一种基于问答方法的不限长小样本文本分类训练方法及系统与流程
本发明属于样本分析的数据处理,特别是涉及一种基于问答方法的不限长小样本文本分类训练方法及系统。
背景技术:
1、在人工智能技术的发展浪潮中,随着计算机技术的发展,自然语言处理领域的很多任务逐渐被智能化机器取代。例如,文本分类领域,人工智能技术可以帮助人完成对文本贴标签的处理,且不论何时何地,仅需上传文本,大大提高了工作效率。
2、但是,现有技术中还还存在一些缺陷。例如,通常使用的bert模型,在文本分析的过程中,对文本存在长度的限制;当分类标签过多时,语言模型的分类准确率低;为提高模型的性能,训练需要的数据量偏大,往往需要上千甚至万条以上的数等等。
技术实现思路
1、发明目的:提出一种基于问答方法的不限长小样本文本分类训练方法及系统,以解决现有技术存在的上述问题。通过模型训练,加强模型对文本语义的理解,并通过将文本与候选标签,问题一同列出的方式,利用模型训练所得的理解能力,迁移到对特定问题的分类上,以问答的方式发掘了模型的潜力,提高了分类准确率,使其具有良好的泛化效果;另外,结合小样本能力,使模型可以轻易迁移到不同领域的文本上。
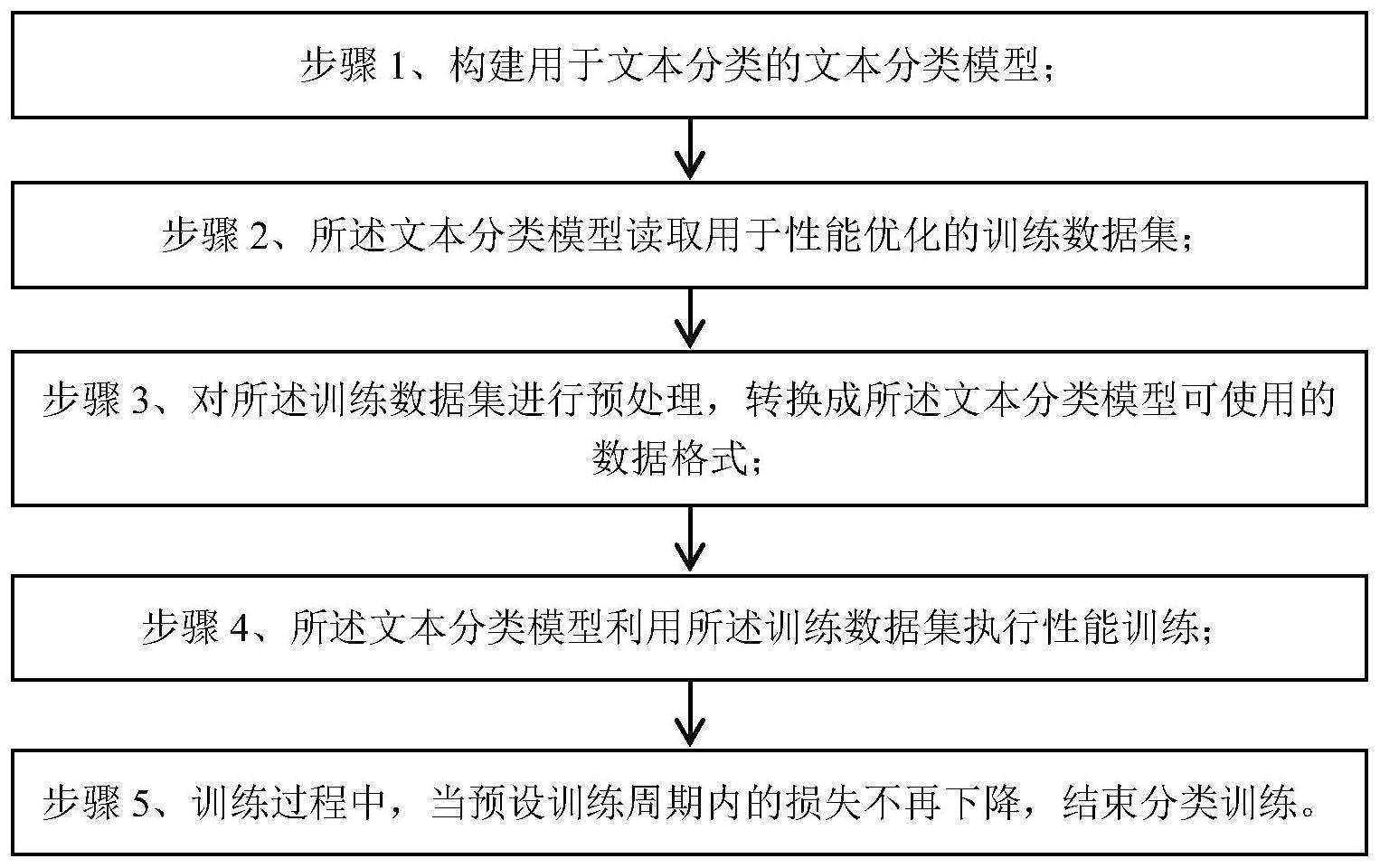
2、技术方案:第一方面,提出了一种基于问答方法的不限长小样本文本分类训练方法,包括以下步骤:
3、步骤1、构建用于文本分类的文本分类模型;该分类模型基于roformer模型,具体包括:embedding层、主体模型层和线性输出层。其中,主题模型层由至少十二层roformer模型通过堆叠的方式构成。
4、步骤2、所述文本分类模型读取用于性能优化的训练数据集;
5、其中训练数据集由不同领域的数据构成,包括:文本数据和文本数据对应的标签。不受限于实际的应用场景。
6、文本数据的来源渠道,一部分来源于用户日常生产活动中产生的各类文档,另一部分来源于利用网络爬虫获得的公开文件。
7、步骤3、对所述训练数据集进行预处理,通过文本转换的方式,将训练数据集中的文本数据转换为问答形式,并在文本的最后添加[mask]标签,所述问答形式为:文本+问题+选项+[mask]。
8、步骤4、所述文本分类模型利用训练数据集执行两阶段的性能训练;其中,第一阶段采用将训练数据集中的文本抽象化处理,掩盖文本中存在的潜在关键词语,利用文本分类模型的理解能力,直接对文本数据进行分析;第二阶段根据实际应用需求,采用需要分类的文本数据与对应标签进行精细化的分类训练。
9、在文本分类模型对训练数据集中的数据进行分析的编码阶段中,采用相对位置编码,同时结合利用三角函数复数形式对位置进行描述,并将位置矩阵融入文本分类模型中。
10、另外,在文本分类模型执行训练的过程中,将训练数据集种的文本数据组织成预设的相同长度,使得文本分类模型能以矩阵形式处理所有数据;当训练数据集中的数据长于预设长度时,从后向前截取文本,令文本长度满足预设长度的限制。
11、步骤5、训练过程中,当预设训练周期内的损失不再下降,结束分类训练;训练过程中采用交叉熵损失函数进行训练,并同时判断loss的下降趋势,当满足预设周期内loss不再下降,则结束训练。
12、在第一方面的一些可实现方式中,基于训练完的文本分类模型,执行文本分类的过程具体包括以下步骤:首选,读取待分析的文本数据;其次,将待分析的文本数据转换为问答形式;然后,利用文本分类模型对程问答形式的文本数据进行分类;最后,输出分类结果。其中,问答形式为:文本+问题+标签;分类结果对应被选择的标签。
13、第二方面,提出一种基于问答方法的不限长小样本文本分类训练系统,用于实现基于问答方法的不限长小样本文本分类训练方法,该系统具体包括:
14、用于构建文本分类模型的模型构建模块;
15、用于读取所需文本数据的数据读取模块;
16、用于对文本数据执行形成转换的数据处理模块;
17、用于优化文本分类模型性能的性能优化模块;
18、用于执行逻辑判断的逻辑判断模块。
19、执行基于问答方法的不限长小样本文本分类训练方法的过程中,首先利用模型构建模块构建文本分类模型;随后,采用数据处理模块对训练数据进行格式转换,转换为“文本+问题+标签”的形式;然后文本分类模型采用数据读取模块读取转换后的文本数据,并利用性能优化模块对文本分类模型进行性能优化;最后,通过逻辑判断模块判断优化过程是否终止,从而完成文本分类模型的训练。
20、在第二方面的一些可实现方式中,构建的文本分类模型基于呈堆叠形式的roformer模型构成,同时还包括embedding层和线性输出层。其中roformer模型使用复数对文本中位置信息进行了相对位置编码的功能,突破了bert对输入文本长度限制的要求;且由于roformer易于堆叠的性质,将24个roformer堆叠起来构成的大模型,有效强化了模型功能。
21、第三方面,提出一种计算机可读存储介质,该计算机可读存储介质上存储有计算机程序指令。计算机程序指令被处理器执行时,以实现基于问答方法的不限长小样本文本分类训练方法。
22、有益效果:本发明提出了一种基于问答方法的不限长小样本文本分类训练方法及系统,通过分阶段的文本分类训练过程,构建的文本分类模型在大量文本的训练中,加强了对文本语义的理解,随后,通过将文本与候选标签、问题一同列出的方式,利用模型训练所得的理解能力,迁移到对特性问题的分类上,以问答的方式挖掘文本分类模型的潜力,达到文本分类模型可以轻易迁移到不同领域的文本分类任务中。
技术特征:
1.一种基于问答方法的不限长小样本文本分类训练方法,其特征在于,具体包括以下步骤:
2.根据权利要求1所述的一种基于问答方法的不限长小样本文本分类训练方法,其特征在于,所述文本分类模型包括:embedding层、主体模型层和线性输出层;
3.根据权利要求1所述的一种基于问答方法的不限长小样本文本分类训练方法,其特征在于,利用所述文本分类模型对文本数据进行分析的过程中,在进行位置编码的阶段,采用相对位置编码,利用三角函数复数形式描述位置,将位置矩阵融入文本分类模型中。
4.根据权利要求1所述的一种基于问答方法的不限长小样本文本分类训练方法,其特征在于,所述训练数据集来源于不同的领域,不受特定应用场景的限制,包括:文本数据和文本数据对应的标签。
5.根据权利要求1所述的一种基于问答方法的不限长小样本文本分类训练方法,其特征在于,对所述训练数据集进行预处理的过程具体为:通过文本转换的方式,将训练数据集中的文本数据转换为问答形式,并在文本的最后添加[mask]标签,所述问答形式为:文本+问题+选项+[mask]。
6.根据权利要求1所述的一种基于问答方法的不限长小样本文本分类训练方法,其特征在于,所述文本分类模型执行性能训练的过程中,被划分为模型预训练阶段和精细化训练阶段,并采用交叉损失函数进行性能训练;
7.根据权利要求1所述的一种基于问答方法的不限长小样本文本分类训练方法,其特征在于,在文本分类模型执行训练的过程中,将训练数据集种的文本数据组织成预设的相同长度,使得文本分类模型能以矩阵形式处理所有数据;
8.根据权利要求1所述的一种基于问答方法的不限长小样本文本分类训练方法,其特征在于,基于训练好的文本分类模型在执行文本分类的过程中,具体包括以下步骤:
9.一种基于问答方法的不限长小样本文本分类训练系统,用于实现如权利要求1-8任意一项所述的基于问答方法的不限长小样本文本分类训练方法,其特征在于,具体包括以下模块:
10.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质上存储有计算机程序指令,所述计算机程序指令被处理器执行时实现如权利要求1-8任意一项所述的基于问答方法的不限长小样本文本分类训练方法。
技术总结
本发明提出一种基于问答方法的不限长小样本文本分类训练方法及系统,属于样本分析的数据处理技术领域。其中方法包括:构建用于文本分类的文本分类模型;文本分类模型读取用于性能优化的训练数据集;对训练数据集进行预处理,转换成文本分类模型可使用的数据格式;文本分类模型利用训练数据集执行性能训练;训练过程中,当预设训练周期内的损失不再下降,结束分类训练。通过分阶段的文本分类训练过程,加强了对文本语义的理解,随后,通过将文本与候选标签、问题一同列出的方式,利用模型训练所得的理解能力,迁移到对特性问题的分类上,以问答的方式挖掘文本分类模型的潜力,达到文本分类模型可以轻易迁移到不同领域的文本分类任务中。
技术研发人员:杨珂,吕晓宝,王元兵,王海荣
受保护的技术使用者:中科曙光南京研究院有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!