基于子空间分类的小样本行为识别方法及系统
本发明涉及计算机识别,具体涉及一种基于子空间分类的小样本行为识别方法及系统。
背景技术:
1、生活中无处不在的移动设备方便了视频信息的记录、存储和传输,如智能手机、监控视频等。随着智慧城市的建设,视频监控已经部署在了各个公共场所,对公共安全的维护起到了重要的作用。但由于数据的海量性,仅靠人工的方式识别耗时耗力,因此行为识别的研究显得愈发重要,其中异常行为如摔倒、斗殴等的识别抓取更是智慧化建设的关键点。面对异常行为样本稀少的现状,小样本行为识别具有重要的研究意义。
2、目前,现有的小样本行为识别方法多采用“嵌入网络”+“分类器”的网络模型。在训练阶段,将数据集分解为不同的任务,去学习类别变化的情况下模型的泛化能力,使得模型学会不同任务中的共性部分,比如如何提取重要特征及比较样本相似等。在测试阶段,面对全新的不同于训练集的类别,不需要变动已有模型就可以完成分类。经典的小样本分类方法孪生网络采用相同的网络结构分别对两幅图像提取特征,通过计算特征之间的l1距离预测样本类别。匹配网络采用融合了注意力机制的lstm网络提取特征,通过余弦距离度量特征之间的差距进行样本分类。
3、在fu等人提出的amefu-net模型方法中,首先提取视频数据集的深度信息,然后采用特征提取器分别提取rgb特征和深度特征,融合两种特征以达到特征增强的效果,最后将支持集特征与查询集特征送入小样本分类器进行分类。amefu-net采用的小样本分类器为原型网络分类器,需要从高维数据中学习一个对称函数以实现分类器,通过平均池化的方式实现对称函数,将支持集每一类的特征向量取均值以创建一个原型表示,用欧几里得距离作为距离度量计算待查询视频的特征向量与所有类的原型表示之间的相似度,以得到待查询视频的预测类别标签。但对于样本量少的情况,简单的通过均值计算得到的原型表示并不可靠,当支持集背景杂乱、与查询视频的差异大时,很难得到正确的分类预测标签。
4、综上,孪生网络存在过程复杂的问题,在任务的shot数大于1时,需要对比查询集样本特征与支持集每个样本特征之间的相似度,从而分析目标的类别。匹配网络受到非参量化算法的限制,每次迭代过程的计算量会随着支持集样本数的增加而快速增长,计算速度慢。由于样本的稀缺性,原型网络直接通过特征均值计算得到的原型表示代表性不强,存在会使原本与查询集样本相似的支持集样本受同一类内其他样本的干扰而错误分类的问题。
技术实现思路
1、本发明的目的在于提供一种能够充分利用支持集每类中所有样本特征,且不需要与同类内的每个样本特征重复计算距离,提高了预测精度的基于子空间分类的小样本行为识别方法及系统,以解决上述背景技术中存在的至少一项技术问题。
2、为了实现上述目的,本发明采取了如下技术方案:
3、一方面,本发明提供一种基于子空间分类的小样本行为识别方法,包括:
4、获取待识别的图像;
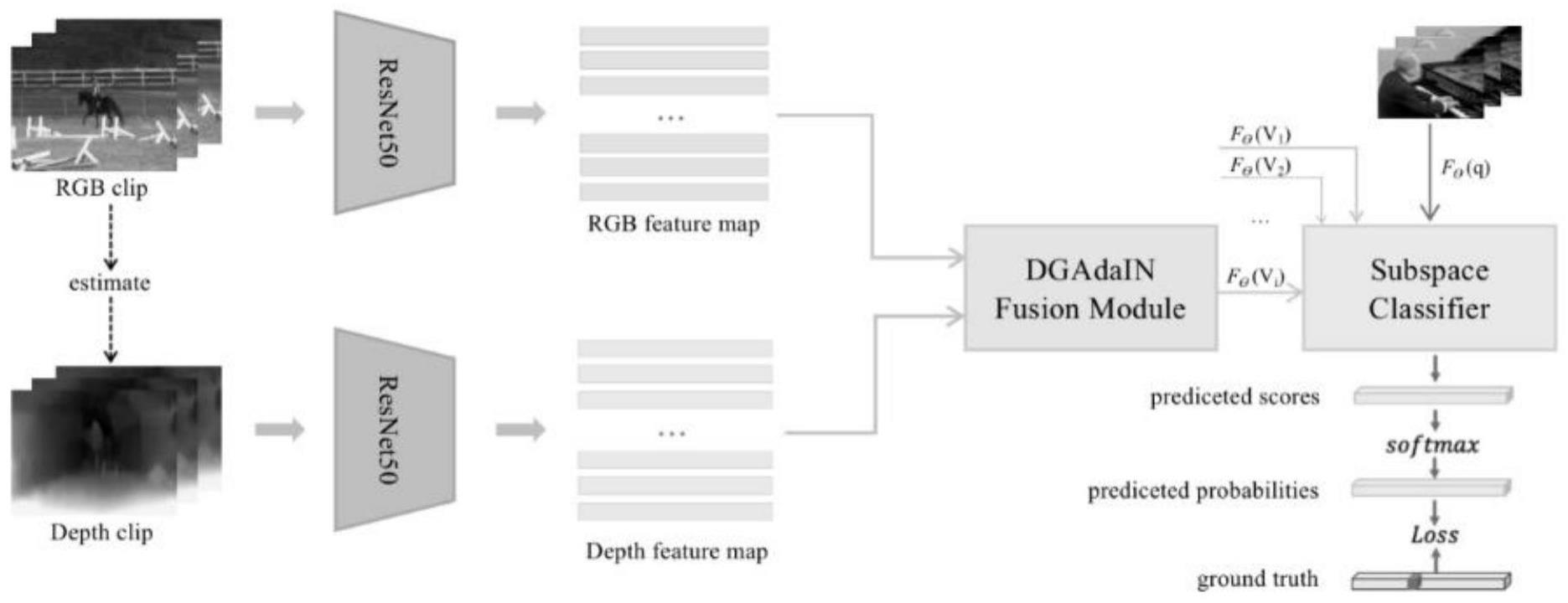
5、利用预先训练好的小样本行为识别模型对所述获取的待识别图像进行处理,得到图像中行为识别结果;其中,所述预先训练好的小样本行为识别模型由训练集训练得到,所述训练集包括多张图像以及标注图像中行为分布特征的标签;所述小样本行为识别模型包括深度估计网络、特征提取网络、特征融合网络和识别网络,所述深度估计网络用于将rgb图像进行深度估计,得到深度图像;所述特征提取网络用于提取rgb图像的特征和深度图像的特征;所述特征融合网络用于将提取的rgb图像特征和深度图像特征进行融合,所述识别网络用于基于子控件分类器,结合于融合后的特征进行小样本行为识别计算。
6、优选的,训练所述小样本行为识别模型时,采用数据集为一个包含多个行为类别的多个视频组成,将数据集中每一类的每个视频样本分为一组图像帧rgb frames,并统计每组图像帧的帧数n_frames;对于分帧后的数据集中的每张图像,首先将其进行大小调整,然后随机裁剪;深度估计网络中,用monodepth2 module作为深度估计器,对处理后的数据集图像进行深度估计,得到深度图像。
7、优选的,特征提取网络中,使用特征提取器imagenet pretrained resnet-50提取rgb图像特征和深度图像特征;其中,首先训练用于提取rgb图像特征的rgb子模型和用于提取深度图像特征的深度子模型,rgb子模型和深度子模型的特征提取网络以resnet-50为主干网络,并将resnet-50中的最后一个完全连接层替换为各自的全连接层作为分类器,特征信息提取层为由卷积神经网络生成的特征编码器,从输入层的图像中提取信息处理层所需的图像特征,以得到rgb特征图和深度特征图。
8、优选的,在特征融合网络中,得到的rgb特征向量和深度特征向量通过dgadainfusion module做特征融合,得到融合特征向量。
9、优选的,dgadain fusion module获取的数据为提取的rgb特征向量和深度特征向量,处理后得到融合后的特征向量;模块输入的批处理表示为x∈rb×d×l,其中b为批次大小,d为单个视频样本分成的一组图片帧的帧数,l为每一帧的特征维数;
10、
11、dgadain模块f(irgb,id)的输入为一个rgb输入批irgb和一个深度输入批id,gs(·)和gb(·)为可学习的全连接层,f(irgb,id)的输出作为尺度因子γ和移位因子β进行处理,将rgb特征变形,用于自适应地学习深度特征图。
12、优选的,在识别网络中,将得到的支持集融合特征送入子空间分类器中,求支持集中每一类中所有样本的特征均值;在子空间分类器中,用支持集样本特征减去所属类的特征均值,对支持集每一类样本得到一个新的样本表示集合;在子空间分类器中,对新的样本表示集合进行奇异值分解,得到得到子空间投影矩阵;将查询集样本特征送入子空间分类器,求查询样本特征到每个类别子空间的距离;利用softmax函数计算查询样本属于各个行为类别的概率;采用grassmann流形以最大化不同子空间之间的距离。
13、第二方面,本发明提供一种基于子空间分类的小样本行为识别系统,包括:
14、获取模块,用于获取待识别的图像;
15、识别模块,用于利用预先训练好的小样本行为识别模型对所述获取的待识别图像进行处理,得到图像中行为识别结果;其中,所述预先训练好的小样本行为识别模型由训练集训练得到,所述训练集包括多张图像以及标注图像中行为分布特征的标签;所述小样本行为识别模型包括深度估计网络、特征提取网络、特征融合网络和识别网络,所述深度估计网络用于将rgb图像进行深度估计,得到深度图像;所述特征提取网络用于提取rgb图像的特征和深度图像的特征;所述特征融合网络用于将提取的rgb图像特征和深度图像特征进行融合,所述识别网络用于基于子控件分类器,结合于融合后的特征进行小样本行为识别计算。
16、第三方面,本发明提供一种非暂态计算机可读存储介质,所述非暂态计算机可读存储介质用于存储计算机指令,所述计算机指令被处理器执行时,实现如上所述的基于子空间分类的小样本行为识别方法。
17、第四方面,本发明提供一种计算机程序产品,包括计算机程序,所述计算机程序当在一个或多个处理器上运行时,用于实现如上所述的基于子空间分类的小样本行为识别方法。
18、第五方面,本发明提供一种电子设备,包括:处理器、存储器以及计算机程序;其中,处理器与存储器连接,计算机程序被存储在存储器中,当电子设备运行时,所述处理器执行所述存储器存储的计算机程序,以使电子设备执行实现如上所述的基于子空间分类的小样本行为识别方法的指令。
19、本发明有益效果:充分利用支持集每一类中的所有样本特征,通过为每一类行为构建子空间来进行分类,而非直接地使用特征均值;将每一类的样本特征凝练为一个子空间,直接计算查询样本特征到子空间的距离,而非依次计算查询样本特征到每一类中每个样本的距离,减少计算量。
20、本发明附加方面的优点,将在下述的描述部分中更加明显的给出,或通过本发明的实践了解到。
- 还没有人留言评论。精彩留言会获得点赞!