特征处理方法、装置、设备及计算机存储介质与流程
本技术属于大数据,尤其涉及一种特征处理方法、装置、设备及计算机存储介质。
背景技术:
1、在信息时代的背景下,互联网快速发展,由此带来的信息激增,信息超载问题成为人们亟待解决的问题。企业如何有效地从海量的信息中挖掘出真正的有用的信息、充分利用信息产生的价值、快速定位出用户的兴趣偏好、提高用户体验,是他们提高竞争力的有效途径和产生更高收益的有效方法。与其对应,消费者如何能快速地在如此庞大的信息库中找到自己感兴趣的目标物,是他们提出的个性化的需求,同时也是身处信息时代的需求。
2、基于上述背景,如何对用户行为或其意向进行准确预测,对于提升各大企业的竞争力具有重大意义。实际上,关于预测用户行为或其意向方面,其本质属于一个二分类问题,基于此,通过用户的相关特征来预测用户行为或其意向是目前较为普遍的一种预测手段。
3、目前现存多种迭代预测算法,最基础的是逻辑回归算法,但由于其对于隐藏的特征组合不够重视,因此预测效果并不算好。而后续衍生出lr+人工组合特征、lr+gbdt以及lr+二项式多项式模型等,虽然将隐藏的特征组合考虑进来,能够实现更为全面的分析预测。然而,由于此类方法在使用类别型特征前往往是直接对特征进行独热编码等预处理,再将独热编码后的特征输入至模型后进行特征交叉衍生。这样一来,其基于上述模型衍生的组合特征具有较高的稀疏性,并且,此类方法特征交叉容易产生维度灾难,最终导致模型预测效果较差。
技术实现思路
1、本技术实施例提供一种特征处理方法、装置、设备及计算机存储介质,能够减少高维稀疏特征的出现。
2、第一方面,本技术实施例提供一种特征处理方法,该特征处理方法包括:
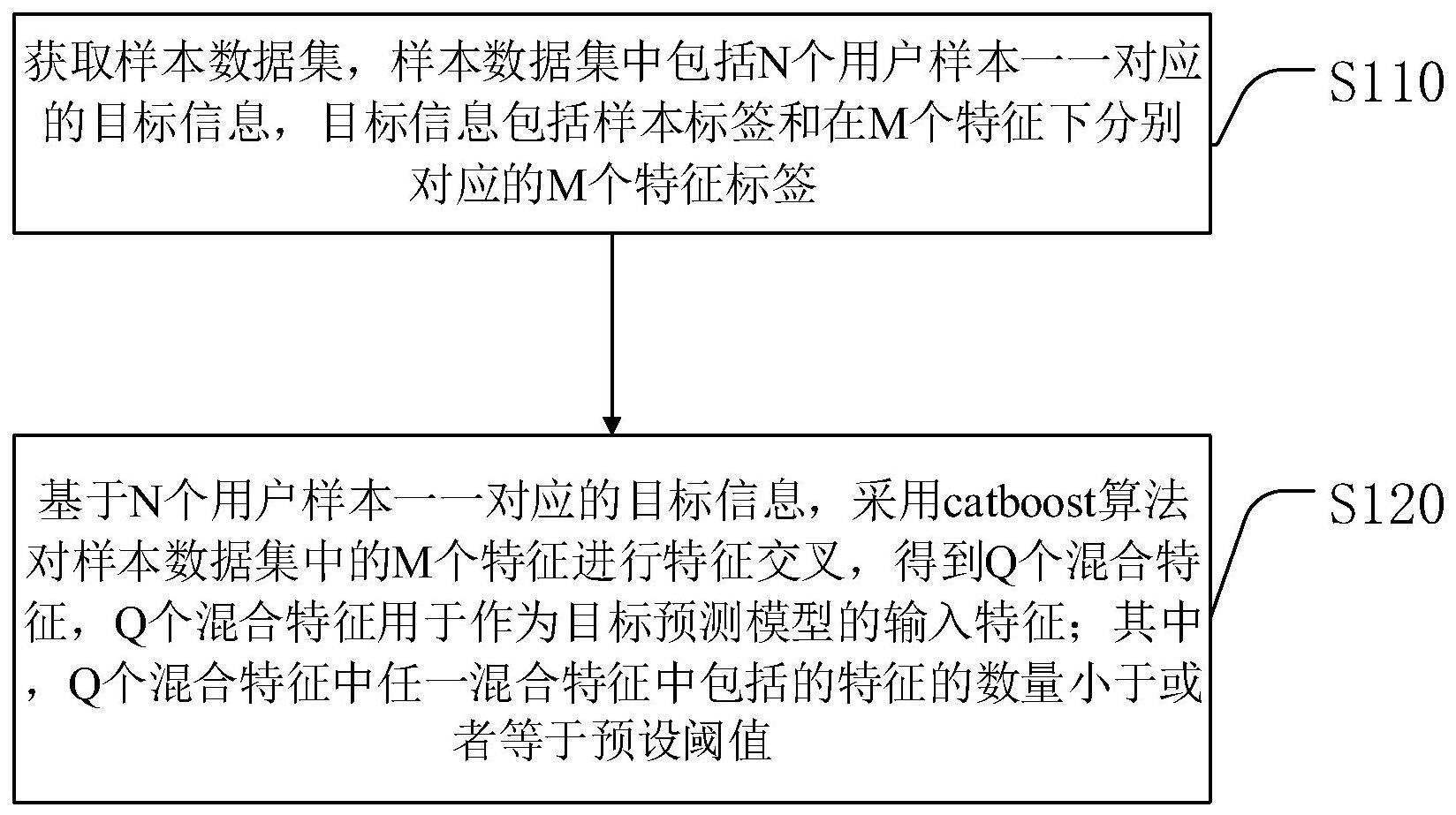
3、获取样本数据集,样本数据集中包括n个用户样本一一对应的目标信息,目标信息包括样本标签和在m个特征下分别对应的m个特征标签;
4、基于n个用户样本一一对应的目标信息,采用catboost算法对样本数据集中的m个特征进行特征交叉,得到q个混合特征,q个混合特征用于作为目标预测模型的输入特征;
5、其中,q个混合特征中任一混合特征中包括的特征的数量小于或者等于预设阈值。
6、在一些可能的实施方式中,采用catboost算法对样本数据集中的m个特征进行特征交叉,得到至少一个衍生多变量特征,包括:
7、基于n个用户样本一一对应的目标信息,训练得到特征衍生模型,特征衍生模型基于catboost算法构建得到;
8、通过特征衍生模型,预测得到n个用户样本中各用户样本的m个特征标签在多棵决策树中的叶节点,多棵决策树基于catboost算法分割得到;
9、基于n个用户样本中各用户样本的m个特征标签在多棵决策树中的叶节点,确定q个混合特征。
10、在一些可能的实施方式中,在得到q个混合特征之后,该特征处理方法还包括:
11、基于q个混合特征和m个特征,构建ffm模型;
12、对目标预测模型进行训练,训练好的目标预测模型用于对待测样本的样本标签进行预测;
13、其中,目标预测模型基于ffm模型确定得到。
14、在一些可能的实施方式中,对ffm模型进行训练之前,该特征处理方法还包括:
15、基于k个异常样本特征,构建多元回归特征模型,k为正整数;
16、将多元回归特征模型与ffm模型进行融合,得到目标预测模型。
17、在一些可能的实施方式中,在对目标预测模型进行训练之前,该特征处理方法还包括:
18、将注意力机制引入ffm模型中,得到更新后的ffm模型;
19、将更新后的ffm模型确定为目标预测模型。
20、在一些可能的实施方式中,ffm模型中包括i个二阶交叉特征,i个二阶交叉特征中各二阶交叉特征基于q个混合特征和m个特征中的至少两项确定得到,i为正整数;在将注意力机制引入ffm模型中,得到更新后的ffm模型之前,该特征处理方法还包括:
21、从样本数据集中随机抽取目标数据集;目标数据集为样本数据集的子集;
22、基于目标数据集,确定与i个二阶交叉特征分别对应的特征权重;
23、基于与i个二阶交叉特征分别对应的特征权重中的至少一项,更新ffm模型中的二阶交叉特征的特征权重,以得到更新后的ffm模型。
24、在一些可能的实施方式中,m个特征中包括在t个数值型特征和s个分类型特征,t、s为小于或者等于m的非负整数;
25、在获取样本数据集之后,该特征处理方法还包括:
26、对s个分类型特征分别进行独热编码,得到s个分类型特征分别对应的特征编码结果;
27、采用有监督分箱算法对t个数值型特征分别进行分箱处理,得到t个数值型特征中各数值型特征对应的目标分箱结果;
28、基于q个混合特征和m个特征,构建ffm模型,包括:
29、基于q个混合特征、s个分类型特征分别对应的特征编码结果,以及t个数值型特征中各数值型特征对应的目标分箱结果,构建ffm模型。
30、在一些可能的实施方式中,第二类别特征为t个数值型特征中的任意一项;
31、采用有监督分箱算法对t个数值型特征分别进行分箱处理,得到t个数值型特征中各数值型特征对应的目标分箱结果,包括:
32、采用y种有监督分箱算法对第二类别特征进行分箱处理,得到第二类别特征的y种分箱结果,y种分箱结果与y种有监督分箱算法一一对应,y为正整数;
33、基于q种分箱结果的证据权重woe和信息价值iv,从y种分箱结果中确定第二类别特征的目标分箱结果。
34、第二方面,本技术实施例提供了一种特征处理装置,该特征处理装置包括:
35、第一获取模块,用于获取样本数据集,样本数据集中包括n个用户样本一一对应的目标信息,目标信息包括样本标签和在m个特征下分别对应的m个特征标签;
36、第一得到模块,用于基于n个用户样本一一对应的目标信息,采用catboost算法对样本数据集中的m个特征进行特征交叉,得到q个混合特征,q个混合特征用于作为目标预测模型的输入特征;
37、其中,q个混合特征中任一混合特征中包括的特征的数量小于或者等于预设阈值。
38、第三方面,本技术实施例提供了一种特征处理设备,该特征处理设备包括:
39、处理器以及存储有计算机程序指令的存储器;
40、所述处理器执行所述计算机程序指令时实现如上述本技术实施例中任意一项提供的特征处理方法。
41、第四方面,本技术实施例提供了一种计算机存储介质,该计算机可读存储介质上存储有计算机程序指令,所述计算机程序指令被处理器执行时实现如上述本技术实施例中任意一项提供的特征处理方法。
42、第五方面,本技术实施例提供了一种计算机程序产品,计算机程序产品中的指令由电子设备的处理器执行时,使得所述电子设备执行如上述本技术实施例中任意一项提供的特征处理方法。
43、本技术实施例的特征处理方法、装置、设备及计算机存储介质,通过对所获取的样本数据集采用catboost算法进行训练预测,从而能够自动化地实现对样本数据集中涉及到的多个特征的特征交叉处理,得到受到交叉深度限制的多个混合特征,以用于后续用户行为或意向的预测模型的训练及预测中。本技术实施例提供的一种特征处理方法、装置、设备及计算机存储介质,使用catboost技术,进行能直接处理样本中各个特征的特征衍生,并在catboost特征衍生时控制多维的特征交叉的最大特征数量,从而有效避免了高维稀疏特征的出现。
- 还没有人留言评论。精彩留言会获得点赞!