用于文本到SQL任务的数据生成方法、电子设备和存储介质与流程
用于文本到sql任务的数据生成方法、电子设备和存储介质
技术领域
1.本发明涉及智能语音领域,尤其涉及一种用于文本到sql任务的数据生成方法、电子设备和存储介质。
背景技术:
2.text-to-sql(文本到sql)是指将自然语言(nl)话语转换为结构化sql。在智能语音与用户交互中,例如,用户输入“唱这首歌的歌手是谁”、“这本书的作者是谁”这类查询语句时,需要将这些文本转化成对应的sql语句进行查询。为了提高智能语音的交互性能,就需要大量的文本到sql数据进行训练。通常有以下技术获取文本到sql数据:
3.1、spider-syn是一个基于spider人工收集的text-to-sql数据集,意在为text-to-sql任务中的文本泛化性研究提供研究数据,收集的方式为人工将问句中数据库相关词汇或短语替换成其近义词。
4.2、adveta是一个基于spider人工收集的text-to-sql数据集,意在为text-to-sql任务中数据库结构以及文本的泛化性研究提供研究数据,收集方式为人工在数据库中加入具有对抗性名称的列,以及将部分列名替换成其近义词。
5.3、mr为一全自动的text-to-sql数据生成工具,基于原有text-to-sql数据,可以自动生成三种文本相异以及八种数据库结构相异的合成数据,生成方式为基于规则的变换。
6.在实现本发明过程中,发明人发现相关技术中至少存在如下问题:
7.spider-syn和adveta的目的都在于破坏基于字符串的数据库模式链接方法,将问句中的词替换成近义词在功能上等同于将数据库中的列名替换成同义词,然而,两者都只是对于文本层面的研究。
8.adveta尝试在数据库中加入新的列,但并没有改变数据中需要预测的sql的标签,并不能为结构泛化性的研究提供合适的研究材料。
9.mr虽然为全自动的生成工具,但其生成文本相异数据的方法所参考的规则过于简单,达不到研究文本泛化性的要求,同时其生成数据库结构相异的数据的方法部分是错误的(即生成的数据库结构与先前是相同的),且所有变换都不会使最终的sql有所改变,和adveta一样,不能为结构泛化性的研究提供合适的数据。
技术实现要素:
10.为了至少解决现有技术中生成应用于文本到sql任务的数据大都止于文本层面,针对数据库模式的结构多样性是匮乏的,同样的问句在不同结构的数据库模式下,对应的sql的表达方式可能也是不同的,使得利用文本层面增强的数据训练效果不佳的问题。
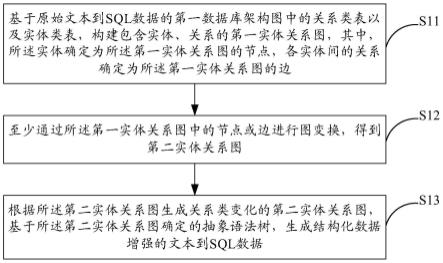
11.第一方面,本发明实施例提供一种用于文本到sql任务的数据生成方法,包括:
12.基于原始文本到sql数据的第一数据库架构图中的关系类表以及实体类表,构建包含实体、关系的第一实体关系图,其中,所述实体确定为所述第一实体关系图的节点,各
实体间的关系确定为所述第一实体关系图的边;
13.至少通过所述第一实体关系图中的节点或边进行图变换,得到第二实体关系图;
14.根据所述第二实体关系图生成关系类变化的第二实体关系图,基于所述第二实体关系图确定的抽象语法树,生成结构化数据增强的文本到sql数据。
15.第二方面,本发明实施例提供一种用于文本到sql任务的数据生成系统,包括:
16.实体关系确定程序模块,用于基于原始文本到sql数据的第一数据库架构图中的关系类表以及实体类表,构建包含实体、关系的第一实体关系图,其中,所述实体确定为所述第一实体关系图的节点,各实体间的关系确定为所述第一实体关系图的边;
17.图变换程序模块,用于至少通过所述第一实体关系图中的节点或边进行图变换,得到第二实体关系图;
18.数据生成程序模块,用于根据所述第二实体关系图生成关系类变化的第二实体关系图,基于所述第二实体关系图确定的抽象语法树,生成结构化数据增强的文本到sql数据。
19.第三方面,提供一种电子设备,其包括:至少一个处理器,以及与所述至少一个处理器通信连接的存储器,其中,所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行本发明任一实施例的用于文本到sql任务的数据生成方法的步骤。
20.第四方面,本发明实施例提供一种存储介质,其上存储有计算机程序,其特征在于,该程序被处理器执行时实现本发明任一实施例的用于文本到sql任务的数据生成方法的步骤。
21.本发明实施例的有益效果在于:利用少量的标注可以自动生成大量的适用于结构泛化性研究的数据,同时也可以使用本方法生成的结构化的文本到sql数据用作数据增强来提升text-to-sql系统的鲁棒性,进而提升用户语音交互的体验。
附图说明
22.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作一简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
23.图1是本发明一实施例提供的一种用于文本到sql任务的数据生成方法的流程图;
24.图2是本发明一实施例提供的一种用于文本到sql任务的数据生成方法的问题相同、数据库模式不同时,目标sql的不同响应方式的示意图;
25.图3是本发明一实施例提供的一种用于文本到sql任务的数据生成方法的生成框架图;
26.图4是本发明一实施例提供的一种用于文本到sql任务的数据生成方法的不同变换方式生成的ds的示意图;
27.图5是本发明一实施例提供的一种用于文本到sql任务的数据生成方法的四种图转换的生成数据统计示意图;
28.图6是本发明一实施例提供的一种用于文本到sql任务的数据生成系统的结构示
意图;
29.图7为本发明一实施例提供的一种用于文本到sql任务的数据生成的电子设备的实施例的结构示意图。
具体实施方式
30.为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
31.如图1所示为本发明一实施例提供的一种用于文本到sql任务的数据生成方法的流程图,包括如下步骤:
32.s11:基于原始文本到sql数据的第一数据库架构图中的关系类表以及实体类表,构建包含实体、关系的第一实体关系图,其中,所述实体确定为所述第一实体关系图的节点,各实体间的关系确定为所述第一实体关系图的边;
33.s12:至少通过所述第一实体关系图中的节点或边进行图变换,得到第二实体关系图;
34.s13:根据所述第二实体关系图生成关系类变化的第二实体关系图,基于所述第二实体关系图确定的抽象语法树,生成结构化数据增强的文本到sql数据。
35.在本实施方式中,考虑到现有技术缺少关于ds(database schema,数据库架构)的各种结构的研究。如图2所示,给定用户相同的文本问题和不同的数据库模式,目标sql(structured query language,结构化查询语言)是完全不同的。实体的“singer”可以作为列、表或列“identity”(身份)的特定单元格值,这取决于对应ds的本体。尽管用户意图非常简单,但数据库模式角色中的这种区别导致了完全不同的sql草图。当涉及到多表情况时,这个问题变得更加复杂,因为有大量可能的角色组合。
36.本方法提出了数据和结构驱动的生成框架来合成结构化数据增强的文本到sql数据。从spider数据集中获取原始文本到sql数据集,它包含了跨越146个数据库的8659个训练示例和1034个验证示例。测试数据集是不可见的,包含2147个样本和40个数据库。
37.对于步骤s11,本方法的生成框架如图3所示,从原始文本到sql数据集中选定一个原始文本到sql数据,构造其对应的数据库架构图。例如,原始文本到sql数据为:
38.sample(x,d,y)
39.question(x):who is the author of harry potter?//《哈利
·
波特》的作者是谁?
40.database(d)
41.sql(y):select people.name from people join author on people.id=author.pid join write on author.id=write.aid join novel on write.nid=novel.id where novel.name=
‘
harry potter’//对应的查询语句。
42.对应的数据库架构图如图3中的database(d)所示,图中的“people”节点、“author”节点、“write”节点、“novel”节点标注其所属类别。图中虚线框柱的部分“write”节点为关系类表,其余的“aid”和“nid”为实体类表。
43.利用关系类表以及实体类表构建er图(entity-relationship graph,实体关系图)。er图中包含了实体(即数据对象)、关系和属性等3种基本成分。其中,实体(entity):具有相同属性的实体具有相同的特征和性质,用实体名及其属性名集合来抽象和刻画同类实体。属性(attribute):实体所具有的某一特性,一个实体可由若干个属性来刻画。关系(relationship):数据对象彼此之间相互连接的方式称为关系。
44.er图的启发下,本方法根据实体关系对模型进行修改,以保证修改后的模型的合理性。为此,本方法引入了实体-关系图(e-r),它由e-r图演化而来,但省略了属性节点,以强调拓扑特征。e-r图中的节点代表一个实体,边代表其末端节点对应的实体之间的关系。节点和边在ds中都代表一个表。例如,如图3所示,每个“people”表、“author”表和“novel”表,其都对应e-r图中的一个节点,将各实体间的关系确定为边(虚线),并且,将“write”表并入其中的一条边(实线)。为了构建e-r图,手动为ds中的每个表注释一个二进制标记,以区分实体和关系。
45.对于步骤s12,为了进一步增强结构化文本到sql数据,通过基于节点或边进行图变换,得到增强后的第二实体关系图,通过单独的举例,由以下方式进行图变换:实体到属性的图变换、概念到属性的图变换、命名关系到未命名关系的图变换、未命名关系到命名关系的图变换。
46.作为一种实施方式,所述实体到属性的图变换包括:
47.选择所述第一实体关系图中的成对节点确定为源实体和目标实体,其中,所述目标实体包含所述源实体对应表的外键表;
48.基于所述目标实体的属性对所述源实体的属性进行转换,以实现实体到属性的图变换。
49.在本实施方式中,e2a(entity to attribute,实体到属性)对应一种归并节点的e-r转换。选择e-r图中的一对节点,将它们分割为一个源实体和一个目标实体。目标实体对应表是ds中唯一包含源实体对应表的外键表。只要组合是合格的,两个节点都可以被视为源实体。如图4所示的“实体到属性”,对于源实体中的属性,将它们转换为目标实体中的新属性,为了避免语义损失,按照规则重命名属性。
50.作为一种实施方式,所述概念到属性的图变换包括:
51.利用预训练的命名实体识别模型检测所述第一实体关系图中节点的实体对应表的上级类别,基于所述上级类别创建的表存储所述实体的概念;
52.将所述实体的概念替换为所述实体的属性,以实现概念到属性的图变换。
53.在本实施方式中,c2a(concept to attribute,概念到属性)对应一种修改节点e-r变换。与按列的修改不同,将重点放在更改表的角色上。将实体的概念(在ds中通过表名表示)转换为它的属性。首先,使用预训练的ner(named entity recognition,命名实体识别)模型检测实体的高级类别。在图4所示的“概念到属性”示例中,“people”是“singer”的上级类别。然后创建一个附加属性来按规则存储概念。可以使用新的列标识来记录概念“singer”。
54.作为一种实施方式,所述命名关系到未命名关系的图变换包括:
55.为所述第一实体关系图中边对应的关系创建用于更改关系类型的外键,将所述边对应的关系确定为named-命名关系,将所述外键对应的关系确定为unnamed-未命名关系;
56.基于所述named-命名关系对所述unnamed-未命名关系进行修改,以实现命名关系到未命名关系的图变换。
57.在本实施方式中,n2u(named to unnamed,命名到未命名)对应一种修改边e-r变换。将表中表示的关系命名为named,将外键中表示的关系命名为unnamed。例如,在图4所示的“命名到未命名”,表“singer”是一个命名关系,表“song”中的外键辅助表示一个未命名关系,通过在另一个表中创建一个表的外键来更改关系的类型。
58.作为一种实施方式,所述未命名关系到命名关系的图变换包括:
59.基于所述named-命名关系对所述unnamed-未命名关系进行逆向修改,以实现未命名关系到命名关系的图变换。
60.在本实施方式中,u2n(unnamed to named,未命名到命名)也对应一种修改边e-r变换,即已命名到未命名的逆向变换。创建一个关系表,并用两个目标表名称的组合命名它,以存储关系。然后,通过在表中传输外键并在其中创建另一个外键来构建连接,得到图4所示的“未命名关系到命名关系”示例。
61.对于步骤s13,为了进一步将增强后的第二实体关系图恢复为增强的database(d’),利用第二实体关系图确定的抽象语法树,生成结构化数据增强的文本到sql数据,其中,ast(abstract syntax tree,抽象语法树),是用编程语言编写的源代码的抽象语法结构的树表示。树的每个节点表示源代码中出现的一个构造。语法是“抽象的”,因为它并不代表真实语法中出现的每个细节,而只是结构上的、与内容相关的细节。
62.具体的,对于步骤s12中的每个e-r转换,检测ast中的相关子树,并应用相应的规则来更新子树。例如,在将概念应用到属性转换时,在相应的where子树中添加了一个附加的条件子树。最后,用修改后的ast解析修改后的sql。本方法考虑两种类型的合成数据,受影响的和未受影响的。与原始数据相比,受影响的样本包含不同的sql,而未受影响的样本包含相同的sql。根据sql是否涉及受转换影响的ds元素来区分这两种类型。ast更新模块仅用于合成受影响的数据。
63.利用更新后的抽象语法树确定生成的sql数据为:
64.sample(x,d’,y’)
65.question(x):who is the author of harry potter?//《哈利
·
波特》的作者是谁?
66.database(d’)
67.sql(y’):select people.name from people join author on people.id=author.pid join novel on author.id=novel.aid where novel.name=
‘
harry potter’//生成的查询语句。
68.如图5示出了通过不同e-r变换合成的各类合成数据的总数。通过比较原始和结构化数据增强合成(ds,sql)对的执行结果来评估合成质量。平均有90.43%的生成样本保持了一致的执行结果。大约8%的样本由于单元值表示不一致而得到不同的结果。
69.通过该实施方式可以看出,利用少量的标注可以自动生成大量的适用于结构泛化性研究的数据。同时也可以使用本方法生成的结构化的文本到sql数据用作数据增强来提升text-to-sql系统的鲁棒性,进而提升用户语音交互的体验。
70.如图6所示为本发明一实施例提供的一种用于文本到sql任务的数据生成系统的
结构示意图,该系统可执行上述任意实施例所述的用于文本到sql任务的数据生成方法,并配置在终端中。
71.本实施例提供的一种用于文本到sql任务的数据生成系统10包括:实体关系确定程序模块11,图变换程序模块12和数据生成程序模块13。
72.其中,实体关系确定程序模块11用于基于原始文本到sql数据的第一数据库架构图中的关系类表以及实体类表,构建包含实体、关系的第一实体关系图,其中,所述实体确定为所述第一实体关系图的节点,各实体间的关系确定为所述第一实体关系图的边;图变换程序模块12用于至少通过所述第一实体关系图中的节点或边进行图变换,得到第二实体关系图;数据生成程序模块13用于根据所述第二实体关系图生成关系类变化的第二实体关系图,基于所述第二实体关系图确定的抽象语法树,生成结构化数据增强的文本到sql数据。
73.本发明实施例还提供了一种非易失性计算机存储介质,计算机存储介质存储有计算机可执行指令,该计算机可执行指令可执行上述任意方法实施例中的用于文本到sql任务的数据生成方法;
74.作为一种实施方式,本发明的非易失性计算机存储介质存储有计算机可执行指令,计算机可执行指令设置为:
75.基于原始文本到sql数据的第一数据库架构图中的关系类表以及实体类表,构建包含实体、关系的第一实体关系图,其中,所述实体确定为所述第一实体关系图的节点,各实体间的关系确定为所述第一实体关系图的边;
76.至少通过所述第一实体关系图中的节点或边进行图变换,得到第二实体关系图;
77.根据所述第二实体关系图生成关系类变化的第二实体关系图,基于所述第二实体关系图确定的抽象语法树,生成结构化数据增强的文本到sql数据。
78.作为一种非易失性计算机可读存储介质,可用于存储非易失性软件程序、非易失性计算机可执行程序以及模块,如本发明实施例中的方法对应的程序指令/模块。一个或者多个程序指令存储在非易失性计算机可读存储介质中,当被处理器执行时,执行上述任意方法实施例中的用于文本到sql任务的数据生成方法。
79.图7是本技术另一实施例提供的用于文本到sql任务的数据生成方法的电子设备的硬件结构示意图,如图7所示,该设备包括:
80.一个或多个处理器710以及存储器720,图7中以一个处理器710为例。用于文本到sql任务的数据生成方法的设备还可以包括:输入装置730和输出装置740。
81.处理器710、存储器720、输入装置730和输出装置740可以通过总线或者其他方式连接,图7中以通过总线连接为例。
82.存储器720作为一种非易失性计算机可读存储介质,可用于存储非易失性软件程序、非易失性计算机可执行程序以及模块,如本技术实施例中的用于文本到sql任务的数据生成方法对应的程序指令/模块。处理器710通过运行存储在存储器720中的非易失性软件程序、指令以及模块,从而执行服务器的各种功能应用以及数据处理,即实现上述方法实施例用于文本到sql任务的数据生成方法。
83.存储器720可以包括存储程序区和存储数据区,其中,存储程序区可存储操作系统、至少一个功能所需要的应用程序;存储数据区可存储数据等。此外,存储器720可以包括
高速随机存取存储器,还可以包括非易失性存储器,例如至少一个磁盘存储器件、闪存器件、或其他非易失性固态存储器件。在一些实施例中,存储器720可选包括相对于处理器710远程设置的存储器,这些远程存储器可以通过网络连接至移动装置。上述网络的实例包括但不限于互联网、企业内部网、局域网、移动通信网及其组合。
84.输入装置730可接收输入的数字或字符信息。输出装置740可包括显示屏等显示设备。
85.所述一个或者多个模块存储在所述存储器720中,当被所述一个或者多个处理器710执行时,执行上述任意方法实施例中的用于文本到sql任务的数据生成方法。
86.上述产品可执行本技术实施例所提供的方法,具备执行方法相应的功能模块和有益效果。未在本实施例中详尽描述的技术细节,可参见本技术实施例所提供的方法。
87.非易失性计算机可读存储介质可以包括存储程序区和存储数据区,其中,存储程序区可存储操作系统、至少一个功能所需要的应用程序;存储数据区可存储根据装置的使用所创建的数据等。此外,非易失性计算机可读存储介质可以包括高速随机存取存储器,还可以包括非易失性存储器,例如至少一个磁盘存储器件、闪存器件、或其他非易失性固态存储器件。在一些实施例中,非易失性计算机可读存储介质可选包括相对于处理器远程设置的存储器,这些远程存储器可以通过网络连接至装置。上述网络的实例包括但不限于互联网、企业内部网、局域网、移动通信网及其组合。
88.本发明实施例还提供一种电子设备,其包括:至少一个处理器,以及与所述至少一个处理器通信连接的存储器,其中,所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行本发明任一实施例的用于文本到sql任务的数据生成方法的步骤。
89.本技术实施例的电子设备以多种形式存在,包括但不限于:
90.(1)移动通信设备:这类设备的特点是具备移动通信功能,并且以提供话音、数据通信为主要目标。这类终端包括:智能手机、多媒体手机、功能性手机,以及低端手机等。
91.(2)超移动个人计算机设备:这类设备属于个人计算机的范畴,有计算和处理功能,一般也具备移动上网特性。这类终端包括:pda、mid和umpc设备等,例如平板电脑。
92.(3)便携式娱乐设备:这类设备可以显示和播放多媒体内容。该类设备包括:音频、视频播放器,掌上游戏机,电子书,以及智能玩具和便携式车载导航设备。
93.(4)其他具有数据处理功能的电子装置。
94.在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”,不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括
……”
限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
95.以上所描述的装置实施例仅仅是示意性的,其中所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本实施例方案的目的。本领域普通技术人员在不付出创造性
的劳动的情况下,即可以理解并实施。
96.通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到各实施方式可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件。基于这样的理解,上述技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品可以存储在计算机可读存储介质中,如rom/ram、磁碟、光盘等,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行各个实施例或者实施例的某些部分所述的方法。
97.最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1