一种基于改进YOLOV4的辅助智能驾驶目标检测方法
一种基于改进yolov4的辅助智能驾驶目标检测方法
技术领域
1.本发明属于辅助智能驾驶领域,具体涉及一种基于改进yolov4的辅助智能驾驶目标检测方法。
背景技术:
2.近年来随着社会经济的高速发展,汽车保有量的剧增一方面给人们的出行带来了便利,促进了相关行业经济的发展,另一方面汽车的涌入也不可避免的带来了频繁发生的交通事故以及交通拥堵等问题。为解决汽车的使用带来的一系列问题,一方面需要加强道路交通安全管理,另外也需要积极研究现代信息化技术辅助解决道路安全问题。近些年,在大数据的增长以及相关人工智能算法的提升的背景下,以数据驱动辅助驾驶的自动驾驶汽车逐渐走进人们的生活中,但是这些智能驾驶汽车在运行期间也发生了多起交通事故。当前,基于深度学习的道路交通场景目标检测是实现辅助智能驾驶,实现智慧交通等多种应用场景的基础。科学研究表明,多数的交通事故可以在发生前的0.5秒通过操作人员的紧急制动来规避,利用深度学习的计算机视觉方法,可以保证自动驾驶汽车的感知设备及时获取汽车周边环境,并迅速指导汽车的控制系统做出应答,保证汽车的安全行驶。在智能驾驶场景中,安全驾驶的问题依然依赖于汽车设备对于汽车前方障碍物的精确与迅速的捕捉,汽车感知功能能否实现又极度依赖相应的检测算法。
3.目前,智能驾驶场景下的目标检测技术依然面临许多困难和挑战,如行人、车辆等,大小尺度繁多,且道路背景变化极大,又有光线强弱和模糊遮挡等因素干扰,同样的一种物体在不同环境下的检测效果也会存在较大差异,进而可能会导致智能汽车的决策错误,引起交通事故。因此,设计能够抵抗各种困难干扰的目标检测算法进而减少相应事故的发生对于实现真正意义上的智能驾驶具有巨大的推动作用。
技术实现要素:
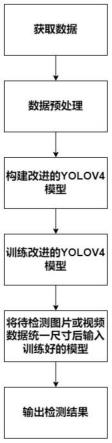
4.为解决以上现有技术存在的问题,本发明提出了一种基于改进yolov4的辅助智能驾驶目标检测方法,该方法包括:获取车辆行驶数据,该数据包括车辆行驶环境信息;对车辆驾驶数据进行预处理;构建改进的yolov4模型,将预处理后的数据输入到训练好的改进yolov4模型中,得到目标检测结果;改进的yolov4模型包括:改进的特征提取网络、softpool池化层以及路径聚合网络;所述改进的特征提取网络包括计算特征提取网络中每个卷积层的3d权值信息,根据3d权值信息将每个卷积层提取的特征进行跨级连接,得到具有深层信息的特征图。
5.优选的,对车辆驾驶数据进行预处理包括对车辆行驶数据进行标注,对标注的数据进行图像增强增强和随机变换处理;其中图像增强包括将四张图像进行随机切割,随后将切割后的四张图像中分别取一部分进行随机组合成为一张图像;随机变换包括对图像进行随机翻转,色域调整以及添加噪声处理,得到预处理好后的数据集。
6.优选的,计算特征提取网络中每个卷积层的3d权值信息的过程包括:对卷积层的
每个神经元定义能量函数;对能量函数添加正则项;对添加正则项的能量函数进行解析;根据解析结果构建最小化能量函数;其中最小化能量函数的倒数为3d权值信息;其中,最小化能量函数中计算出的能量越低,该神经元与周围神经元的区别越大,重要程度越高。
7.优选的,对改进yolov4模型进行训练的过程包括:设定初始学习率和最小学习率;获取训练数据集,对训练数据集进行预处理;将预处理后的数据输入到改进的yolov4模型中进行训练,并采用adam优化算法对模型中的参数进行优化;在模型训练过程中模型的损失函数为回归框损失、置信度损失以及分类损失之和。
8.进一步的,最小学习率为初始学习率的0.01倍。
9.进一步的,回归框损失函数采用siou损失函数,其表达式为:
[0010][0011][0012][0013][0014][0015][0016][0017]
其中,l
box
表示回归框损失,iou为真实框与检测框交并比,δ为距离损失,ω为形状损失,cw和ch分别为真实框和预测框最小外接矩形的宽和高,w,h分别为预测框的宽和高,w
gt
,h
gt
分别为检测框的宽和高。
[0018]
进一步的,置信度损失函数采用交叉熵损失函数,其表达式为:
[0019][0020][0021]
其中,l
conf
为置信度损失函数,为锚框,λ
noobj
表示负样本的边界框,s
×
s指将特征图划分为该大小网格,m为每个网格上锚框数量,ci为预测值,为置信度参数。
[0022]
进一步的,分类损失函数采用交叉熵损失函数,其表达式为:
[0023]
[0024]
其中,l
cla
为分类损失函数;为锚框;pi(c)为预测类别c的概率值;为1表示该边界框用于检测物体,否则为0。
[0025]
本发明的有益效果:
[0026]
本发明通过softpool池化方法替换空间金字塔池化spp模块中的最大池化方法,可以在保持计算和内存高效的情况下,能够更好的保留特征图的重要信息,同时增大感受野,提升模型准确度;本发明在路径聚合网络panet中新增一个特征层进行特征融合,可以融合更多的空间细节信息,可提升辅助驾驶场景中的小目标检测效果;本发明引入通道洗牌的轻量级子空间注意力机制sulsam模块可以提升模型的特征表达能力,提升模型在复杂背景环境中的检测性能;本发明使用坐标注意力机制引导的特征融合caffm模块,本发明模型可以根据特征图的重要程度自适应的对不同层特征进行融合,提升特征图表达效果。
附图说明
[0027]
图1为本发明方法流程图;
[0028]
图2为本发明所述特征提取网络的3d权重生成示意图;
[0029]
图3本发明所述的基于softpool池化的空间金字塔模块示意图;
[0030]
图4为本发明提供的通道洗牌的子空间注意力sulsam模块示意图;
[0031]
图5为本发明的坐标注意力引导的特征融合caffm模块示意图;
[0032]
图6为本发明所述的基于改进的yolov4模型总体结构示意图。
具体实施方式
[0033]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0034]
一种基于改进yolov4的辅助智能驾驶目标检测方法,如图1所示,该方法包括::获取车辆行驶数据,该数据包括车辆行驶环境信息;对车辆驾驶数据进行预处理;构建改进的yolov4模型,将预处理后的数据输入到训练好的改进yolov4模型中,得到目标检测结果。
[0035]
驾驶场景数据集可通过车载行车记录仪,网络下载以及交通视频监控设备等手段获取,数据集包括各种时间段,各种天气条件下的图像,同时需要保证行车环境的多样性。数据集涵盖了阴晴雨雪天气,照明环境差异大以及小目标多,遮挡情况复杂下的各种常见车辆目标信息,行人信息以及交通标志信息。
[0036]
将获取的数据划分为训练集和测试集,其中训练用于对模型的训练,测试集用于对训练好的模型进行测试。具体的划分过程包括:首先通过labelimg软件对数据集图片进行标注,将小汽车,卡车和货车等常见汽车标注为
‘
car’;将行人标注为’pedestrian’;将骑行自行车,摩托车的目标标注为’cyclist’。标注文件用pascalvoc格式保存,即标注文件后缀为
‘
.xml’。将标注好的图片以及标注文件按照voc格式路径放置,同时对数据集进行训练集与测试集划分,划分比例为9:1。
[0037]
对车辆驾驶数据进行数据增强;具体过程包括通过图片随机翻转,调整色度、添加噪声处理。同时用mosaic数据增强方法丰富图像背景信息,即随机每选取4张图像进行分
割,每张图像分割为4个部分,将4张不同部分的图像拼接为1张新图像。本发明所述的数据增强手段均采用现有技术进行。
[0038]
在本实施例中,改进的yolov4模型包括:采用softpool池化方法替换yolov4中空间金字塔池化spp模块中的最大池化方法,在主干特征网络中增加一个特征层构成路径聚合网络panet,在路径聚合网络panet的输入层和输出层分别构建通道洗牌的轻量级子空间注意力模块,在路径聚合网络panet的特征融合层构建坐标注意力机制引导的特征融合caffm模块。
[0039]
在本实施例中,改进的yolov4模型包括:改进的特征提取网络、softpool池化层以及路径聚合网络;所述改进的特征提取网络包括计算特征提取网络中每个卷积层的3d权值信息,根据3d权值信息将每个卷积层提取的特征进行跨级连接,得到具有深层信息的特征图。
[0040]
图2为本发明提供的特征提取网络中的卷积层生成3d权重特征的示意图,首先根据卷积层为卷积层上每一个神经元定义一个能量函数,其表达式如下:
[0041][0042]
其中分别为t和xi的线性变换,而t和xi表示输入特征图x∈rc×h×w单个通道中的目标神经元和其他神经元,i是二维空间维度上的索引,m=h
×
w为二维空间平面上神经元数量,w
t
和b
t
为权重和偏差,上式中所有值均为标量。当等于y
t
,并且所有其他的为yo时上述表达式可以得到最小值。简单起见,用二值标签,同时添加正则项,其能量函数则如下表达式:
[0043][0044]
其中,e
t
(.)表示正则化后的能量函数,w
t
表示权重,b
t
表示偏差,y表示二值标签,即取-1或者1(属于单个通道其他神经元xi时为-1,属于单个通道当前神经元t时为1);t表示单个通道的目标神经元,xi表示单个通道的其他神经元,λ为常量系数,默认取0.0001;m表示二维空间平面上神经元数量。
[0045]
进一步的可以得到如下的解析解:
[0046][0047][0048]
其中,因此最小化能量函数可以表述为以下表达式:
[0049][0050]
上述表达式中能量越低,神经元t与周围神经元的区别越大,重要性越高。因此,神
经元的重要性可以通过得到。
[0051]
根据卷积层提取特征图并结合所述的能量最小函数,可以得到本发明所述的3d权重特征,通过将3d权重特征跨级输出,即得到本发明所述的基本卷积块csbm,定义基本卷积块csbm输入特征图为xi,输出为xo,则其关系如下:
[0052][0053]
其中的mish指mish激活函数,batchnorm为批量归一化,conv2d指卷积操作,sigmoid为sigmoid激活函数,c为特征图通道数。
[0054]
如图3所示为本发明提供的基于softpool的池化方法的空间金字塔结构,定义大小为c
×h×
w的特征图a的局部区域r,r为二维空间区域,大小等同于池化核大小,其池化输出记为softpool即根据特征值非线性的计算区域r的特征值:
[0055][0056]
权重wi用来保证重要特征的传递,区域r内的特征值在反向传递时会有预设的最小梯度。在得到权重wi后,通过加权区域r内的特征值将会得到区域内对应位置的特征:
[0057][0058]
本发明所述的基于softpool池化的空间金字塔模块其池化核大小分别选取5、9、13和1,则将会达到四种不同比例感受野的特征图,将所述的四种特征图按照通道方向堆叠后最为模型下一层的输入。
[0059]
如图4所示为本发明所述的通道洗牌的子空间注意力机制sulsam模块:首先通过洗牌的方式随机重组特征图通道顺序,然后学习每个特征子空间的个体注意力特征映射,同时在多尺度,多频率特征学习的同时实现跨通道信息的高效学习。具体的,定义一个大小为h
×w×
m的特征图,h,w,m分别为特征图的高、宽和通道数,记特征图为x,首先对x通道方向进行洗牌重组,随后对通道方向特征进行分组,假定分组数为g,即则每组特征图的通道数为g,满足:
[0060]
m=g
×g[0061]
针对各个分组的特征图,对输入的特征分别用1x1的深度可分离卷积、3x3最大池化、1x1的逐点卷积以及softmax激活函数处理。对于第i组的特征,则所述过程表示为:
[0062]ai
=softmax(pw(maxpool(dw(xi)))
[0063]
其中的ai表示为第i组特征图xi生成的注意力特征图,进一步的对将各分组注意力特征图与输入特征进行融合,其数学关系如下:
[0064][0065]
最终对各分组融合后的特征进行通道方向堆叠concat,即可以得到本发明所述的通道洗牌的子空间注意力机制sulsam模块输出的特征图,即:
[0066]
[0067]
在本实施例中,注意力特征图需满足σ
m,nai
(m,n)=1,其中的m,n为特征图的二维坐标位置信息。
[0068]
如图5所示为本发明提供的坐标注意力机制引导的特征融合caffm模块;为了使模型能够获取更大区域的信息而避免引入大的开销,本发明通过嵌入位置信息到通道注意力机制中,同时根据注意力特征权重的不同来重新融合相邻特征层的特征。
[0069]
具体的,首先确定输入特征的注意力特征,利用两个一维的全局池化操作将延水平方向和垂直方向的输入特征聚合为两个单独的“方向感知特征图”。然后将具有嵌入特定方向信息的两个特征图分别通过sigmod激活函数编码为注意力特征图,每个注意力图都延一个空间方向捕获输入特征图的远近距离依存关系。位置关系因此可以保存在生成的注意力特征中。最后可根据生成的注意力特征重新引导相邻特征的融合。
[0070]
特征融合caffm模块对特征图进行处理的过程包括:定义相邻特征为f1和f2,其中f1为尺寸大的浅层特征,f2为尺寸小的深层特征并且已经通过2倍上采样调整其尺寸与f1一致。首先对两特征进行逐像素相加得到输入坐标注意力中的输入特征f
′
:
[0071][0072]
随后使用尺寸为(h,1)和(1,w)的池化核分别延水平坐标以及垂直坐标每个通道进行编码,则高度为h的第c通道特征表示为:
[0073][0074]
同样的到了,宽度为w的第c通道的输出表示为:
[0075][0076]
通过信息嵌入中的变换后,将上述特征进行空间维度堆叠操作后再通过卷积操作,即:
[0077]
f=relu(conv(cat[zh,zw]))
[0078]
在上述操作基础上需要进一步通过分块处理将特征f分为尺寸大小与zh和zw相同的两个特征图。记为fh和fw。则最终的包含位置特征的注意力特征图分别表示为:
[0079]gh
=sigmoid(conv(fh))
[0080]gw
=sigmoid(conv(fw))
[0081]
根据上述注意力特征表达式构建本发明所提的坐标注意力引导的特征融合方法,融合后的特征记为f
″
,其数学描述如下:
[0082][0083]
上述表达式可自适应的确定不同特征层重要程度,进而可以对不同的特征进行融合时其权重进行控制,提升模型特征表达效果。
[0084]
图6为本发明所述的基于改进yolov4的辅助智能驾驶场景的目标检测方法总体结构图;首先本发明所提供方法主干网络的基本结构为scsp结构,而scsp由一个残差结构以及本发明所述的csbm组成的残差块构成,本发明的基于改进yolov4的辅助智能驾驶场景的目标检测方法其主干部分由多个scsp结构组成,具体的,各scsp结构中的残差块的数量分别为1,2,8,8,4。在特征提取网络的三个有效特征层上,通过softpool池化方式输出多感受
野特征;相邻特征通过本发明所述的坐标注意力引导的方式caffm进行特征融合;同时,路径聚合网络中的卷积层改进为本发明图6所示的csbl卷积层以进行特征提取。
[0085]
对改进yolov4模型进行训练的过程包括:设定初始学习率和最小学习率;获取训练集,对训练集中的数据进行预处理,将预处理后的数据输入到改进的yolov4模型中进行训练,并采用adam优化算法对模型中的参数进行优化;在模型训练过程中模型的损失函数为回归框损失、置信度损失以及分类损失之和。
[0086]
具体的,设定在adam优化算法中,初始学习率设定为0.001,最小学习率设置为初始学习率的0.01倍。每个批次的训练样本中mosaic数据增强概率为0.5。损失函数由回归框损失,置信度损失、分类损失三项之和。
[0087]
回归框损失函数采用siou损失函数,其表达式为:
[0088][0089][0090][0091][0092][0093][0094][0095]
其中,l
box
表示回归框损失,iou为真实框与检测框交并比,δ为距离损失,ω为形状损失,cw和ch分别为真实框和预测框最小外接矩形的宽和高,w,h分别为预测框的宽和高,w
gt
,h
gt
分别为检测框的宽和高。
[0096]
置信度损失函数采用交叉熵损失函数,其表达式为:
[0097][0098][0099]
其中,l
conf
为置信度损失函数,为锚框,λ
noobj
表示负样本的边界框,s
×
s指将特征图划分为该大小网格,m为每个网格上锚框数量,ci为预测值,为置信度参数。
[0100]
分类损失函数采用交叉熵损失函数,其表达式为:
[0101]
[0102]
其中,l
cla
为分类损失函数;为锚框;pi(c)为预测类别c的概率值;为1表示该边界框用于检测物体,否则为0。
[0103]
在本实施例中,待检测图片输入到已经训练好的改进的yolov4模型中,首先模型会将待检测图片调整到统一尺寸,如果待检测图片尺寸小于设定尺寸,则将待检测图片周边添加灰条,如果大于设定尺寸,则对待检测图片进行压缩。模型的输出将会得到三种尺寸的检测结果,其尺度分别为(13x13),(26x26)和(52x52),模型最终对三个尺度的检测结果为[(13*13)+(26*26)+(52*52)]*3个预测候选框,即10647个。假设需要检测的遥感目标有10个类别,则训练后的遥感目标检测模型会将输出的结果表示为二维向量(10647,15)。其中的15包括了目标类别数10,检测框的位置参数(x,y,w,h)以及1个置信度参数。随后将通过非极大抑制算法过滤预测值低于设定阈值的检测框,保留下来的检测框即为最终的检测结果。
[0104]
以上所举实施例,对本发明的目的、技术方案和优点进行了进一步的详细说明,所应理解的是,以上所举实施例仅为本发明的优选实施方式而已,并不用以限制本发明,凡在本发明的精神和原则之内对本发明所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1