一种纵向联邦学习架构下的非抽样因子分解机服务方法
本发明涉及推荐系统,具体为一种纵向联邦学习架构下的非抽样因子分解机服务方法。
背景技术:
1、因子分解机是一种通用框架,它集成了灵活的特征工程和潜在因子模型的高精度预测的优点。联邦学习作为一种新的机器学习范式允许不同参与者在不泄露私有数据的情况下合作构建智能系统,同时解决了隐私和数据稀疏的问题。纵向联邦学习一般是适用于数据集上具有相同的样本空间、不同的特征空间的参与方所组成的联邦学习场景,纵向联邦学习也可以理解为按特征划分的联邦学习。
2、假设有两家公司a和b想要协同地训练一个机器学习服务推荐模型,每一家公司都拥有各自的数据。例如,对于社交门户网站与电子商务网站,社交门户网站只有根据用户的个人信息,如职业、性别等,电子商务网站只有用户对商品的隐式反馈数据,如用户对商品的点击情况等,并且a,b两公司的用户集具有较高的重合性。电子商务网站想要在保证用户隐私的情况下获取社交门户网站的数据集并与本公司数据集进行联合训练,以实现为用户提供定制化的推荐服务。
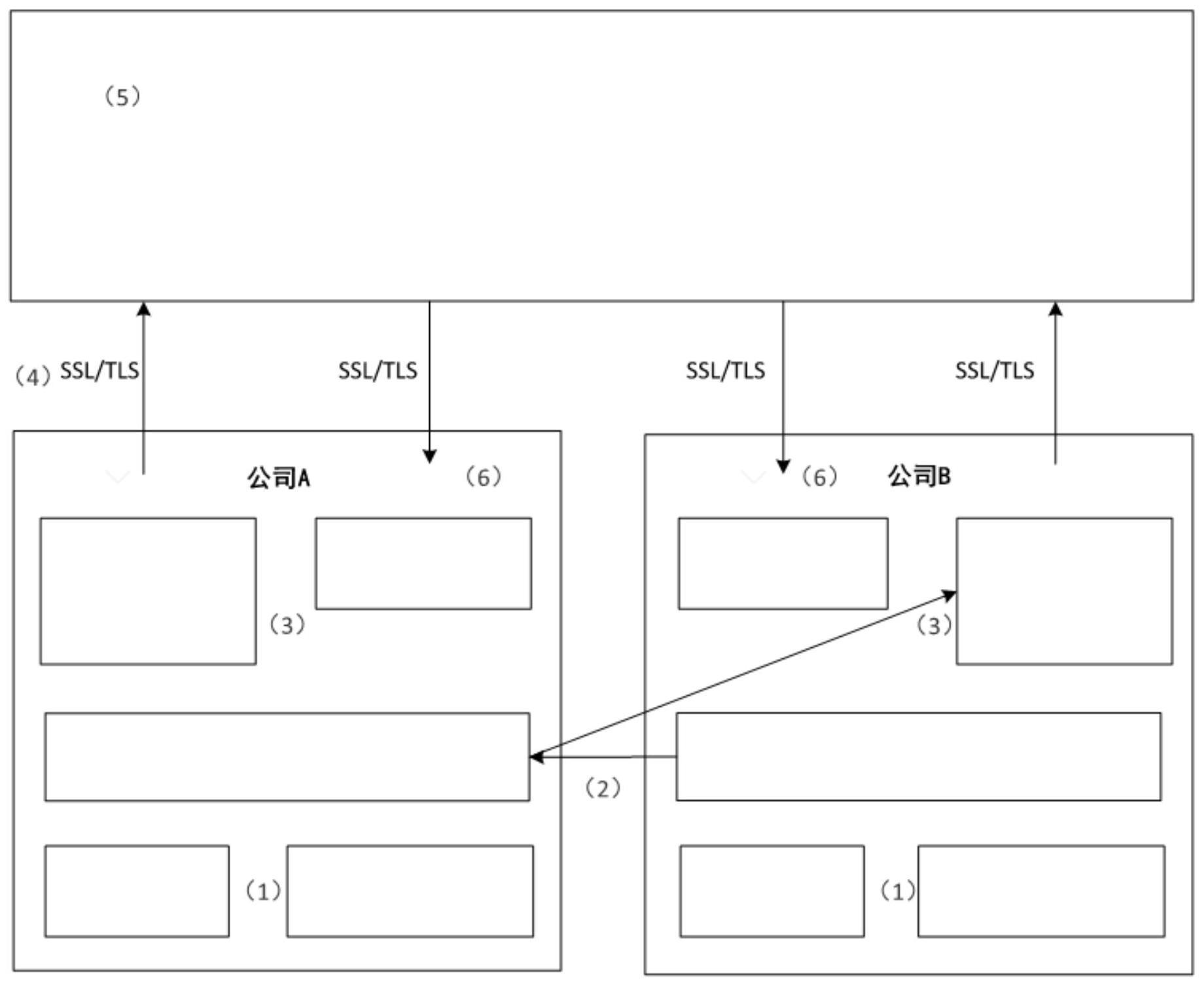
3、由于用户隐私和数据安全的原因,a方和b方不能直接交换数据,为了保证训练过程中的数据保密性,此时需要加入了一个第三方的协调者c。c是一个半诚实的第三方,它主要用来帮助参与方进行安全的联邦学习,c独立于各参与方,它将会收集中间结果用来计算梯度和损失值,并将结果转发给每一参与方。c收到的来自参与方的信息是被加密过或者被混淆处理过的,因此各方的原始数据并不会暴露给彼此,并且各参与方只会收到与其拥有的特征相关的模型参数。
4、在上述场景下,为了提供更准确的推荐,除了建模用户项交互之外,还要考虑上下文特性,但传统的非抽样联邦因子分解机方法效率不佳。
技术实现思路
1、(一)解决的技术问题
2、针对现有技术的不足,本发明提供了一种纵向联邦学习架构下的非抽样因子分解机服务方法,具备在数据通常不能直接从一个数据所有者转移到另一个数据所有者的情况下,有两家公司a和b想要协同地训练一个机器学习服务推荐模型,每一家公司都拥有各自的数据,两方数据集上具有相同的样本空间、不同的特征空间,本发明将纵向联邦学习与非抽样因子分解机相结合,纵向联邦学习可以保障数据隐私,同时,使用改进的非抽样因子分解机模型进行训练,采用数学方法,将传统的因子分解机模型转化为矩阵分解模型,同时优化了损失函数等优点,解决了基于纵向联邦学习架构下的非抽样因子分解机推荐框架效率差的问题。
3、(二)技术方案
4、为实现上述目的,本发明提供如下技术方案:一种纵向联邦学习架构下的非抽样因子分解机服务方法,包括以下步骤:
5、s1、公司a和公司b各自初始化本地模型,即对于公司a,初始化参数wa,va并基于此计算出向量pa,对于公司b,初始化参数wb,vb并基于此计算出向量qb;
6、s2、可信第三方服务端c发送公钥pub给公司a、b,公司b将中间结果qb加密得到[[qb]],传输给公司a。
7、s3、公司a接收到公司b传输的加密中间结果[[qb]],并通过pa,[[qb]],haux求出纵向联邦因子分解机算法的加密预测函数公司a将[[pa]]和发送回公司b。
8、s4、公司a和公司b分别利用本地与对方传输的数据,计算出损失函数l,公司a求解加密梯度
9、s5、公司a和公司b分别将这些加密的参数梯度上传到第三方服务端c解密,结果分别重新返回公司a和公司b,利用梯度下降更新参数。
10、s6、重复步骤s2至s5,直至模型收敛。
11、优选的,步骤s1所述计算pa与qb的具体方法是:
12、
13、其中,
14、
15、
16、haux,d=h2;haux,d+1=1;haux,d+2=1
17、其中,d代表隐因子数量,pa∈rd+2、qb∈rd+2和haux∈rd+2表示公司a的特征向量、公司b的特征向量和预测层的辅助神经元权重,pa和qb都仅取决于公司a与公司b本地的特征数据,其中,和分别是参与联合建模的公司a和公司b局部模型的全局偏置,m和n分别代表公司a和b的数据的特征数量,和是模型中公司a第i个和公司b第j个变量的权重,fbi(a)和fbi(b)分别表示公司a数据自身特征和公司b数据自身特征之间的二阶交互,h1表示预测层a、b两公司内部特征交叉项之和的神经元权重,h2表示预测层a、b两公司特征相互交叉项的神经元权重。
18、优选的,步骤s2所述采用的加密方法的具体方法为:
19、[[qb]]=epub(qb)
20、其中epub(·)为使用公钥pub的加法同态加密函数,[[qb]]为同态加密后的结果。
21、优选的,步骤s3所述通过[[pa]],[[qb]],[[haux]]求出纵向联邦因子分解机算法的预测值的具体方法是:
22、
23、其中[[pa]]和[[qb]]表示使用公钥pub的同态加密函数同态加密公司a的特征向量和公司b的特征向量,haux为预测层的辅助神经元权重,⊙表示向量的元素乘积,pa和qb都仅取决于公司a与公司b本地的特征数据。
24、优选的,步骤s4中计算损失函数l的具体方法是:
25、
26、其中,其中u为公司b的数据集,v+为公司a中具有正反馈的数据集,为代入数据集u中第u项和数据集v+中第v项特征的预测值,d代表隐因子数量,hi,bj分别为为向量haux的第i项和第j项,pu,i,pu,j分别为向量pa的第i项和第j项,pv,i,pu,j分别为向量qb的第i项和第j项。
27、优选的,步骤s5所述首先a,b公司收到c端解密的梯度数据,然后a,b公司使用各自接收到的数据更新各自的参数的具体包括以下步骤:
28、s5.1、a,b公司收到c端使用加法同态解密函数dpub(·)解密的结果,其中a公司接收到公司b接收到
29、s5.2、所述利用梯度下降更新参数的具体方法是:
30、
31、
32、
33、
34、
35、
36、其中,α为学习率,和分别是参与联合建模的公司a和公司b局部模型的全局偏置,wa和wb分别是参与联合建模的公司a和公司b局部模型的线性权重,va和vb分别是参与联合建模的公司a和公司b局部模型的隐向量。
37、(三)有益效果
38、与现有技术相比,本发明提供了一种纵向联邦学习架构下的非抽样因子分解机服务方法,具备以下有益效果:
39、该纵向联邦学习架构下的非抽样因子分解机服务方法,将因子分解机转化为矩阵分解的形式,并基于此采用新的损失函数进行模型训练,结合纵向联邦学习方法,实现了高效全抽样隐反馈纵向联邦学习架构下的因子分解机服务推荐,解决了基于纵向联邦学习架构下的隐反馈全抽样因子分解机运行效率差的技术问题。
- 还没有人留言评论。精彩留言会获得点赞!