一种基于Transformer的面向记忆的单图片去雨方法
本发明涉及图片预处理,具体的说是一种基于transformer的面向记忆的单图片去雨方法。
背景技术:
1、雨水图片中存在的雨痕等信息会使得图片背景高度模糊,进而影响目标识别的准确性。对于自动驾驶汽车而言,其基于视觉的感知功能,如物体检测、识别和语义/实例分割,需要对城市街道场景图像进行准确的特征学习。雨水作为最常见的恶劣天气条件,会极大地降低图像的视觉质量,并阻塞背景物体。这些能见度的降低对图像特征学习产生了负面影响,并导致许多计算机视觉系统很可能出现故障。除了自动驾驶,许多其他应用,如户外监控系统,在呈现含有雨和雾霾等伪影的图像时,也会降级。这些原因都使得去雨成为一种非常可取的技术,可以从图像中去除因雨水导致的模糊的视觉效果。
2、目前,图像去雨算法主要包括视频和单幅图像去雨算法,上述系统所采集的信息和数据大都为视频信息,视频是由连续帧的多个图像构成,可以结合图像连续帧间特性检测受雨纹或雨滴影响的像素,而单幅图像是静态信息,缺少雨纹或雨滴变化的时空特性。因此,对单幅雨天图像去雨算法的研究更具有意义。基于深度学习的方法通过使用合成数据集的大规模配对数据,在图像雨去除方面显示出了显著的改进。然而,由于真实雨纹的各种表现形式可能与合成训练数据不同,将现有方法直接扩展到真实场景是具有挑战性的。
3、现有技术的图像去雨算法背景及场景恢复清晰度差,不能更好地保留背景的结构和细节。由于真实雨纹的各种表现形式可能与合成训练数据不同,现有方法都是基于合成雨水图片进行训练和测试,不能很好地迁移到自然雨水图片中。为了解决以上问题,提出了本发明。
技术实现思路
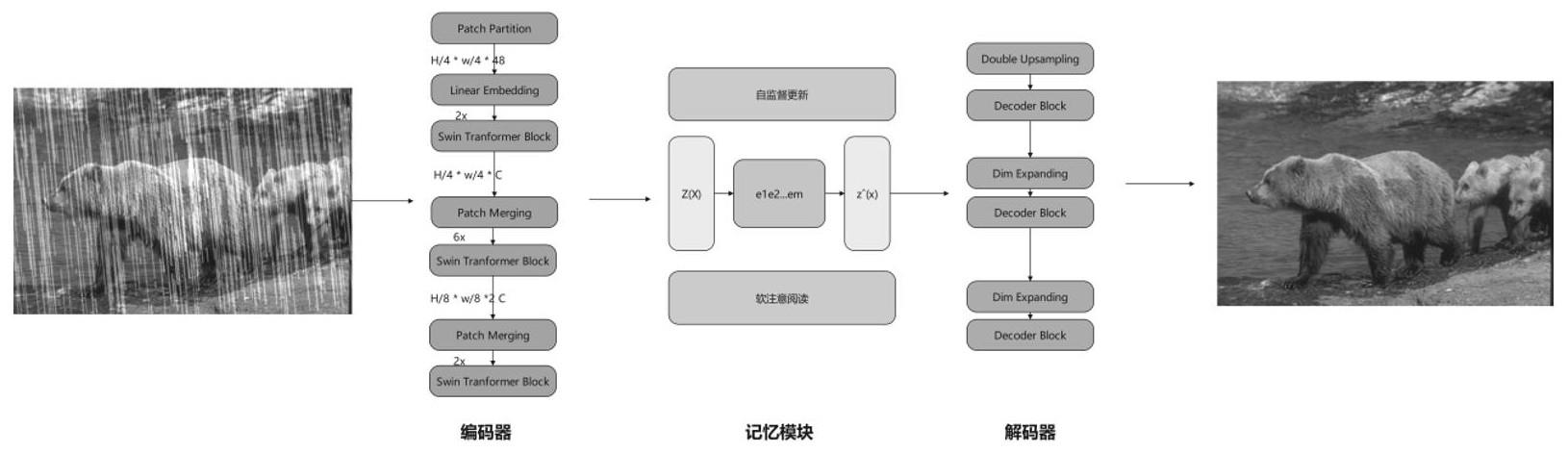
1、本发明的目的是针对现有技术的不足而提供的一种基于transformer的面向记忆的单图片去雨方法,采用transformer关注全局特征的特性,更好的提取雨水图片中雨水条纹的信息,利用具有记忆功能的自监督内存模块记录雨水条纹的各种形态,最后利用自我训机制讲合成雨水图片的上的约束信息转移到自然雨水图片上,使其能够更好地被训练,该方法可以去除更多不同外观的雨纹,恢复更清晰的背景场景,同时更好地保留背景的结构和细节,自我训练机制的加入使得算法更加适配自然雨水图片,在自然雨水图片上也能达到很好的效,不但提高图片去雨的效果,同时解决了合成训练数据上训练的现有算法无法有效的迁移到真实场景中的问题。
2、实现本发明目的的具体技术方案是:一种基于transformer的面向记忆的单图片去雨方法,其特点是利用transformer关注全局特征的特性,更好的提取雨水图片中雨水条纹的信息,然后利用具有记忆功能的自监督内存模块记录雨水条纹的各种形态,最后利用自我训机制讲合成雨水图片的上的约束信息转移到自然雨水图片上,使其能够更好地被训练,具体包括以下步骤:
3、1)初始化阶段,采用预训练模型:swin_large_patch4_window12_384_22k.pth,输入大小为384*384,每次训练样本数为4,最大训练次数300。
4、2)将384*384的图片送入transformer的编码器,patch partition对输入图像进行下采样,将原始输入图像h、w、c,宽高下降1/4,通道进调整到48,linear embedding对patch partition的输出在通道维度进行调整为c后,通过layer normalization对featuremap进行处理。
5、3)将layer normalization处理过的feature map通过swin transformerblocker和patch merging组成的编码器单元,然后对全局关系进行建模并进行层次特征变换,同时缩小特征图的宽高,扩大感受野。patch merging的是一个4x4大小的单通道特征图(feature map),patch merging会将每个2x2的相邻像素划分为一个patch,然后将每个patch中相同位置(同一颜色)像素给拼在一起就得到了4个feature map。接着将这四个feature map在深度方向进行concat拼接,然后在通过一个layernorm层。最后通过一个全连接层在feature map的深度方向做线性变化,将feature map的深度由c变成c/2。
6、4)将步骤3中的特征值映射成内监督内存模块的z(x),z(x)相当于一个query去memory找最相关的items,用soft-attention把他们结合起来,然后使用自监督更新和软注意阅读更新更新内存模块。其中,记忆内存模块m∈rm×c由m个记忆项组成,每个项的维度为ei∈rc与编码z(x)∈rc×h×w,z(x)为下述(a)式定义:
7、
8、计算余弦相似度sij(x)第i个存储项和z(x)的第j列向量zj(x),将其定义为下述(b)式:
9、
10、然后,使用下述(c)式检索zj(x)最相关的记忆项ek(j)(x),把sij(x)最大的一个编号赋值给k(j)(x):
11、k(j)(x)=argmiaxsij(x)(c)。
12、最后,更新内存项ei基于查询zj(x)具有最相关项目其中ei由下述(d)式定义为:
13、
14、软注意阅读是区别于传统硬注意阅读的方式,主要用来解决梯度反向传播的问题,再次通过上述公式(a)对更新后的内存项进行计算相似度矩阵s(x)={sij(x)|i=1,...,m,j=1,...,n}。然后,通过softmax操作获得注意a={aiji=1,...,m,j=1,...,n},其中,aij由下述(e)式定义为:
15、
16、最后,基于内存的表示是通过下述(f)式基于注意的内存项聚合来计算获得:
17、
18、5)使用具有标记的数据进行在线训练去雨网络fθ,然后使用一个额外的目标网络fξ为未标记的数据生成伪标签。其包括两个过程,一个是有监督的过程,另一个是无监督的过程。
19、监督去雨是使用具有标记的数据进行在线训练去雨网络fθ,在网络中,其中优化目标为像素级l1损失函数由下述(g)式定义为:
20、lsu=fθ(xl)-yl1(g)。
21、无监督去雨采用动量编码器进行自我监督表示学习,使用一个额外的目标网络fξ为未标记的数据生成伪标签,fξ是以指数移动平均更新的在线网络fθ。在每一个训练步骤之后,ξ由下述(h)式更新如下:
22、ξ←vξ+(1-v)θ(h)。
23、其中,v∈[0,1]是衰减速率。
24、对于雨天图像集合xu中任意一个未标记的图像xu,采用目标网络fξ产生其对应的伪标签fξ(xu),组成雨天图像集合xu相应的伪标签集yp,得到下述(i)式定义的一组含雨残差网络:
25、r={x-y(x,y)∈(xl,yl)∪(xu,yu)}(i)。
26、其中,(xl,yl)和(xu,yu)分别为合成配对集和伪配对集。
27、最后,通过对xl,yl,xu,yu等图像集进行数据增强,得到了一个有噪声的数据集xn,以及雨残差集r。更准确地说,随机抽取了一幅图像其对应的标签是(干净图像的标签是自身),以及一个残差图像r∈r。其中噪声图片xn由下述(j)式计算:
28、
29、其中,α是一个从均匀分布u(a,b)采样的随机值(具体来说,a和b在这里是0.5和1.1)。t(·)是一个钳形函数,以确保xn与具有相同的范围。因此,得到了成对的噪声数据对增强数据使用像素级l1损耗,且由下述(k)式定义为:
30、
31、增强噪声数据的自我训练可以丰富训练期间的降雨模式,并提高对真实雨水去除的鲁棒性。
32、w采用总变分正则化项对恢复后的背景图像fθ(xn)由下述(l)式进行平滑处理:
33、ltv=fθ(xn)tv(l)。
34、在线网络的总目标fθ由下述(m)式:
35、ltotal=λ1lsu+λ2lun+λ3ltv(m)。
36、其中,λ1,2,3是平衡每个项目的超参数。
37、6)使用3个解码块和dim expanding来解码步骤5)生成的特征值并实现维度变换,逐渐恢复图像。
38、7)不断重复步骤1)至步骤6),持续地优化缓存决策的准确性,并最终得到准确的结果。
39、本发明与现有技术相比具有去除更多不同外观的雨纹,恢复更清晰的背景场景,同时更好地保留背景的结构和细节,自我训练机制的加入使得算法更加适配自然雨水图片,在自然雨水图片上也能达到很好的效果。
- 还没有人留言评论。精彩留言会获得点赞!