指标,在公开数据集defects4j(1.2.0版本)上用本发明的技术对比目前比较先进的软件缺陷定位技术cnnfl、fluccs、grace,实验结果如表1所示。
[0061]
表1
[0062][0063]
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1