一种基于上下文的语义匹配方法、装置以及设备与流程
本发明涉及自然语言处理,尤其涉及一种基于上下文的语义匹配方法、装置以及设备。
背景技术:
1、随着互联网时代发展,无数信息爆炸式涌现,人工处理大量文本十分复杂并且耗时。意图识别,主要是从大量销售以及客户对话文本资料中自动匹配业务场景所需的特定语义标签,将海量内容自动分类并重构,能够从非结构化的文本中抽取重要信息,利用深度学习模型,识别文本中的语义。意图识别涉及任务有:关键词匹配、语义匹配等,以汽车领域为例,通过对汽车销售场景中的对话文本进行语义匹配,我们可以获得一段对话中销售人员的相关话术标签,例如客户迎接、车身颜色介绍等,从人工抽检转变为全量自动质检与评分,解决抽样质检覆盖率低,人工质检主观性强、效率低的问题。
2、随着对话文本轮数的增多,一次销售过程中可能涉及多轮对话交互,仅仅采用单句文本进行匹配,无法真实还原销售人员以及用户的意图。例如,图1所示的对话中,销售员说的“小虎你好”,通过单句文本匹配,其会被误吸为客户迎接类别,但是通过上文中销售员说的“试试导航”和/或下文中导航说的“请讲”,才能推断出这句话的实际意图为无意图。
3、因此,需要引入相关上下文信息进行意图推理,才能获得真实意图。
4、现有的上下文推理方法分为两种:
5、1、滑窗方案:为了获得待匹配句子相关上下文,通过滑动窗口的方式,取该句子的前后n个token或者m句话,与待匹配句子拼接作为附加信息,辅助语义匹配模型进行知识库句子匹配。
6、滑窗方式仅仅对文本进行了相应的拼接,针对这种类型的句子匹配,为了使得模型效果较好,需要构建一个带上下文的知识库供语义匹配模型匹配,因此需要进行大量标注,构建人工成本高。同时,由于上下文说法较为丰富,构建的上下文知识库匹配效果并不鲁棒。
7、2、上下文语义表征:现阶段,深度学习针对上下文问题一般通过模型对上下文文本进行编码,获得上下文的语义表征,将其和待匹配句子进行融合,再进行判断。具体方法如下:
8、1)直接拼接:将通过编码器编码获得的上下文表示以及句子表示拼接,通过全连接层,获得对应类别概率分布。
9、2)点乘:将通过编码器编码获得的上下文表示矩阵以及句子表示矩阵点乘,通过全连接层,获得对应类别概率分布。
10、3)门控单元融合:将通过编码器编码获得的上下文表示矩阵以及句子通过门控单元,获得输出的融合表示。将融合表示通过全连接层,获得对应类别概率分布。
11、4)编码器优化:在编码过程,将上下文表示与句子表示融合输出融合表示。
12、但是,由于上文的语义表征方法将意图识别作为一个分类任务,使得分类模型支持的类别是固定的,不具备扩展性。当需要添加新类别时,只能重新训练分类模型,失去了语义匹配模型的优点。
13、另外,上文提到的前三种上下文语义表征方法,对编码获得的上下文表示做简单的融合,即可引入上下文信息,辅助语义匹配模型进行预测,但是效果提升有限,在现阶段的汽车业务场景无明显效果提升。同时,第四种编码器优化方法中,模型参数呈指数级增加,推理速度明显变慢,且效果不稳定,在实际汽车应用场景中无法真正投入使用。
技术实现思路
1、鉴于上述,本发明旨在提供一种基于上下文的语义匹配方法、装置以及设备,通过将待匹配句子与上下文进行拼接,并输入多项选择阅读理解模型进行语义预测,采用多项选择阅读理解方案重构该任务,模型简单,可以明显提升推理效率,并且模型具有可扩展性。同时,知识库中的数据为句子和标签,无需带上下文的数据库,降低了模型构建成本,提高了模型的鲁棒性。
2、本发明采用的技术方案如下:
3、第一方面,本发明提供了一种基于上下文的语义匹配方法,包括:
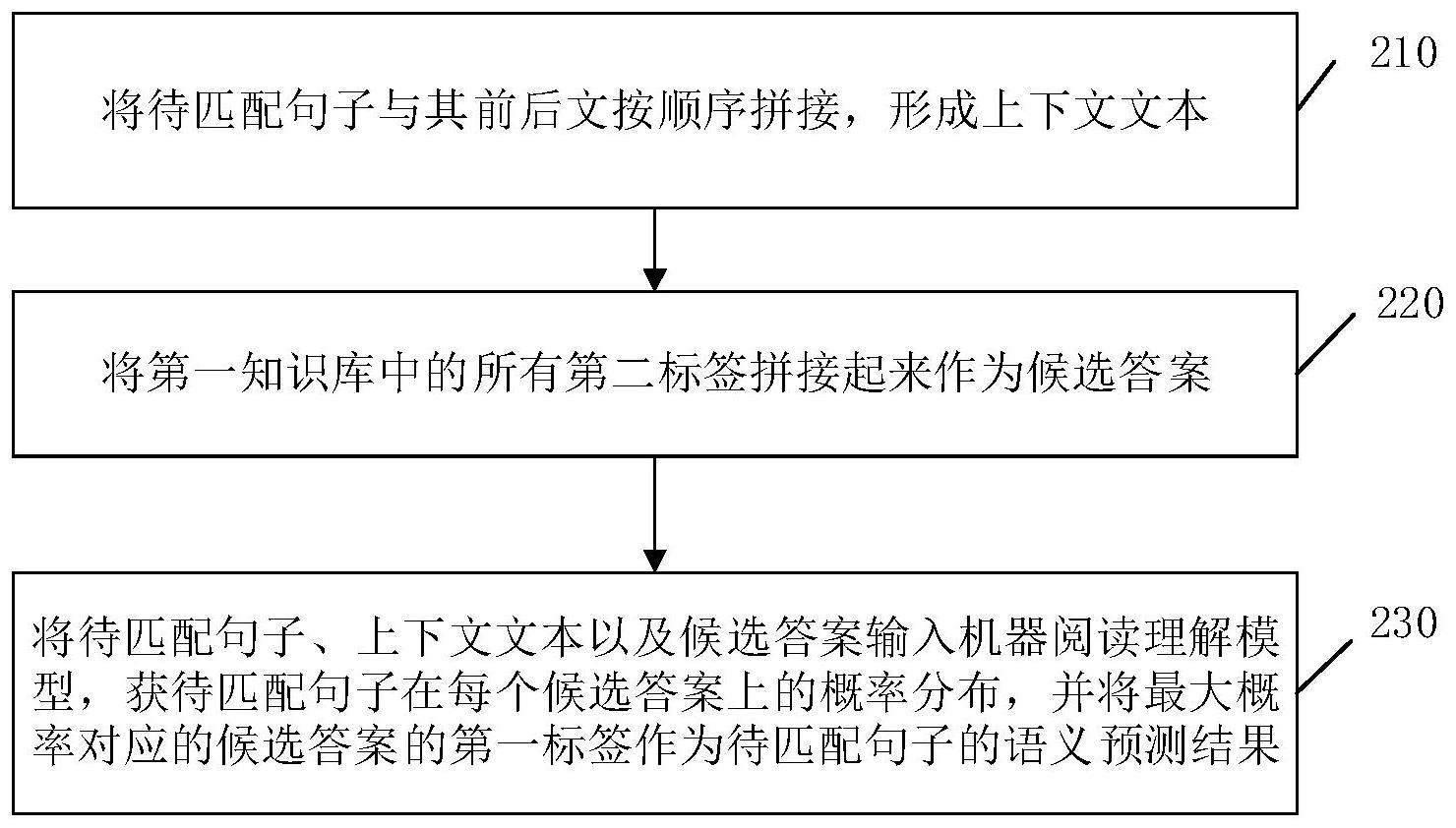
4、将待匹配句子与其前后文按顺序拼接,形成上下文文本;
5、将第一知识库中的所有第二标签拼接起来作为候选答案;
6、将待匹配句子、上下文文本以及候选答案输入机器阅读理解模型,获得待匹配句子在每个候选答案上的概率分布,并将最大概率对应的候选答案的第一标签作为待匹配句子的语义预测结果。
7、在其中一种可能的实现方式中,语义匹配方法还包括:
8、对第一知识库中的第二标签进行筛选,获得候选标签;
9、将所有候选标签拼接起来,作为候选答案。
10、在其中一种可能的实现方式中,对第一知识库中的第二标签进行筛选,获得候选标签,包括:
11、将待匹配句子输入匹配模型,获得匹配模型中的第一知识库中每个带标签句子与待匹配句子的第一匹配值,并获得第一知识库中每个种类的第二标签与待匹配句子的第二匹配值,其中每个带标签句子对应一个种类的第二标签;
12、将所有第二标签的第二匹配值排序,将预设数量的第二匹配值最大的第二标签作为候选标签。
13、在其中一种可能的实现方式中,语义匹配方法还包括:
14、判断在语义匹配过程中,待匹配句子是否需要上下文;
15、若是,则利用机器阅读理解模型进行语义预测。
16、在其中一种可能的实现方式中,将第二匹配值最大的标签作为待匹配句子的第三标签。
17、在其中一种可能的实现方式中,若在语义匹配过程中,待匹配句子不需要上下文,则将第三标签作为待匹配句子的语义预测结果。
18、在其中一种可能的实现方式中,若预设数量的第二匹配值最大的标签中不包括无意图标签,则将候选标签中第二匹配值最小的标签替换为无意图标签。
19、在其中一种可能的实现方式中,第一知识库中每个种类的第二标签与待匹配句子的匹配值为所有具有种类的第二标签的带标签句子的第一匹配值的平均值。
20、在其中一种可能的实现方式中,对匹配模型进行训练时,输入数据为不带标签句子,输出为不带标签句子的第四标签。
21、第二方面,本发明提供了一种基于上下文的语义匹配装置,包括推理模块,推理模块包括第一拼接模块、第二拼接模块以及预测模块;
22、第一拼接模块用于将待匹配句子与其前后文按顺序拼接,形成上下文文本;
23、第二拼接模块用于将第一知识库中的所有第二标签拼接起来作为候选答案;
24、预测模块用于将待匹配句子、上下文文本以及候选答案输入机器阅读理解模型,获得待匹配句子在每个候选答案上的概率分布,并将最大概率对应的候选答案的第一标签作为待匹配句子的语义预测结果。
25、在其中一种可能的实现方式中,推理模块还包括筛选模块,筛选模块用于对第一知识库中的第二标签进行筛选,获得候选标签;
26、第二拼接模块用于将所有候选标签拼接起来,作为候选答案。
27、在其中一种可能的实现方式中,筛选模块包括匹配模块和排序模块;
28、匹配模块用于将待匹配句子输入匹配模型,获得匹配模型中的第一知识库中每个带标签句子与待匹配句子的第一匹配值,并获得第一知识库中每个种类的第二标签与待匹配句子的第二匹配值,其中每个带标签句子对应一个种类的第二标签;
29、排序模块用于将所有第二标签的第二匹配值排序,将预设数量的第二匹配值最大的第二标签作为候选标签。
30、在其中一种可能的实现方式中,筛选模块还包括替换模块,替换模块用于在预设数量的第二匹配值最大的标签中不包括无意图标签时,将候选标签中第二匹配值最小的标签替换为无意图标签。
31、第三方面,本发明提供了一种基于上下文的语义匹配设备,包括:
32、一个或多个处理器、存储器以及一个或多个计算机程序,其中一个或多个计算机程序被存储在存储器中,一个或多个计算机程序包括指令,当指令被语义匹配设备执行时,使得语义匹配设备执行上述的基于上下文的语义匹配方法。
33、本发明的构思在于,提供一种基于上下文的语义匹配方法、装置以及设备,通过将待匹配句子与上下文进行拼接,并输入机器阅读理解模型进行语义预测,采用多项选择阅读理解方案重构该任务,模型简单,可以明显提升推理效率,并且模型具有可扩展性。同时,知识库中的数据为单个句子及其标签,无需带上下文的数据,降低了模型构建成本,提高了模型的鲁棒性。本发明通过对第一知识库中标签的筛选,为机器阅读理解模型提供匹配值最大的预设数量的标签,有效提升了模型的预测效果。另外,本发明按照是否需要上下文进行语义匹配,将待匹配句子分为两类,仅将需要上下文的句子送入机器阅读理解模型进行预测,可以有效提升推理速度。
- 还没有人留言评论。精彩留言会获得点赞!