一种应用在低照度环境下的煤矿井下人员动作识别方法
本发明涉及视频识别领域,具体是一种应用在低照度环境下的煤矿井下人员动作识别方法。
背景技术:
1、煤矿井下是一个环境多变复杂,工作环节较多,作业人员数量较多,设备庞大集中,综合性危险系数较大的产业,每时每刻都可能出现安全隐患,容易发生安全事故。由于煤矿井下的环境十分复杂及恶劣,井下作业人员需要长时间在这样一个艰苦和危险的环境里进行工作,多重的复杂因素将会给他们造成很大的影响。因此没有强大的自我安全行为能力,应付这样危险困难的工作环境将会捉襟见肘。
2、煤矿井下对人员动作识别最大的难点在于低照度环境下动作识别的识别精度很低、识别煤矿井下多个工作人员动作的效果很差。煤矿井下人员动作识别本质上可以看作是视频的暗光增强任务、动作识别任务的有机统一。通过对视频进行暗光增强,获得更丰富的语义特征,从而更好地完成动作识别任务。
3、传统的暗光增强方法,如基于retinex理论的深度网络和基于图像融合的深度网络,可以通过图像的光照分解和图像的多特征融合来实现暗光增强,并且多是需要成对数据的有监督学习,需要获取大量的成对的标记数据进行模型训练,这使得模型训练的时间和人工成本变高。
4、传统的动作识别方法,如双流网络和3d网络,可以通过卷积网络实现动作识别,但是双流网络需要抽取视频帧的光流作为时间流网络的输入,而抽取光流是一项耗时又耗计算机资源的任务;3d网络在捕获局部时空区域内的短程模式方面是有效的,但是它们不能对超出其接收域的时空依赖关系进行建模,为了解决这个问题,3d网络需要对视频中所有的时空位置上使用大量的3d卷积滤波器,这大大增加了3d网络的计算成本。
技术实现思路
1、为了改进现有技术的不足,本发明提出了一种应用在低照度环境下的煤矿井下人员动作识别方法,解决因煤矿井下光照低、人员多、环境复杂导致无法精准快速识别人员动作的问题。
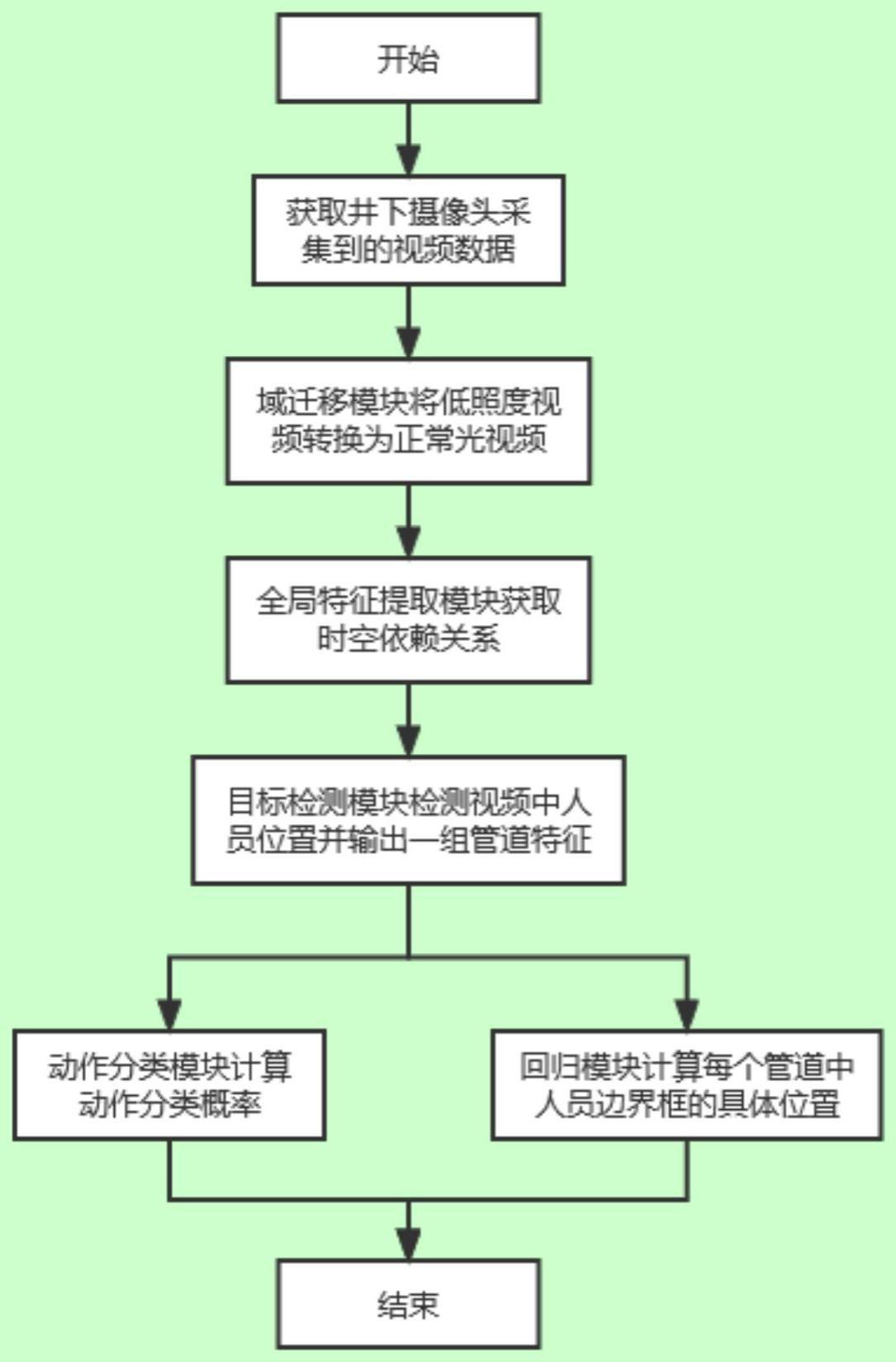
2、本发明的目的是这样实现的:一种应用在低照度环境下的煤矿井下人员动作识别方法,利用煤矿井下人员作业的视频数据,实现在低照度环境下的人员动作识别;所述的动作识别方法包括:风格转换模块、全局特征提取模块、目标检测模块、动作分类模块和回归模块;
3、将视频数据重采样后,经过风格转换模块,把低照度下的视频数据转换为正常光下的视频数据;再经过全局特征提取模块提取视频帧序列的全局时空特征;再经过目标检测模块检测视频中的人员,从视频帧序列中提取人员动作管道的特征表示;最后将管道特征分别经过回归模块和动作分类模块,计算每个管道的位置和属于每个动作的概率。
4、进一步,具体步骤如下:
5、步骤1:采集煤矿井下摄像头采集的视频数据,进行重采样,得到预处理后视频数据;
6、步骤2:将步骤1得到的预处理后视频数据通过风格转换模块,得到正常光下视频数据;
7、步骤3:将步骤2中得到的正常光下视频数据通过全局时空特征提取模块,提取全局时空特征;
8、步骤4:将步骤3中得到的全局时空特征通过目标检测模块,得到一组特定的管道特征;
9、步骤5:将步骤4中得到的特定的管道特征通过动作分类模块和回归模块,计算每个管道的位置和属于每个动作的概率;
10、步骤6:将步骤2中得到的正常光下视频数据分成训练样本和测试样本,使用设计的损失函数来训练所属应用在低照度环境下的动作识别模型。
11、进一步,在步骤1中,对采集的视频数据进行重采样;
12、所述视频数据重采样的方法为:
13、获取到的视频数据,用表示,其中lv为视频的总帧数,ut为视频u的第t个rgb帧,即将视频u采样成帧大小为h0×w0×c,帧数为t,通道数为c,即
14、进一步,在步骤2中,使用风格转换模块对步骤1得到的预处理后视频数据u0进行风格转换,实现暗光下的视频转换为正常光下视频数据u1;
15、所述风格转换模块是由改进的cyclegan组成,使用该模块对视频数据进行风格转换,将暗光下的视频转换为正常光下的视频,丰富视频中人物和场景的信息,使得检测任务和分类任务更加准确。
16、cyclegan是一种学习将图像从源域转换到目标域的方法。cyclegan包含两组生成对抗网络;每组生成对抗网络包含一个生成器和一个鉴别器;生成器和鉴别器组成翻译器,将图像从x域翻译到y域,反之亦然;采用二组实现,第一组生成对抗网络由煤矿井下暗光的视频图像生成正常光下的视频图像的网络,包括生成器网络gvt和鉴别器网络dvt;第二组生成对抗网络由正常光下的视频图像生成煤矿井下暗光的视频图像,包括生成器网络gtv和鉴别器网络dtv;
17、cyclegan的网络结构中,生成器的编码解码结构网络,利用resnet50网络的特征提取层作为编码网络,利用对应的反卷积网络作为解码网络;鉴别器采用vgg19网络结构;网络的输出包括判断真假的分支和分类的分支,用于图像生成真实的对应模态的图像,并且身份标签不发生改变;
18、cyclegan网络的损失函数由两部分组成,即loss=lossgan+losscycle,其中lossgan保证生成器和判别器相互进化,进而保证生成器能产生更真实的图片;losscycle保证生成器的输出图片与输入图片风格不同,而内容相同;lossgan和losscycle具体为:
19、
20、
21、为了保证迁移后的图像和原图像在颜色和边缘纹理结构上保持相似,在原cyclegan网络损失函数的基础上加上结构损失,表示为
22、所述结构损失表示为:
23、
24、所述为结构相似性损失函数,它可以衡量两个图像的相似度,表示为:
25、
26、其中,μx,μy为像素值的期望,σx,σy为像素值的方差,σxy为协方差,c1,c2为常数;
27、所述为多尺度结构相似性损失函数,它能保留图像的边缘和细节,表示为:
28、
29、其中βm,γm表示两项之间的相对重要性。
30、进一步,所述步骤3,步骤2的到的正常光下视频数据u1通过全局时空特征提取模块,提取全局时空特征;
31、所述全局时空特征提取模块使用的主干网络为在kinectics-400数据集预训练好的i3d网络;视频数据经过主干网络提取时空特征其中t′是时间维度,c′是特征维度。
32、进一步,所述步骤4,将步骤3得到的全局时空特征通过目标检测模块,得到一组特定的管道特征;
33、所述特定的管道特征为视频逐帧图像检测出的人员边界预测构成的序列,用于描述每一帧中人员的边界框预测;
34、所述目标检测模块由一个编码器组和一个解码器组组成;
35、所述编码器组由m个编码器串联,其作用是对步骤3中的全局时空特征进行时空建模,进一步抽取时空特征编码器组第一个编码器输入为步骤3中的全局时空特征fb的线性映射叠加3维位置编码,表示为第i个编码器的输入为第i-1个编码器的输出最后一个编码器的输出为fen;
36、所述解码器组由m个解码器串联,其作用是为了生成当前视频数据的一组管道特征ftub,n是管道的数量;解码器组第一个解码器输入为编码器组的输出fen和一组随机初始化的查询向量其中n是查询向量的总数,tout是tqi包含的帧数,第i个解码器的输入为编码器组的输出fen和第i-1个解码器的输出最后一个解码器的输出为ftub。
37、进一步,所述编码器组的每一个编码器都由一个自注意力层、两个归一化层和一个前馈神经网络组成;
38、以第i个编码器为例,i={1,…,m},其具体处理流程为:
39、步骤4-1-1,将输入序列e(i)先通过归一化层,分别映射为三个不同矩阵q、k、v,
40、q=σq(ln(e(i)))
41、k=σk(ln(e(i)))
42、v=σv(ln(e(i)))
43、其中σ(*)为线性变换;
44、步骤4-1-2,将q、k、v输入到自注意力层计算点积注意力,具体为:
45、
46、步骤4-1-3,将sa(q,k,v)进行残差连接得到z′(i),具体为:
47、z′(i)=sa(q,k,v)+e(i)
48、步骤4-1-4,将z′(i)通过多层感知机,得到第i个编码器的输出z(i),具体为:
49、z(i)=mlp(z′(i))+z′(i)
50、其中,mlp(*)是多层感知机。
51、所述解码器组的每一个解码器都由一个时空自注意力层和一个交叉自注意力层组成,所述时空自注意力层由空间多头自注意力层和时间多头自注意力层组成;
52、以第i个解码器为例,i={1,…,m},所述空间多头自注意力层用于提取输入序列的空间关系,其具体处理流程为:
53、步骤4-2-1,将输入序列d(i),分别映射为三个不同矩阵q、k、v,具体为:
54、
55、
56、
57、其中,t={1,…,tout},n={1,…,n},a={1,…,a}是多头自注意力头的序号;
58、步骤4-2-2,将输入到自注意力层计算点积注意力,具体为:
59、
60、
61、
62、其中,α为注意力系数,m为注意力向量;
63、步骤4-2-3,将通过多层感知机,得到空间多头自注意力层的输出具体为:
64、
65、所述时间多头自注意力层用于提取输入序列的时间关系,其具体处理流程为:
66、步骤4-3-1,将序列分别映射为三个不同矩阵q、k、v,具体为:
67、
68、
69、
70、步骤4-3-2,将输入到自注意力层计算点积注意力,具体为:
71、
72、
73、
74、步骤4-3-3,将s′(i)通过多层感知机,得到时间多头自注意力层的输出s(i),具体为:
75、s(i)=mlp(ln(s′(i)))+s′(i)
76、所述交叉自注意力层的输入为fen,s(i),具体流程可表示为:
77、
78、r′(i)=ca(fen,fq)+s(i)
79、r(i)=mlp(r′(i))+r′(i)
80、其中,ca(*,*)是交叉自注意力函数,r(i)是第i个解码器的输出。
81、进一步,所述步骤5,将步骤4得到的特定的管道特征ftub通过动作分类模块和回归模块,计算每个管道的位置和属于每个动作的概率,具体为:
82、所述动作分类模块由时间池化层、自注意力层、交叉注意力层和前馈神经网络组成,其具体流程为:
83、步骤5-1,将全局时空特征fb通过自注意力层,即sa(fb);
84、步骤5-2,对ftub进行时间池化操作,即poolt(ftub);
85、步骤5-3,将sa(fb)和poolt(ftub)通过交叉自注意力层,得到中间特征具体为:
86、fc=ca(sa(fb),poolt(ftub))+poolt(ftub)
87、步骤5-4,将fc通过前馈神经网络,得到其中yclass表示在l个可能的动作标签上的得分。
88、所述回归模块由两个前馈神经网络组成,输入为特定的管道特征ftub,用于输出人员边界的坐标并排除非动作边界对动作分类的影响,具体处理流程为:
89、
90、
91、其中,n是管道向量的数量,tout是管道的时间维度,ycoor表示人员边界的坐标,yaction表示边界中是否有动作发生。
92、进一步,所述步骤6,将步骤2中得到的正常光下视频数据分成训练样本和测试样本,使用设计的损失函数来训练所属应用在低照度环境下的动作识别模型,具体为:
93、所述的训练样本和测试样本划分方式为:将步骤2中得到的正常光下视频数据进行混洗,并按比例适当划分为训练样本和测试样本;
94、所述损失函数包括动作分类任务的损失函数和回归任务的损失函数,表示为:
95、
96、其中y是输出预测,y是真实数据;
97、所述动作分类损失函数是交叉熵损失函数,表示为:
98、
99、其中g是动作类别的总数,g={1,…,g};
100、所述损失函数是为了移除管道中非动作边界对动作分类的影响,采用二值交叉熵损失函数;
101、所述回归任务的损失函数由l1损失函数和iou损失函数组成,表示为:
102、
103、其中n={1,…,n},为交并比损失函数,它表示的重合程度。
104、有益效果,由于采用了上述方案,包含五个模块分别是:风格转换模块、时空特征提取模块、目标检测模块、动作分类模块和回归模块。在风格转换模块中,使用改进的cyclegan网络对视频数据进行风格转换,把煤矿井下低照度的视频转换到正常光下,丰富了视频包含的信息,使得后续动作分类任务和目标检测任务更加精准且不需要成对的数据进行训练,降低了数据获取的难度;在目标检测模块中,将视频的目标检测转换为一组集合预测的问题,不需要任何的先验知识和后续处理,实现端到端的检测视频中的人员。
- 还没有人留言评论。精彩留言会获得点赞!