一种基于bert模型的文本数据处理方法及装置与流程
本发明涉及自然语言处理领域,尤其涉及一种基于bert模型的文本数据处理方法及装置。
背景技术:
1、随着信息化时代的快速发展,用户经常会受到违规异常文本的骚扰。因此,需要对违规异常文本进行识别和拦截。现有技术通常通过正则匹配,谐音匹配,文字组合,文本黑名单等方式对用户违规异常文本进行拦截,通过在数据库中存储异常文本的关键词汇,并对发送中的文本进行词汇匹配,在异常文本关键词汇匹配成功时,对发送中的文本进行拦截;
2、但现有的拦截技术人力成本大,需要花费非常大的精力维护拦截语料库;但由于只能通过识别字体是否相似来判断异常文本,不仅难以拦截更换了其它同音或同形状字体的异常文本,而且也容易错误拦截字体相似但没有异常的文本,从而导致异常文本的识别准确率很低。
3、因此,亟需文本数据处理策略,来解决异常文本的识别准确率很低的问题。
技术实现思路
1、本发明实施例提供一种基于bert模型的文本数据处理方法及装置,以提高异常文本的识别准确率。
2、为了解决上述问题,本发明一实施例提供一种基于bert模型的文本数据处理方法,包括:
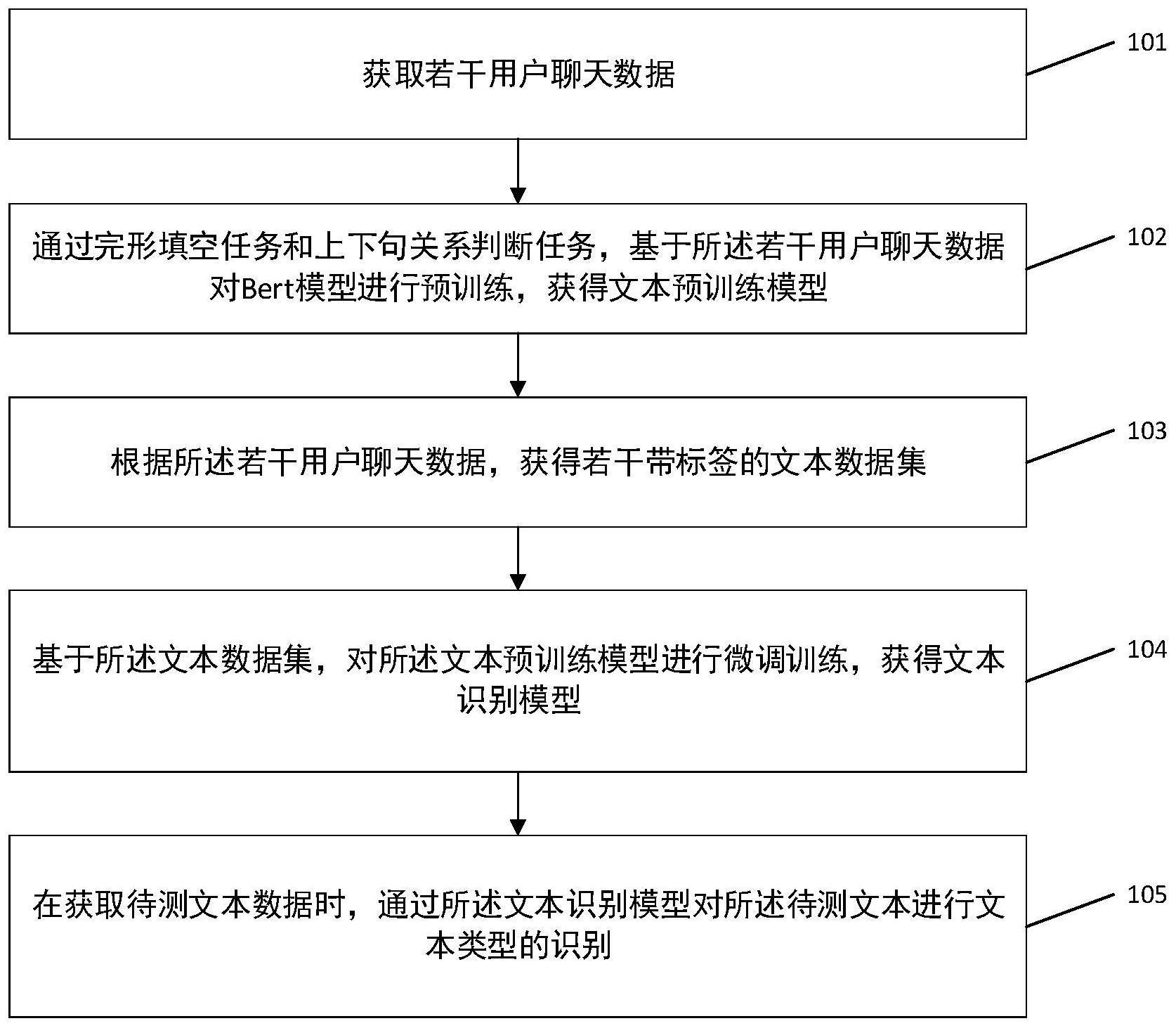
3、获取若干用户聊天数据;
4、通过完形填空任务和上下句关系判断任务,基于所述若干用户聊天数据对bert模型进行预训练,获得文本预训练模型;
5、根据所述若干用户聊天数据,获得若干带标签的文本数据集;
6、基于所述文本数据集,对所述文本预训练模型进行微调训练,获得文本识别模型;
7、在获取待测文本数据时,通过所述文本识别模型对所述待测文本进行文本类型的识别。
8、作为上述方案的改进,所述通过所述文本识别模型对所述待测文本进行文本类型的识别,具体为:
9、所述文本识别模型包括:向量化层、transformer网络层和分类网络层;
10、所述文本识别模型的向量化层对所述待测文本进行向量化操作,获得文本向量;
11、将所述文本向量传输到所述文本识别模型的transformer网络层中,获得若干文字注意力权重向量;
12、将所述若干文字注意力权重向量输入到所述文本识别模型的分类网络层,获得每个文字的单位向量;
13、将每个文字的单位向量分别输入到预设的概率函数中,计算获得每个文字的若干类别概率;
14、根据所述若干类别概率,获得所述待测文本的文本类型。
15、作为上述方案的改进,所述完形填空任务,包括:
16、根据随机概率算法,对每个用户聊天数据中预设数量的文字进行遮掩,获得每个用户聊天数据对应的文本遮掩数据;
17、将每个文本遮掩数据输入到bert模型中进行遮掩文本识别,获得文本遮掩数据对应的猜测答案;
18、计算每个文本遮掩数据的猜测答案和遮掩原答案之间的匹配度,对匹配度进行判断:当匹配度小于第一匹配值时,根据匹配度更新bert模型的参数,并基于更新后的bert模型的参数再次对本次用户聊天数据进行完形填空任务的操作;当匹配度大于等于第一匹配值时,对下一组用户聊天数据进行完形填空任务的操作,直到所有用户聊天数据的猜测答案和遮掩原答案之间的匹配度大于等于第一匹配值后,结束完形填空任务。
19、作为上述方案的改进,所述上下句关系判断任务,包括:
20、根据随机概率算法,对所述若干用户聊天数据进行顺序调整,获得若干上下句随机数据集;其中,所述上下句随机数据集包括:上下句集合和上下句集合对应的连贯结果;
21、将每个所述上下句随机数据集分别输入到bert模型中进行上下句关系判断,获得每个所述上下句随机数据集的判断结果;
22、对每个上下句随机数据集的连贯结果和判断结果进行比较:若不一致,则更新bert模型的参数,并基于更新后的bert模型的参数再次对上下句随机数据集进行上下句关系判断任务的操作;若一致,则对下一组上下句随机数据集进行上下句关系判断任务的操作,直到所有上下句随机数据集的连贯结果和判断结果的比较都为一致时,结束上下句关系判断任务。
23、作为上述方案的改进,bert模型同时执行完形填空任务和上下句关系判断任务,在每一次bert模型的参数更新后,bert模型基于更新后的参数执行下一完形填空任务和下一上下句关系判断任务。
24、作为上述方案的改进,所述根据所述若干用户聊天数据,获得若干带标签的文本数据集,具体为:对所述若干用户聊天数据根据标签类型进行分类,获得若干带标签的文本数据集;其中,所述带标签的文本数据集包括:用户聊天数据和用户聊天数据对应的标签类型。
25、作为上述方案的改进,所述根据所述若干用户聊天数据,获得若干带标签的文本数据集,具体为:对所述若干用户聊天数据根据标签类型进行分类,获得若干带标签的文本数据集;其中,所述带标签的文本数据集包括:用户聊天数据和用户聊天数据对应的标签类型。
26、相应的,本发明一实施例还提供了一种基于bert模型的文本数据处理装置,包括:数据获取模块、预训练模块、标记模块、微调训练模块和结果生成模块;
27、所述数据获取模块,用于获取若干用户聊天数据;
28、所述预训练模块,用于通过完形填空任务和上下句关系判断任务,基于所述若干用户聊天数据对bert模型进行预训练,获得文本预训练模型;
29、所述标记模块,用于根据所述若干用户聊天数据,获得若干带标签的文本数据集;
30、所述微调训练模块,用于基于所述文本数据集,对所述文本预训练模型进行微调训练,获得文本识别模型;
31、所述结果生成模块,用于在获取待测文本数据时,通过所述文本识别模型对所述待测文本进行文本类型的识别。
32、作为上述方案的改进,所述通过所述文本识别模型对所述待测文本进行文本类型的识别,具体为:
33、所述文本识别模型包括:向量化层、transformer网络层和分类网络层;
34、所述文本识别模型的向量化层对所述待测文本进行向量化操作,获得文本向量;
35、将所述文本向量传输到所述文本识别模型的transformer网络层中,获得若干文字注意力权重向量;
36、将所述若干文字注意力权重向量输入到所述文本识别模型的分类网络层,获得每个文字的单位向量;
37、将每个文字的单位向量分别输入到预设的概率函数中,计算获得每个文字的若干类别概率;
38、根据所述若干类别概率,获得所述待测文本的文本类型。
39、作为上述方案的改进,所述完形填空任务,包括:
40、根据随机概率算法,对每个用户聊天数据中预设数量的文字进行遮掩,获得每个用户聊天数据对应的文本遮掩数据;
41、将每个文本遮掩数据输入到bert模型中进行遮掩文本识别,获得文本遮掩数据对应的猜测答案;
42、计算每个文本遮掩数据的猜测答案和遮掩原答案之间的匹配度,对匹配度进行判断:当匹配度小于第一匹配值时,根据匹配度更新bert模型的参数,并基于更新后的bert模型的参数再次对本次用户聊天数据进行完形填空任务的操作;当匹配度大于等于第一匹配值时,对下一组用户聊天数据进行完形填空任务的操作,直到所有用户聊天数据的猜测答案和遮掩原答案之间的匹配度大于等于第一匹配值后,结束完形填空任务。
43、作为上述方案的改进,所述上下句关系判断任务,包括:
44、根据随机概率算法,对所述若干用户聊天数据进行顺序调整,获得若干上下句随机数据集;其中,所述上下句随机数据集包括:上下句集合和上下句集合对应的连贯结果;
45、将每个所述上下句随机数据集分别输入到bert模型中进行上下句关系判断,获得每个所述上下句随机数据集的判断结果;
46、对每个上下句随机数据集的连贯结果和判断结果进行比较:若不一致,则更新bert模型的参数,并基于更新后的bert模型的参数再次对上下句随机数据集进行上下句关系判断任务的操作;若一致,则对下一组上下句随机数据集进行上下句关系判断任务的操作,直到所有上下句随机数据集的连贯结果和判断结果的比较都为一致时,结束上下句关系判断任务。
47、作为上述方案的改进,bert模型同时执行完形填空任务和上下句关系判断任务,在每一次bert模型的参数更新后,bert模型基于更新后的参数执行下一完形填空任务和下一上下句关系判断任务。
48、作为上述方案的改进,所述根据所述若干用户聊天数据,获得若干带标签的文本数据集,具体为:对所述若干用户聊天数据根据标签类型进行分类,获得若干带标签的文本数据集;其中,所述带标签的文本数据集包括:用户聊天数据和用户聊天数据对应的标签类型。
49、作为上述方案的改进,所述根据所述若干用户聊天数据,获得若干带标签的文本数据集,具体为:对所述若干用户聊天数据根据标签类型进行分类,获得若干带标签的文本数据集;其中,所述带标签的文本数据集包括:用户聊天数据和用户聊天数据对应的标签类型。
50、相应的,本发明一实施例还提供了一种计算机终端设备,包括处理器、存储器以及存储在所述存储器中且被配置为由所述处理器执行的计算机程序,所述处理器执行所述计算机程序时实现如本发明所述的一种基于bert模型的文本数据处理方法。
51、相应的,本发明一实施例还提供了一种计算机可读存储介质,所述计算机可读存储介质包括存储的计算机程序,其中,在所述计算机程序运行时控制所述计算机可读存储介质所在设备执行如本发明所述的一种基于bert模型的文本数据处理方法。
52、由上可见,本发明具有如下有益效果:
53、本发明提供了一种基于bert模型的文本数据处理方法,通过完形填空任务和上下句关系判断任务,将获取到用户聊天数据进行bert模型的预训练,获得文本预训练模型,挖掘bert模型的语义理解能力,使得bert模型能够学习用户聊天数据的规律,为文本类型的识别奠定了基础。将获得的带标签文本数据集输入到文本预训练模型中进行微调训练,继而根据生成的文本识别模型对待测文本数据进行文本类型识别。本发明基于完形填空任务和上下句关系判断任务,充分挖掘bert模型的语义理解能力,使得生成的文本识别模型具有泛化能力,能够准确判断意思相近的文本,并归为同一文本类型,有利于提高文本类型识别的准确性。通过本发明训练获得的文本识别模型,能够有效识别文本,继而能够与文本拦截技术结合,实现异常文本的准确拦截。
- 还没有人留言评论。精彩留言会获得点赞!