一种面向列车传动系统的类脑持续学习故障诊断方法
本发明属于轨道交通安全保障领域,具体涉及一种面向列车传动系统的类脑持续学习故障诊断方法。
背景技术:
1、轨道车辆传动系统主要包括牵引电机、齿轮箱、轮对轴箱等,起到传递牵引力实现车辆行进的重要作用。由于列车运行环境复杂多变,传动系统不可避免地发生各类故障,给轨道车辆运行带来安全风险。当前列车传动系统的检修通常以里程为依据,达到一定里程数后,对各部件进行维修和更换,这种基于经验的“定期修”往往伴随着过维修和欠维修的问题。随着多源全息感知和智能物联技术的发展,基于深度学习的智能故障诊断技术通过对监测数据的自动辨识实时发现故障,在轨道交通安全保障和智能运维领域受到青睐,引发了从传统的“定期修”到费效比更高的“按需修”的变革。然而,现有的基于深度学习的智能诊断模型在训练完成后,可诊断的故障类型便被固定,如果想增加可诊断故障类别,则需要重新训练模型。轨道车辆传动系统的部件繁多、型号各异,很难预先得到全部潜在故障类型的监测数据,而受制于计算和存储资源、数据传输等限制重新训练模型在很多工程场景下无法实现,限制了智能诊断模型的应用潜力。目前,针对列车传动系统故障诊断问题,缺乏一种类脑持续学习范式,使诊断模型部署后,面对非独立同分布的新故障数据集时,无须从头训练,通过模仿人脑神经突触的学习与记忆机制,在保持既有故障诊断能力的同时,拓展可诊断故障类型的边界。
技术实现思路
1、为了克服现有技术的局限,本发明的目的在于提出一种面向列车传动系统的类脑持续学习故障诊断方法,诊断模型部署后可以在不依赖人为重新训练的情况下,对渐进式获取的新类别故障数据集进行持续学习,从而拓展可诊断故障类型的边界。该方法具有如下优点:1)无须存储不断膨胀的故障数据,仅利用少量额外存储空间保存典型旧类别故障数据就可以有效缓解因新知识与旧知识分布不同而造成的“灾难性遗忘”问题;2)模型随着类脑持续学习进入新阶段而不断生成新的类突触表征结构,在多目标优化指导下,专注学习新类特征,面对故障特征模态多变的列车传动系统故障诊断问题时,不会因欠参数而引发诊断性能退化;3)在模型新表征结构生成过程中,嵌入了与学习同步的剪枝,可根据不同阶段学习任务的难度自适应地调节表征结构规模,避免结构化冗余的加剧。
2、为了达到上述目的,本发明采取的技术方案为:
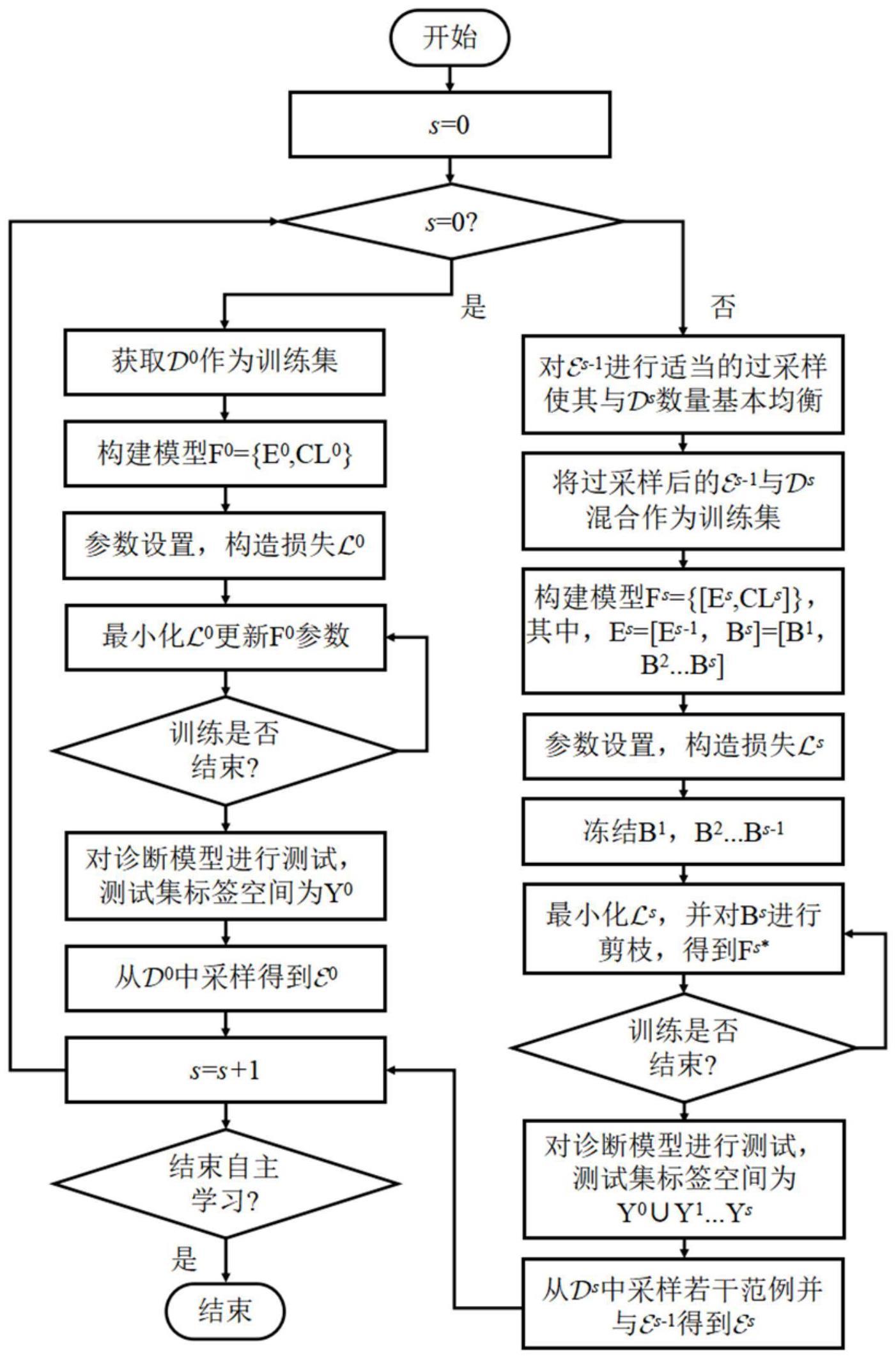
3、一种面向列车传动系统的类脑持续学习故障诊断方法,包括以下步骤:
4、1)设当前持续学习阶段s=0,获取既有的轨道车辆传动系统故障数据集其中,表示多源传感数据,表示对应的标签,y0表示自主学习初始阶段的轨道车辆传动系统健康状态标签集合,n0表示所包含的样本个数;
5、构造智能诊断模型f0(x|θ0),其中,f0(x|θ0)由卷积堆叠的表征学习子网e0(x|ξ0)和由softmax函数激活的全连接层构造的分类子网cl0(x|ψ0)组成;θ0,ξ0,ψ0分别是f0,e0,cl0的可训练参数,且θ0={ξ0,ψ0};
6、设置损失函数训练代数t,学习率η,训练批次bs,对模型可训练参数进行如下优化:
7、
8、
9、其中,l()为指示函数,yi和分别是当前样本的健康状态标签和模型预测概率,c表示y0中标签;
10、优化流程如下:
11、i.输入θ0、f0、损失函数训练代数t、学习率η;
12、ii.初始化θ0
13、iii.利用反向传播算法训练模型,基于下式将θ0old更新为θ0new,
14、
15、iv.重复iii直到训练代数达到t;
16、v.得到训练完成的模型f0*(x|θ0*),其中优化后的可训练参数为θ0*;
17、优化完成后,从中采样得到少量样本示例ε0保存到单独的存储空间中,其余样本则删除以释放存储空间;
18、2)设当前持续学习阶段s=1,获取新一阶段的列车走行系统故障数据集其中,表示多源传感数据,表示对应的标签,y1表示阶段s=1的轨道车辆传动系统健康状态标签空间,且n1表示所包含的样本个数;
19、构造智能诊断模型f1(x|θ1),其中,f1(x|θ1)由表征学习子网e1(x|ξ1)和分类子网cl1(x|ψ1)组成,e1(x|ξ1)由之前阶段的表征结构分支e0(x|ξ0)和当前阶段新生长的表征学习分支b1(x|ξ1)组成,e1={e0,b1},θ1,ξ1,ψ1分别是f1,e1,cl1的可训练参数,且θ1={ξ1,ψ1};
20、采用训练同步的动态剪枝策略,具体地:
21、2.1)获取b1内各卷积层后批归一化层中的缩放因子γj,j=1,2,...,l,l为批归一化层总数,计算各卷积核对应的缩放因子对于该层缩放因子集合的对数概率,如下式:
22、
23、其中,yk是第k采样通道的缩放因子,ym是第m采样通道的缩放因子;
24、2.2)在各批归一化层内,基于pj进行若干次无放回的采样直到被采样通道对应的之和大于等于设定的阈值τ,并根据将采样通道序号写入数组scj中,如下式:
25、scj=sampling(pj)until∑p(scj)≥τ
26、2.3)根据采样得到的scj,进行二值化编码得到剪枝掩码向量mj,具体地,被采样通道赋值1,未被采样通道赋值0;
27、2.4)将mj与对应的特征图进行通道维度乘法,完成剪枝,如下式:
28、
29、其中,zj和分别是第j层卷积层输出的特征图和剪枝后的特征图,表示通道维度乘法;
30、设置损失函数训练代数t,学习率η,训练批次bs,对模型可训练参数进行如下优化:
31、
32、如下所示:
33、
34、
35、
36、
37、其中,构成了模型优化的多目标损失函数,分别表示诊断分类交叉熵损失、辅助损失和稀疏损失,和是辅助损失和稀疏损失的权重,和分别是当前样本属于过去学习阶段或当前学习阶段故障类的二值化标签和辅助分类网络的预测结果,||·||2表示二范数;
38、优化流程如下:
39、i.输入θ1、f1,损失函数训练代数t,学习率η,剪枝阈值τ={τ1,τ2,...};
40、ii.初始化θ1
41、iii.如果当前训练代数大于20且可被10整除,则执行iv-vii,否则执行vi-vii
42、iv.执行2.1)-2.4)剪枝过程
43、v.剪枝阈值根据序列τ={τ1,τ2,...}下调
44、vi.利用反向传播算法训练模型,具体地,根据下式更新θ1
45、
46、vii.跳回至iii直到训练代数达到t;
47、viii.得到训练完成的模型f1*(x|θ1*),其中优化后的可训练参数为θ1*;
48、优化完成后,从中采样得到少量样本示例,并与ε0合并得到ε1,保存到单独的存储空间中,其余样本则可以删除以释放存储空间。
49、本发明的有益效果为:
50、本发明能够在诊断模型部署后对序列形式的新故障数据集进行类脑持续学习,从而不断拓展其可诊断故障的范围,并且具备如下优点,1)无须基于全历史数据集对模型进行重训练,利用少量旧类别示例配合既有模型结构的冻结就可以有效缓解新知识与旧知识分布不同造成的“灾难性遗忘”问题;2)模型随着类脑持续学习进入新阶段而不断生成新的类突触表征结构,在多目标优化指导下,可以高效学习新类特征,不会因特征模态多样造成欠参数问题继而引发诊断性能退化;3)在模型新表征结构生成过程中,嵌入了与学习同步的剪枝,可根据不同阶段学习任务的难度自适应地调节表征结构规模,避免模型的超冗余。
- 还没有人留言评论。精彩留言会获得点赞!