智能应答文本分类的方法、装置、电子设备及存储介质与流程
本发明涉及通信领域,具体而言,涉及一种基于特征投影网络优化图卷积模型的智能应答文本分类的方法、装置、电子设备及存储介质。
背景技术:
1、在通信运营商云改数转的引领下,智能应答业务快速发展,用户数量屡创新高,智能应答每天产生大量数据,文本的分类与深度处理日趋重要。
2、传统的文本分类方法主要分为两类:一是基于词典的数据分类,将数据与建立的词典库进行比对从而进行分类;二是基于机器学习的数据文本分类,该方法常常依赖于人工设计的特征,并且文本表示存在着稀疏、高维度的问题。目前存在特征工程的基础上使用朴素贝叶斯、余弦相似度等分类模型进行普通文本分类。但是,智能应答进行文本分类任务时与普通文本分类任务有一定的区别:一是这些数据涉及类别广泛,且都为自动语音识别技术(asr,automatic speech recognition)转换成的自然语言文本,主要以短文本数据为主,语义稀疏、模糊、缺乏上下文的场景;二是智能应答产生的文本存在类别不均衡的特征,少数几个场景的文本数量极多,存在长尾现象。
3、针对上述问题,目前尚未发现有效的解决方案。因此,亟需研发一种能够有效提升智能应答文本分类准确率的方法。
技术实现思路
1、本发明要解决的技术问题是现有的文本分类方法对智能应答文本分类正确率低的问题。
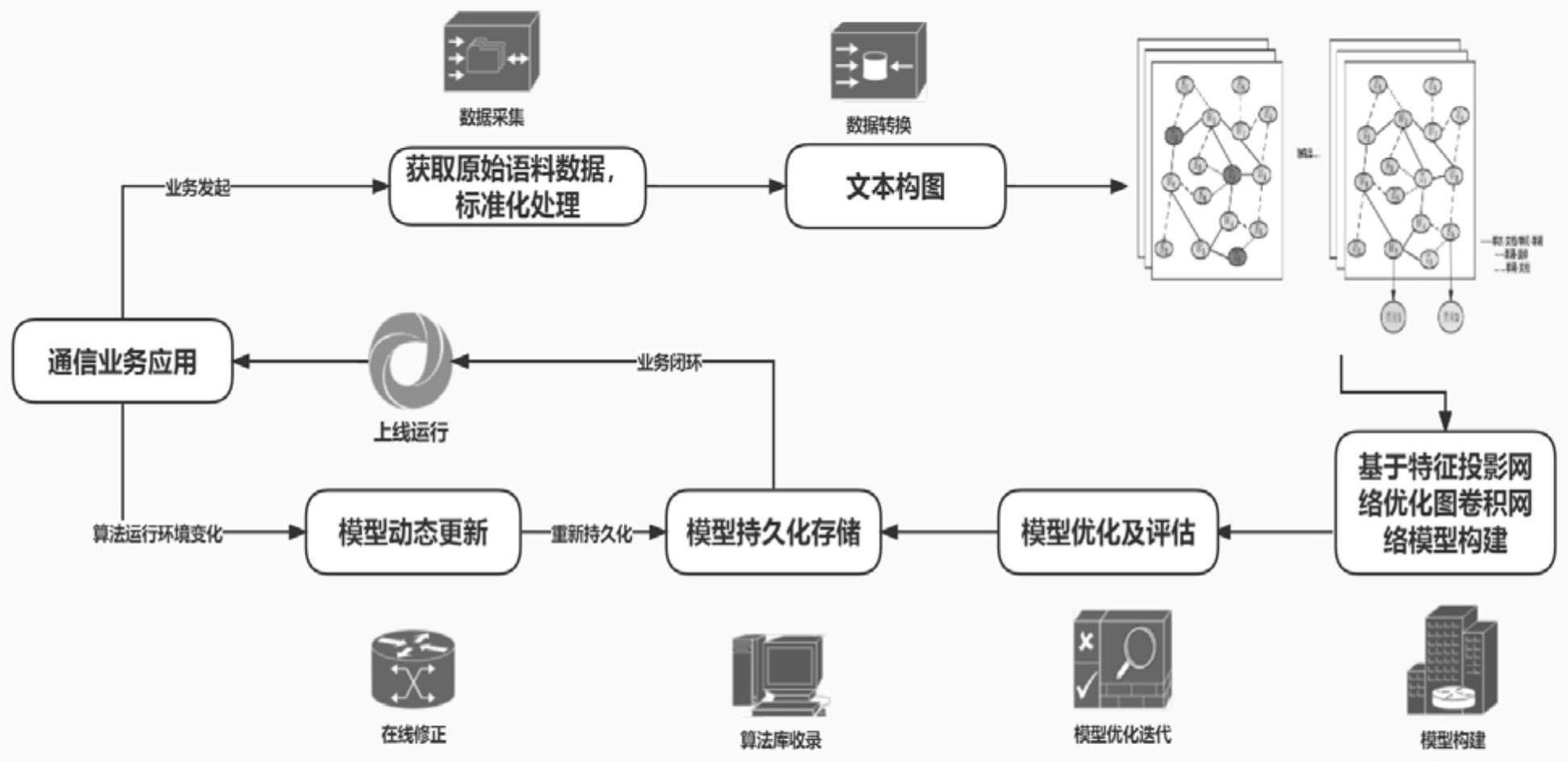
2、为解决上述技术问题,根据本发明的一个方面,提供一种智能应答文本分类的方法,其包括如下步骤:s1、数据处理,基于智能应答全场景语料数据,对经过asr(automaticspeech recognition,自动语音识别技术)转换后的数据进行包括数据清洗、转换的etl(extraction抽取,transformation转换,loading加载)工程,选取包括通话id、通话内容、通话角色、通话场景类别、通话开始时间、通话结束时间的数据,进而得到模型所需的原始语料数据集;s2、文本构图,对原始语料数据集进行包括标点符号处理和除停用词的标准化处理,使用one-hot对单词、文档及实体进行编码,形成初始图,其中,运用词共现构建词与词之间的边及词与实体之间的边,运用词频和词语的文档频率建立词节点和文档节点之间的边;单词表示为顶点,词共现表示为边进行构图,记为:g=(v,e),其中v表示节点,e表示边;s3、模型构建,基于特征投影网络(fpnet)优化图卷积神经网络,采用多头边节点池化方法改进图卷积网络,形成多头边池化图卷积网络(mhsp-gcn)架构,然后将mhsp-gcn替换fpnet中的共性特征学习网络(c-net)和特征投影网络(p-net),通过特征投影网络opl让原始特征fp和共享特征fc进行正交投影计算得到更纯的在向量空间中对类别指向更加明确的分类特征,从而提升智能应答文本分类任务的准确性。
3、根据本发明的实施例,步骤s2可包括如下步骤:s21、获取原始语料数据,采用仿射法在保持数据完整性的前提下,去除标点符号和停用词,使其表现出更好的随机属性;s22、使用one-hot对单词、文档及实体进行编码,形成初始图;s23、运用词共现构建词与词之间的边及词与实体之间的边;s24、运用词频和词语的文档频率建立词节点和文档节点之间的边;s25、将单词表示为顶点,词共现表示为边进行构图。
4、根据本发明的实施例,步骤s3可包括如下步骤:s31、针对步骤s2中构建的图数据,同时输入多头池化图卷积(mhsp-gcn)p-net网络、多头池化图卷积(mhsp-gcn)c-net网络和多头边节点池化层;s32、mhsp-gcn网络的p-net网络和c-net网络经过一层gcn卷积计算层,然后经过残差连接层计算残差,并对残差进行加权操作处理;s33、p-net网络经过第二层gcn卷积计算层,输出特征投影fp;c-net网络经过第二层gcn卷积计算层,输出共性特征投影fc;s34、采用特征投影的方式融合特征投影fp和共性特征投影fc;s35、经过全连接层输出分类类别。
5、根据本发明的实施例,步骤s2中可采用文档中的词共现(文档-单词边),整个语料库中的词共现(单词-单词边)及知识库中的词共现(单词-实体边/文档-实体边)在各节点之间构建边,其中,针对文档-单词和文档-实体的边的权重,采用bm25算法进行计算词和文档相关性,其计算公式如下:
6、
7、
8、其中,|d|为文档总数,|j:wj∈dj|表示包含wi的文档数,k1,b为协调因子,分别设为2、0.75;fi为词wi在文档中出现的次数;dl维度的长度;为索引文档的平均长度。
9、根据本发明的实施例,步骤s2中,为了利用全局词共现信息,通过点互信息算法pmi(pointwise mutual information)来计算单词-单词节点和实体-单词节点之间的权重,计算词关联度量;pmi是一种词关联度量方法,统计2个词语在文本中同时出现的概率,概率越大,其相关性就越紧密,关联度越高;其中,pmi计算公式如下:
10、
11、p(w1)=win(w1)/ws (4)
12、p(w1&w2)=win(w1,w2)/ws (5)
13、其中,ws表示滑动窗口总数,win(w1,w2)表示同时包含词w1和词w2的滑动窗口个数,win(w1)表示仅包含词w的滑动窗口个数。
14、根据本发明的实施例,步骤s2中,当节点i和节点j表示单词或知识实体时,其边的权值可采用pmi计算;当计算文档-单词或文档-知识实体节点所构边的权值时,可采用bm25算法;当节点构成自环时,权值可设置为1.0;其他情况下权值可为0;从而边的权值表达式如下:
15、
16、将构建好的图输入一个2层的gcn网络中,通过softmax分类器进行预测,采用的交叉熵函数进行计算。表达式如下:
17、h(l+1)=relu(d1/2ad-1/2h(l)w(l)) (7)
18、
19、
20、其中,式子中0和1分别得到2层gcn的节点表示,w(l)表示第l层的权重矩阵,a表示邻接矩阵,d为a的度矩阵,h(l)表示特征向量矩阵,为第i个节点真实标签,l为损失函数。
21、根据本发明的实施例,步骤s3可采用多头边池化图卷积网络和fpnet融合的方式构建模型,将mhsp-gcn替换fpnet中的共性特征学习网络(c-net)和特征投影网络(p-net),通过特征投影网络opl让原始特征fp和共享特征fc进行正交投影计算得到更纯的分类特征fp',特征fp'在向量空间中对类别指向更加明确;其中,模型网络分为多头边池化图卷积网络特征投影网络p-net(mhsp-gcn p-net)和多头边池化图卷积网络共性特征提取网络c-net(mhsp-gcn c-net)的两个网络;所述两个网络在结构上相同,但是参数上并不共享;mhsp-gcn c-net中加入grl反转层后和mhsp-gcn p-net的输出结果一样,如式(10)(11)所示,模型的输出层都使用softmax归一化激活函数,如式子(12)(13)所示,双网络使用交叉熵损失函数计算:
22、yp=softmax(fp) (10)
23、
24、lossp=crossentropy(ytruth,yp) (12)
25、lossc=crossentropy(ytruth,yc) (13)
26、在反向传播过程中mhsp-gcn p-net网络参数和mhsp-gcn c-net网络参数并不共享,lossc反向传播只更新mhsp-gcn c-net网络参数,lossp反向传播只更新mhsp-gcn p-net网络参数;mhsp-gcn c-net中虽然同样使用softmax和交叉熵损失函数,但是由于在反向传播时候mhsp-gcn c-net模块中grl层进行梯度反转,因此lossc的值会逐渐变大;进行lossc计算和反向传播只是为让神经网络得到共性特征;mhsp-gcn p-net模块中lossp为最终整个模型预测分类损失承数值,yp值为整个特征投影优化的mhsp-gcn网络的最终预测输出。
27、根据本发明的第二个方面,提供一种智能应答文本分类的装置,包括:数据处理模块,所述数据处理模块用于基于智能应答全场景语料数据,对经过asr转换后的数据进行包括数据清洗、转换的etl工程,选取包括通话id、通话内容、通话角色、通话场景类别、通话开始时间、通话结束时间的数据,进而得到模型所需的原始语料数据集;文本构图模块,所述文本构图模块对原始语料数据集进行包括标点符号处理和除停用词的标准化处理,使用one-hot对单词、文档及实体进行编码,形成初始图,其中,运用词共现构建词与词之间的边及词与实体之间的边,运用词频和词语的文档频率建立词节点和文档节点之间的边;单词表示为顶点,词共现表示为边进行构图;模型构建模块,所述模型构建模块基于特征投影网络(fpnet)优化图卷积神经网络,采用多头边节点池化方法改进图卷积网络,形成多头边池化图卷积网络(mhsp-gcn)架构,然后将mhsp-gcn替换fpnet中的共性特征学习网络(c-net)和特征投影网络(p-net),通过特征投影网络opl让原始特征fp和共享特征fc进行正交投影计算得到更纯的在向量空间中对类别指向更加明确的分类特征,从而提升智能应答文本分类任务的准确性。
28、根据本发明的第三个方面,提供一种电子设备,包括:存储器、处理器及存储在存储器上并可在处理器上运行的智能应答文本分类程序,智能应答文本分类程序被处理器执行时实现上述的智能应答文本分类方法的步骤。
29、根据本发明的第四个方面,提供一种计算机存储介质,其中,计算机存储介质上存储有智能应答文本分类程序,智能应答文本分类程序被处理器执行时实现上述的智能应答文本分类方法的步骤。
30、与现有技术相比,本发明的实施例所提供的技术方案至少可实现如下有益效果:
31、本发明采用一种特征投影网络优化图卷积模型的文本分类方法,针对智能应答文本语料特征,发明了一种基于特征投影网络优化图卷积模型的智能应答文本分类方法。该方法首先通过具备增强重要节点的多头边池化方法改进图卷积神经网络,用于提取文本全局信息和重要信息特征,然后借助具备文本增强能力的特征投影网络(fp-net,featureprojection net)改进表征学习,有效地提升文本分类效果和性能。有效提升智能应答文本分类方法的准确率,提升服务质量,挖掘数据潜在价值。具备广泛的应用场景和商业价值。
32、本发明通过不舍弃不重要节点,同时选择重要节点来增强其表示学习,定义mhsp-gcn结构,丰富的链接有效地关联了节点(包括稀疏的),从而可以有效地表示这些节点,获得全局信息。
33、本发明提出的mhsp-gcn网络引入了多头边池化来增强重要节点的表示学习。这些选择和增强的节点包含更鲜明的特征,可以使分类更加准确。
34、本发明提出的mhsp-gcn是基于gcn的网络结构创新,具有更强的覆盖所有数据的能力。当应用于短文本分类时,它可以为长尾(稀疏)词提供一定程度的关注。
- 还没有人留言评论。精彩留言会获得点赞!