多源信息融合增强的知识图谱表示学习方法
1.本发明属于知识图谱技术领域,涉及一种多源信息融合增强的知识图谱表示学习方法。
背景技术:
2.互联网科技的快速发展使得互联网中的信息呈爆炸式增长,如何更好的利用互联网中的知识变得越来越重要,知识图谱表示学习的作用是将知识转换为一种计算机能理解并处理的数据结构。知识图谱表示学习的目标是将实体和关系表示为低维稠密的实值向量,在低维空间中高效计算实体和关系的语义联系。与传统的表示学习方法相比,知识图谱表示学习方法由于向量表示,能够更好的进行计算,能有效地解决数据系数问题,使知识获取、融合以及推理的性能得到提升。知识图谱表示学习的方法大体上可以分为两类:基于语义平移的嵌入模型和基于语义匹配的嵌入模型。基于语义平移的嵌入模型是利用词向量在语义空间具有平移不变性对语义相似度进行建模,通过计算头实体根据关系进行平移的向量和尾实体之间的距离来进行知图谱的表示学习。而基于语义匹配的嵌入模型是通过相似性函数来衡量事实的合理性,计算每个实体和关系在同一个向量空间表示中的潜在语义相似度来捕捉知识潜在语义信息的方法。由于语义平移模型的效率和准确性更优,近些年有很多的工作通过研究语义平移模型去解决知识图谱表示学习中的问题,因此,基于语义平移的嵌入模型又可以进一步分为:基于事实三元组的嵌入模型以及融合多源信息的知识图谱嵌入模型。
3.与传统的知识表示方法不同,基于事实三元组的语义平移模型将头实体和尾实体通过关系联系起来的过程视为翻译平移的过程,然后用一个得分函数来衡量每个三元组的合理性。由于基于语义平移的模型将实体和关系映射到低纬稠密向量空间,在翻译的过程中计算效率得到了提升,相比于传统的知识表示学习方法,这类方法计算简单、准确率高,同时更容易应用到更大规模或者更加复杂的知识图谱中,因而在最近几年受到了更多研究者的关注。但也由于最初的语义平移模型简单,导致其无法对知识图谱中的复杂关系进行建模,因此一些研究者在语义平移模型的基础上,将实体映射到关系的超平面或者关系空间进行表示学习。另外,基于语义平移模型的表示学习方法都是在传统的欧几里得空间下进行的,但是随着知识图谱表示学习模型在近些年的发展,许多基于语义平移模型的表示学习方法已经不局限于欧几里得空间,他们将语义平移理论扩展到了球形空间、双曲空间以及复数空间。相关的工作证明了不同的空间对实体中语义信息的保留的侧重点是存在差异的。
4.以上这些方法能够分别从不同的映射空间来提升知识图谱的表示能力,但它们忽略了知识图谱自身的结构信息和丰富的外部语料库信息。因此,一些研究学者曾提出利用知识图谱中三元组事实以外的信息,来帮助构建更加精准的知识表示模型,这些多源信息包含:实体类别信息、外部文本语料信息以及关系路径信息等,这些信息主要用来丰富实体和关系的语义信息,充分利用这些多源信息对于降低实体与关系之间的模糊程度,进而提
高推理预测的准确度至关重要。目前,随着神经网络和注意力机制在自然语言领域的应用和发展,如何利用好这些丰富的外部语料库信息,以提升知识图谱表示学习能力,成为目前研究的重点。
技术实现要素:
5.本发明的目的在于提出一种多源信息融合增强的知识图谱表示学习方法,该方法通过利用不同的信息对知识图谱实体关系表示能力,结合多模态信息融合技术,以强化知识图谱表示学习的能力,进而有效地提升知识图谱表示的准确性以及处理复杂关系的能力。
6.本发明为了实现上述目的,采用如下技术方案:本发明提供了一种多源信息融合增强的知识图谱表示学习方法,该方法首先利用注意力机制对知识图谱实体和关系进行外部文本增强,以提升知识图谱实体和关系的语义信息;然后通过双曲空间能够捕获自身结构的特性,利用双曲空间来进行低维度知识表示,以提供知识表示的表达能力;再利用多模态信息融合技术,将外部文本信息和双曲空间中捕捉的自身结构信息进行融合;最后,利用三元组自身的位置信息和上述多源信息增强的信息作为约束,通过双层注意力网络动态的聚合每个实体在不同三元组上下文的信息,在最终的得分计算过程中,通过交叉熵来计算正确三元组和预测三元组之间的损失值,得到实体的最终表示。
7.本发明具有如下优点:如上所述,本发明述及了一种多源信息融合增强的知识图谱表示学习方法,该方法利用信息融合技术,将外部语义信息和双曲空间信息融合到一起进行知识增强,同时通过双层自注意力网络计算每个实体在不同上下文的情况下所表示的信息来进行最终的知识图谱表示。本发明通过综合的利用不同信息的特性,可以进一步增强知识图谱表示学习的能力,有效提升知识图谱表示的准确性和处理复杂关系的能力,提高知识图谱对下游任务的应用能力。
附图说明
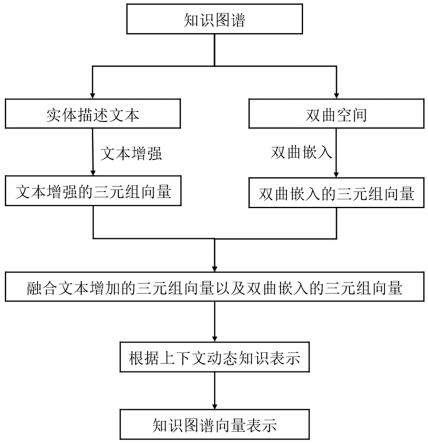
8.图1 为本发明实施例中多源信息融合增强的知识图谱表示学习方法的流程图。
9.图2为本发明实施例中多源信息融合增强的知识图谱表示学习方法的模型框架图。
10.图3 为本发明实施例中多源信息融合的具体流程图。
11.图4为本发明方法在基准数据集上预测知识图谱中头实体的hits@10得分对比图。
12.图5为本发明方法在基准数据集上对不同步骤进行消融后的mrr、hits@1、hits@3、hits@10的得分对比图。
具体实施方式
13.下面结合附图以及具体实施方式对本发明作进一步详细说明:如图1和图2所示,多源信息融合增强的知识图谱表示学习方法,包括如下步骤:步骤1. 通过实体链接工具将外部语料库中的实体描述信息和知识图谱中实体链
接起来,将链接后的实体描述文本输入自注意力神经网络,得到文本增强的三元组向量。
14.知识图谱中实体通过实体描述文本的增强,能够丰富知识图谱实体和关系的语义信息。
15.该步骤1具体为:步骤1.1. 实体链接工具,将实体和外部语料库中的实体描述信息进行链接,将链接后的实体描述文本通过词嵌入模型获得最初的实体描述文本的向量表示。
16.外部语料库选用wikipedia的数据集,知识图谱数据集采用wordnet的子集wn18、wn18rr和freebase的子集fb15k和fb15k-237。
17.通过实体链接工具链接之后的实体描述文本集合表示为t={s1, s2,
…
, sn}。
18.其中,sn表示第n个实体的实体描述文本。以sn为例,sn=(w1,w2,
…
,wn)是一个实体描述文本,由许多单词构成,wn表示实体描述文本中第n个词的词向量。
19.步骤1.2. 在实体描述文本向量的句首前面增加一个词向量w0,将这个词向量记作第0个词向量,实体描述文本的词向量从文本第1个词开始计算。
20.将添加词向量w0后的实体描述文本向量,输入自注意力神经网络层。
21.计算实体描述文本中词与词之间的语义性,将经过自注意力神经网络层后的第0个词向量,作为该实体描述文本描述的实体的最终的向量表示,即文本增强的三元组向量。
22.在实体描述文本向量输入自注意力神经网络层前,给每个实体描述文本的词向量添加了相应的位置信息,即位置编码w
ipos ,添加位置编码w
ipos
信息后的向量为:w
i0
= w
iele + w
ipos
。
23.其中,下表i表示第i个词向量。
24.w
i0
表示添加位置编码信息后的词向量,w
iele
表示词向量,w
ipos
表示位置编码。
25.将添加位置编码信息后的词向量,输入到一个l层的transformer编码器进行编码,每一层的输出作为下一个编码器的输入,具体的计算公式如下:w
il
=encoder(w
il-1
)。
26.其中,w
il
、w
il-1
分别表示输入元素在第l层、第l-1层编码器的输出。
27.encoder表示transformer编码器,l表示编码器的个数。
28.最后取第0个词向量在第l个编码器的输出作为文本增强的三元组向量,即:v
t
= w
0l
。其中,v
t
表示文本增强的三元组向量,w
0l
表示第0个词向量在第l个编码器的输出。
[0029]vt
=( v
th
,v
tt
,v
tr
);其中,v
th
、v
tt
和v
tr
分别表示头实体、尾实体和关系经过文本增强后的头实体向量、尾实体向量以及关系向量。
[0030]
encoder部分采用了自注意力机制,自注意力机制会将输入的每个词向量分成三个相同的部分query向量、key向量和value向量,用于计算词与词之间的语义性。
[0031]
其中query向量和key向量用来计算词与词之间的权重,value向量用来进行值传递。
[0032]
本实施例中用多个自注意力模块堆叠在一起,形成多头自注意力模块,这些模块输出的向量会被拼接在一起,通过线性映射变成模型最终输出的长度。
[0033]
自注意力机制的计算可以用如下公式进行表示:encoder(q,k,v)=softmax(q
·kt
/)
·
v,softmax为激活函数。
[0034]
其中,q、k、v分别表示query向量、key向量、v为value向量,dk表示嵌入的维度。
[0035]
本发明利用深度神经网络模型,构建基于自注意力机制的神经网络,同时利用外部文本语料库中丰富的实体描述文本,提升了知识图谱中实体和关系的语义信息。
[0036]
步骤2. 将知识图谱中的实体和关系映射到双曲空间中,利用双曲空间的空间特性捕捉知识图谱自身的结构信息得到知识双曲向量表示,即双曲嵌入的三元组向量。
[0037]
本发明采用双曲空间进行知识图谱表示学习,其好处在于:首先双曲空间曲率小于1,在半径相同的情况下双曲空间具有更大的容纳空间,表明其能用相同的维度表示更多的语义信息。其次,双曲空间的特性,决定了其可以更精确的表示具有层次结构和拓扑结构的数据,知识图谱的实体和关系就是具有层次结构的数据。
[0038]
本发明用小维度捕捉知识图谱的自身结构信息,以降低最终的实体和关系的嵌入维度。
[0039]
由于双曲空间映射中将实体进行关系的转换会导致高复杂度的开销,而本发明只是为了挖掘只是图谱自身的结构信息,为了减少开销,本发明将双曲空间的映射看作是一种平移的过程,利用双曲空间中的距离和平移计算函数来进行表示,即双曲transe的方法。
[0040]
下面对利用双曲空间的空间特性捕捉知识图谱自身的结构信息的过程进行详细说明:基于语义平移的方法将知识图谱中的实体和关系用词嵌入模型进行初始化,然后通过双曲空间的距离和平移公式计算,并不断训练得到双曲嵌入的三元组向量。
[0041]
在模型训练的过程中计算头实体经过关系平移后的向量和尾实体之间的距离。
[0042]
在训练的过程中有正样本和负样本;正样本表示真实存在的事实三元组,负样本表示不存在的事实三元组,负样本一般通过随机替换头实体或尾实体得到。
[0043]
训练过程中希望真实存在的事实三元组的距离值应小于不存在的事实三元组。
[0044]
当训练到损失函数趋于平稳的时候得到双曲嵌入的三元组向量。
[0045]
其中,双曲空间的距离d(u,v)公式如下:d(u,v)=arcosh(1+2|| u-v ||2/[(1-|| u ||2) ·
(1-|| v||2)])。
[0046]
其中,u和v分别表示双曲空间中的两个向量,在本发明中用于计算头实体和尾实体之间的距离。双曲空间中的平移公式是:u ꢀ
v=[1+2(u,v)+ || v||2·
u+(1-|| u ||2)
·
v]/[1+2(u,v)+ || v||2·
|| u ||2]。
[0047]
最终的得分函数是:s(e)=d(v
hh
ꢀꢀvhr
, v
ht
)。
[0048]
其中,v
hh
、v
ht
和v
hr
分别表示头实体、尾实体和关系在双曲空间的向量表示。
[0049]
损失函数是:loss=∑
(e)∈g
∑
(e’)∈g
’ [γ+ s(e)
‑ꢀ
s(e’)]
+ 。
[0050]
其中,[
·
]
+
表示计算结果大于0的时候才取该数字,小于0则不使用该数字。
[0051]
e是正样本,g是正样本的集合,e’是负样本,g’是负样本的集合,γ是偏置函数。s(e)表示正样本通过得分函数得到的值,s(v’)表示负样本通过得分函数得到的值。
[0052]
本发明构建基于语义平移的表示学习模型,将实体映射到双曲空间中进行知识图谱嵌入,利用双曲空间曲率为-1以及其捕捉自生结构信息的特性,以加强知识图谱自身的表示能力。
[0053]
步骤3. 将文本增强的三元组向量和双曲嵌入的三元组向量进行向量拼接,将拼接后的实体向量通过多层神经网络进行融合,训练获得融合后的实体关系的三元组向量。
[0054]
如图2所示,本实施例中多层神经网络包括前馈神经网络以及转换神经网络。
[0055]
首先将文本增强的三元组向量以及双曲嵌入的三元组向量进行向量拼接,将拼接后的三元组向量作为输入向量经过前馈神经网络获得自融合的三元组向量。
[0056]
该向量具有实体描述的语义信息和双曲空间的低维且能够捕捉自身结构信息的特征。
[0057]
然后自融合的三元组向量通过转换神经网络重新构建之前拼接的三元组向量。
[0058]
最后计算重新构建的三元组向量与最初拼接的三元组向量之间的均方差,将该均方差作为损失函数,训练得到融合实体描述文本和双曲空间信息的实体关系表示向量。
[0059]
如图3所示,输入向量在多层神经网络中的处理过程如下:设拼接后的三元组向量为(v
fh
,v
ft
,v
fr
),首先将拼接后的三元组向量作为输入向量经前馈神经网络获得自融合的三元组向量(v
eh
,v
et
,v
er
)。
[0060]
其中,v
fh
、v
ft
、v
fr
分别表示拼接后的头实体向量、尾实体向量和关系向量;v
eh
、v
et
、v
er
分别表示经过前馈神经网络生成的头实体向量、尾实体向量和关系向量。
[0061]
然后自融合的三元组向量(v
eh
,v
et
,v
er
)通过一个转换神经网络,通过该转换神经网络重新构建之前拼接的三元组向量(v’fh
,v’ft
,v’fr
)。
[0062]
其中,v’fh
,v’ft
,v’fr
分别表示转换神经网络生成的头实体向量、尾实体向量和关系向量。
[0063]
最后计算重新构建的三元组向量(v’fh
,v’ft
,v’fr
)与最初拼接的三元组向量(v
fh
,v
ft
,v
fr
)之间的均方差,并将该均方差作为损失函数lossf。
[0064]
其中,lossf=|| v’fh
ꢀ‑ꢀvfh ||2,||
·
||2是均方差的计算函数。
[0065]
通过训练多层神经网络得到融合后的实体关系的三元组向量。
[0066]
为了后续表述方便,利用(h’,t
’ꢀ
,r’)替代(v
eh
,v
et
,v
er
)来表述融合多源信息的三元组。h’、t
’ꢀ
、r’分别表示融合多源信息之后的头实体向量、尾实体向量以及关系向量。
[0067]
本发明通过构建自动信息融合网络,将文本增强之后的信息和双曲空间中的信息聚合,在下述步骤4中将融合后的信息作为知识图谱三元组上下文嵌入的约束。
[0068]
步骤4. 将融合后的实体关系的三元组向量视为一个句子,通过双层自注意力网络动态的计算每个实体和关系在不同上下文下的特征得到实体的最终表示,即知识图谱向量表示。
[0069]
该步骤4的具体过程为:将融合后的实体关系的三元组向量视为一个句子,将头实体或尾实体隐藏,通过双层自注意力网络计算每个实体在不同上下文的情况下所表示的信息预测出头实体或尾实体。
[0070]
计算预测出的实体与隐藏真实实体之间的交叉熵,并将该交叉熵作为损失函数,通过训练双层自注意力网络,得到实体的最终表示,即知识图谱向量表示。
[0071]
如图2所示,双层自注意力神经网络由自注意力层、求和与均一化层、前馈神经网络层等结构组成。输入向量在双层自注意力神经网络中的具体处理过程如下:首先对输入向量进行位置编码,得到最终的输入序列,然后将输入序列输入到注意力层进行计算,注意力层会将输入序列的每个向量分解为query,key,value三个向量。
[0072]
其中,query向量和key向量用来计算词与词之间的权重,value向量用来进行值传
递。
[0073]
将经过自注意力层后的序列和输入序列进行求和和均一化的操作,并且输入前馈神经网络,最后再通过一次求和与均一化操作后进行输出。
[0074]
上述的前馈神经网络和均一化操作都是为了提高模型的学习能力。
[0075]
经过双层自注意力神经网络层,获得了具有上下文信息的向量表示,即最终的预测值。
[0076]
然后将输入向量作为先验证信息,将预测出来的值作为后验证信息,计算二者的交叉熵,来对预测出来的值进行优化,最终预测出来的值作为最终的向量表示。
[0077]
通过多层的网络传递来学习知识图谱三元组在不同的上下文之间的信息。
[0078]
以头实体为例,最终的表示结果为:h
i0
= h’+ h’pos
;
……hil
= encoder(h’il-1
)。
[0079]
其中,h
i0
为注意力层的输入向量,h’是融合的三元组中的头实体向量,h’pos
是头实体的位置编码向量,h
il
、h
il-1
分别表示第i个单词在第l层、第l-1层编码器的输出结果。
[0080]
p1=softmax(w
·
f(h
1n
));
……
pn=softmax(w
·
f(h
nn
))。
[0081]
其中,p1为将t隐藏之后得到的预测的实体,pn为将h隐藏之后得到的预测的实体,w是权重矩阵,f(
·
)为前馈神经网络,softmax为激活函数,此处,n=3。
[0082]h1n
、h
nn
分别表示头实体经过双层注意力网络后的头实体向量以及尾实体经过双层注意力网络后的头实体向量,n表示经过 n个双层神经网络。
[0083]
图2中x1、x2和x3分别表示输入的头实体向量、关系向量和尾实体向量。p1和p3分别表示头实体的预测向量以及尾实体的预测向量,n*表示n个双层神经网络堆叠。
[0084]
loss=-∑
t y
t
lot
pt
。
[0085]
loss表示损失函数,y
t
和pt分别是t层的one-hot编码和预测的编码p1。
[0086]
本发明通过双层自注意力神经网络,动态的聚合融合后的知识图谱三元组信息,通过计算动态计算之后的三元组和初始三元组之间的交叉熵,提升了知识图谱表示学习表示的准确性和处理知识图谱复杂关系的能力。
[0087]
下面结合附图4至图5以及具体实例对本发明技术方案作进一步详细说明。
[0088]
本发明实例的配置环境如下:cpu 8700k 主频3.7ghz, rom 16g,图形计算卡nvidia gtx3070ti, linux ubuntu 18.04系统,编程语言python 3.6.3,基于pytorch深度学习框架。
[0089]
实例一:首先通过实体链接工具,将实体和外部语料库中的实体描述信息进行链接。其中,外部语料库选用wikipedia的数据集,知识图谱数据集采用wordnet的子集wn18、wn18rr和freebase的子集fb15k和fb15k-237。其次,将每个实体的描述信息利用transformer的编码层进行嵌入训练,将训练得到的句子向量的第一个向量作为该实体通过文本增强之后的唯一实体向量表示。双曲空间中的实体表示和文本增强的实体表示是分别训练的。利用双曲
空间的距离平移计算公式对知识图谱中的三元组进行双曲空间中的嵌入训练。将通过实体描述文本增强完之后的实体和关系向量以及通过在双曲空间中训练好的实体和关系向量作为信息融合网络的输入。在信息融合网络中,首先对上述实体和关系向量进行拼接操作,然后经过前馈神经网络进行第一步信息融合,让将经过前馈神经网络的实体关系向量经过转换层网络去生成拼接之后的向量,计算二者之间的均方差作为损失函数,训练得到融合后的实体和关系(三元组)。最后将经过信息融合之后的三元组视为由三个词组成的句子,将这个句子利用双层注意力网络计算其翻译成的句子之间的得分,来获得最终的知识图谱三元组表示。
[0090]
在fb15k、wn18数据集上进行了性能验证,并对模型进行了分析。在知识图谱链接预测任务中,本发明在数据集fb15k-237上针对知识图谱中不同的关系模式1对1关系,1对n关系,n对关系,n对n关系和基准模型rotate模型进行实验评估,如图4所示。hits@10 评价指标是指正确实体在候选实体列表的前十名中在所有测试三元组中的比例,该值越大,说明链路预测的效果越好。由图4看出,本发明方法在1对1关系、1对n关系、n对1关系、n对n关系对头实体预测的hits@10都高于rotate模型,在处理1-n关系的时候更有效果。
[0091]
实例二:按照实施方法,对模型中每个融合信息对整体模型的贡献度进行分析,通过逐步去除文本增强的三元组向量和双曲嵌入的三元组向量,来分析融合信息对模型的贡献度。在fb15k-237数据集进行实验分析,实验结果如图5所示。其中,图5中的hits@10、hits@1、hits@3评价指标指的是正确实体在候选实体列表的前十名、前一名、前三名中在所有测试三元组中的比例,该值越大,说明链路预测的效果越好。图5中的mrr 是测试数据集中所有测试样本的正确实体所在排名倒数的平均值,该值越大,说明链路预测的效果越好。
[0092]
由图5能够看出,本发明方法在各个评价指标上都高于不融合任何信息的模型,其次分别添加双曲空间信息和融合描述信息都高于不容和任何信息,这表明各个信息都对知识图谱表示学习的正确性有提升效果,这表明信息融合不会丢失语义信息,同时研究还表明,添加外部信息约束可以改善知识图的动态上下文表示,提高知识图处理复杂关系的能力。
[0093]
当然,以上说明仅仅为本发明的较佳实施例,本发明并不限于列举上述实施例,应当说明的是,任何熟悉本领域的技术人员在本说明书的教导下,所做出的所有等同替代、明显变形形式,均落在本说明书的实质范围之内,理应受到本发明的保护。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1