一种基于知识蒸馏的面向设备异构的联邦学习方法
本发明属于数据信息隐私保护,具体涉及一种面向设备异构的联邦学习方法。
背景技术:
1、随着数据量的快速增加,以及出于隐私保护的需求,联邦学习已经发展成为一个非常有前景的方向。联邦学习一般由许多仅能访问私有数据的客户端以及一个可以协调学习过程而不能访问任何原始数据的中央服务器构成。它的目标是在不显式地分享私有数据的前提下,利用分布存储的数据在中央服务器上训练一个全局模型。这种方法面临的一个挑战是数据异构,当各个客户端拥有的数据分布不同时模型的性能会下降。现有的解决数据异构问题的方法大多基于梯度的整合,必须在本地模型同构的条件下进行。
2、本发明申请专注于设备异构的联邦学习问题。在这个问题背景下,各个客户端的存储、计算和通信能力的不同,造成本地模型的结构也会不同,现有方法会遇到严峻的挑战。在一些实际的联邦学习场景中,需要在硬件差异很大的设备上训练。当模型结构设计的较复杂时,资源较少的设备无法参与训练;当模型结构较简单时,另一些资源充足的设备又未充分利用。
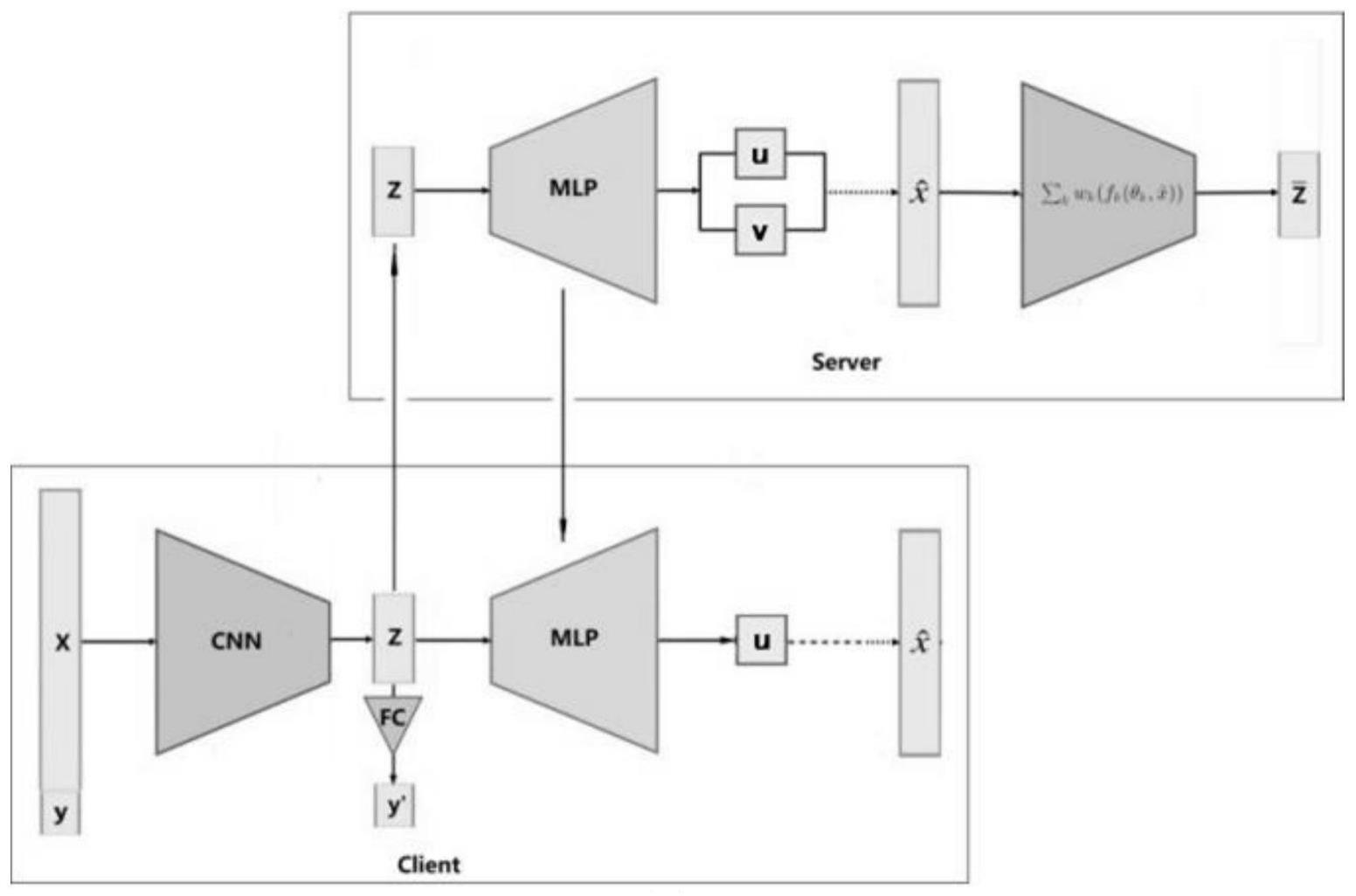
3、为此,本发明提出一种基于知识蒸馏的联邦学习算法,它允许每个客户端建立个性化模型,可以同时解决模型异构和数据异构两种挑战。算法把每轮通信分为两个阶段,在服务器训练阶段,首先以推断样本低维表示的后验分布为目标在服务器上建立生成模型,然后把训练好的生成模型传递给客户端;在本地训练阶段,客户端一方面用私有样本计算任务损失,一方面用生成模型输出的均值样本计算调优表示层的损失。这样在多轮迭代之后,各个客户端可以得到比传统训练方法精度更高的模型。
技术实现思路
1、本发明的目的在于提出一种面向设备异构的联邦学习方法,以便在客户端资源差异很大的场景下进行联邦学习,从而为挖掘数据信息提供有力保障。
2、本发明提出的面向设备异构的联邦学习方法,是基于知识蒸馏技术的;其涉及的系统包括有k个客户端、1个服务器;其中;
3、每个客户端上有1个根据软硬件资源设置的分类模型,客户端的分类模型划分为表示层和决策层,表示层用于把样本映射为低维表示,决策层用于把低维表示映射为概率向量;客户端之间知识蒸馏的目标函数定义式:
4、
5、其中,k是客户端数量;xk是第k个客户端的私有数据集,x、y是样本和标签;lk是分类任务的损失函数;φ(·)是客户端模型的决策层函数,fk(·)是客户端模型的表示层函数,θk是表示层参数;γ是超参数;各个客户端上的分类模型的表示层结构和参数不同,而决策层的结构和初始化参数均相同。
6、所述服务器上设置1个生成模型,由共享输入的均值函数和方差函数构成。系统的目标是高效地求解(1)式,为此,本发明方法把每轮通信分为两个阶段:服务器训练阶段和本地训练阶段;在服务器训练阶段,首先以推断样本低维表示的后验分布为目标在服务器上建立生成模型,然后把训练好的生成模型传递给客户端;在本地训练阶段,客户端一方面用私有样本计算任务损失,一方面用生成模型输出的均值样本计算调优表示层的损失。这样在多轮迭代之后,各个客户端可以得到比传统训练方法精度更高的模型。
7、具体地:
8、在服务器训练阶段,服务器首先收集所有客户端模型的表示层;收集客户端采集的低维表示,组成集合z。然后,用变分推断法求解后验分布具体地:
9、假设是高斯分布,生成模型把z作为输入,均值函数和方差函数分别输出的均值和方差,即:
10、
11、其中,z是低维表示的集合,是生成模型估计的样本集合;u(·)和θu分别是生成模型的均值函数和参数;v(·)和θv分别是生成模型的方差函数和参数;是均值u方差v的高斯分布;
12、从中采样的样本分别输入所有收集的表示层,得到k个低维表示;如果样本的标签是j,则以为权重求这些低维表示的加权均值,计算加权均值与z的欧式距离损失(其中nj是所有客户端第j类样本的总数量,nk,j是第k个客户端上第j类样本的总数量)。
13、另一方面,计算与标准高斯分布的kl散度损失。以上过程即以(3)式为损失函数用随机梯度下降法训练生成模型:
14、
15、其中,fk(·)是客户端模型的表示层函数,θk是表示层参数;λ是超参数;是标准高斯分布;kl(·)是kl散度(kullback-leibler divergence);wk是客户端权重;其他符号的含义与(2)中的相同;
16、最后,服务器把训练后的生成模型的均值函数传给所有客户端。
17、在本地训练阶段,客户端首先接收服务器传来的均值函数。然后,一方面用私有数据集xk计算分类任务损失;另一方面,收集计算分类任务损失过程中产生的低维表示,把低维表示输入均值函数得到均值样本,计算均值样本与xk的欧式距离损失,以上过程即以(4)式为损失函数用随机梯度下降法训练本地分类模型:
18、
19、其中,xk是第k个客户端的私有数据集,x、y是样本和标签;lk是分类任务的损失函数;φ(·)是客户端模型的决策层函数,fk(·)是客户端模型的表示层函数,θk是表示层参数;λ′是超参数;其他符号的含义与(2)中的相同;
20、接着,客户端采集低维表示,具体地说,客户端继续执行随机梯度下降过程,每执行q轮,把这期间得到的低维表示分标签求均值,在得到至少c个低维表示均值后停止采集。
21、最后,客户端把分类模型表示层和采集的低维表示均值上传给服务器。
22、重复服务器训练阶段和本地训练阶段,这样在多轮迭代之后,各个客户端可以得到比传统训练方法精度更高的模型。
23、本发明的特点和优势主要有:
24、第一它允许不同客户端有不同分布的数据和不同结构的模型表示层,可以同时解决模型异构和数据异构两种挑战,拓展了应用场景;
25、第二,它允许每个客户端建立个性化模型,在数据异构的场景下,相比建立全局模型的其它方法,它可以使系统获得更高的平均精度;
26、第三,它基于知识蒸馏技术优化表示层,在从相关客户端获取信息的同时减少不相关客户端的干扰,使本地模型的精度比优化决策层的方法或其它传统方法更高;第四,在通信过程中,客户端不是上传低维表示的原值而是均值,不是上传整个客户端模型而是仅上传表示层,这避免了服务器利用客户端模型参数或低维表示推测客户端数据。
技术特征:
1.一种基于知识蒸馏的面向设备异构的联邦学习方法,所涉及的系统包括有k个客户端、1个服务器;其特征在于:
2.根据权利要求1所述的基于知识蒸馏的面向设备异构的联邦学习方法,其特征在于,在服务器训练阶段,服务器首先收集所有客户端模型的表示层;收集客户端采集的低维表示,组成集合z;然后,用变分推断法求解后验分布具体地:
3.根据权利要求2所述的基于知识蒸馏的面向设备异构的联邦学习方法,其特征在于,在本地训练阶段,客户端首先接收服务器传来的均值函数;然后,一方面用私有数据集xk计算分类任务损失;另一方面,收集计算分类任务损失过程中产生的低维表示,把低维表示输入均值函数得到均值样本,计算均值样本与xk的欧式距离损失,以上过程即以(4)式为损失函数用随机梯度下降法训练本地分类模型:
技术总结
本发明属于数据信息隐私保护技术领域,具体为一种基于知识蒸馏的面向设备异构的联邦学习方法。本发明涉及的系统包括K个客户端、1个服务器;每个客户端上有一个分类模型;为高效地进行客户端模型表示层之间知识蒸馏,把每轮通信分为服务器训练阶段和本地训练阶段;在服务器训练阶段,首先以推断样本低维表示的后验分布为目标在服务器上建立生成模型,然后把训练好的生成模型传递给客户端;在本地训练阶段,客户端一方面用私有样本计算任务损失,一方面用生成模型输出的均值样本计算调优表示层的损失。这样在多轮迭代之后,各个客户端可以得到比传统训练方法精度更高的模型。
技术研发人员:王智慧,焦孟骁
受保护的技术使用者:复旦大学
技术研发日:
技术公布日:2024/1/11
- 还没有人留言评论。精彩留言会获得点赞!