人在回路语义级视觉重构方法、系统和设备
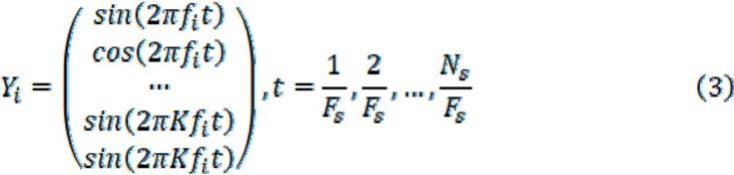
1.本发明涉及视觉重构技术领域,具体涉及一种人在回路语义级视觉重构方法、系统和设备。
背景技术:
2.视觉重构是指通过脑机接口采集大脑活动数据并生成视觉图像。直观而言,视觉重构旨在重现人眼所看到的文字、形状、物体、场景等画面。视觉重构技术可以在刑侦、军事等领域产生非常大的作用。例如在刑侦案件中,如果目击者能够将脑海中的视觉记忆通过同样的方式解码,那么其效果将会远远超出文字描述,真实性也会大大提升。
3.但是,现有技术中基于头皮脑电数据的视觉重构难度大。大多数视觉重构研究利用功能磁共振成像技术测量大脑血氧活动,通过磁共振成像数据进行视觉生成。相较于脑电数据,磁共振成像数据具有更好的时空分辨率,能够更好地反映大脑不同区域的工作情况,更易于区分出不同刺激的类别信息。但是,功能磁共振成像技术的缺点是设备成本高,设备使用复杂,测量时间长,市场化大规模使用难以实现。而头皮脑电数据可以通过非侵入式脑电帽进行测量,相对于功能磁共振成像设备而言具有更高的便携性、经济性和易操作性。然而由于大脑的容积传导效应等影响,头皮脑电数据信噪比低,难以获取更抽象的视觉刺激的语义信息,相关视觉重构研究都难以达到磁共振成像数据的效果,这也让脑电难以在视觉重构研究领域得到更大规模的应用。
4.因此,现有技术中存在脑电数据信噪比低、难以获取更抽象的视觉刺激的语义信息,脑电数据视觉重构难以达到磁共振成像数据效果的技术问题。
技术实现要素:
5.有鉴于此,本发明的目的在于提供一种人在回路语义级视觉重构方法、系统和设备,以克服目前脑电数据信噪比低、难以获取更抽象的视觉刺激的语义信息,脑电数据视觉重构难以达到磁共振成像数据效果的问题。
6.为实现以上目的,本发明采用如下技术方案:
7.一方面,一种人在回路语义级视觉重构方法,包括:
8.在生成对抗网络的隐空间生成高维随机变量,得到目标图像;
9.根据所述隐空间的高维随机变量生成优化图像;其中,所述优化图像为多个;
10.将所述目标图像和所述优化图像进行不同频率的闪烁展示,通过ssvep实验,获取对应图像的脑电活动,以实现图像像素空间到脑电活动空间的映射;
11.通过cca算法对所述脑电活动进行解码,选择最接近目标图像的一幅图像作为当前最优图像;
12.判断所述当前最优图像是否满足重构效果要求;
13.当所述当前最优图像不满足重构效果要求时,基于所述当前最优图像对应的隐空间随机变量,进行随机游走,产生新的隐空间的高维随机变量,更新所述高维随机变量,重
新根据更新后的所述隐空间的高维随机变量生成优化图像;
14.当所述当前最优图像满足重构效果要求,输出最优重构图像。
15.可选的,所述根据所述隐空间的高维随机变量生成优化图像,包括:
16.随机生成多个隐向量,经过标准化后与所述目标图像相加实现随机游走;随机游走后的多个隐向量通过生成网络,得到对应的优化图像;其中,所述优化图像中的图像个数与所述隐向量的个数相同。
17.可选的,所述将所述目标图像和所述优化图像进行不同频率的闪烁展示,通过ssvep实验,获取对应图像的脑电活动,包括:
18.在预设时长内展示所述目标图像,将所述优化图像中的图像分别按照不同的频率进行展示,以刺激被测者,使得被测者对刺激图像进行感知与决策,获取被测者的脑电活动。
19.可选的,所述判断所述当前最优图像是否满足重构要求,包括:判断所述当前最优图像是否收敛。
20.可选的,所述生成对抗网络采用对抗隐空间自编码器的结构;其中,自编码器为基于stylegan的自编码器。
21.又一方面,一种人在回路语义级视觉重构系统,包括:
22.图像生成模块,用于根据生成对抗网络的隐空间中的高维变量生成目标图像以及优化图像;其中,所述优化图像为多个;
23.ssvep人在回路感知模块,用于将所述目标图像和所述优化图像进行不同频率的闪烁展示,通过ssvep实验,获取对应图像的脑电活动,以实现图像像素空间到脑电活动空间的映射;
24.脑电解码模块,用于通过cca算法对所述脑电活动进行解码,选择最接近目标图像的一幅图像作为当前最优图像;
25.语义隐空间优化迭代模块,用于当所述当前最优图像不满足重构效果要求时,基于所述当前最优图像对应的隐空间随机变量,进行随机游走,产生新的隐空间的高维随机变量,更新所述高维随机变量,通过图像生成模块重新根据更新后的所述隐空间的高维随机变量生成优化图像;当所述当前最优图像满足重构效果要求,输出最优重构图像。
26.可选的,图像生成模块,具体用于随机生成多个隐向量,经过标准化后与所述目标图像相加实现随机游走;随机游走后的多个隐向量通过生成网络,得到对应的优化图像;其中,所述优化图像中的图像个数与所述隐向量的个数相同。
27.可选的,所述ssvep人在回路感知模块,具体用于在预设时长内展示所述目标图像,将所述优化图像中的图像分别按照不同的频率进行展示,以刺激被测者,使得被测者对刺激图像进行感知与决策,获取被测者的脑电活动。
28.又一方面,一种人在回路语义级视觉重构设备,包括处理器和存储器,所述处理器与存储器相连:
29.其中,所述处理器,用于调用并执行所述存储器中存储的程序;
30.所述存储器,用于存储所述程序,所述程序至少用于执行上述任一项所述的人在回路语义级视觉重构方法。
31.本发明提供的技术方案至少具有如下有益效果:
32.在生成对抗网络的隐空间生成高维随机变量,得到目标图像;根据隐空间的高维随机变量生成优化图像;其中,优化图像为多个;将目标图像和优化图像进行不同频率的闪烁展示,通过ssvep实验,获取对应图像的脑电活动,以实现图像像素空间到脑电活动空间的映射;通过cca算法对脑电活动进行解码,选择最接近目标图像的一幅图像作为当前最优图像;判断当前最优图像是否满足重构效果要求;当当前最优图像不满足重构效果要求时,基于当前最优图像对应的隐空间随机变量,进行随机游走,产生新的隐空间的高维随机变量,更新高维随机变量,重新根据更新后的隐空间的高维随机变量生成优化图像;当当前最优图像满足重构效果要求,输出最优重构图像。因此,本发明从一组随机生成的图像开始,使用cca从脑电活动中解码得到最接近目标图像的图像,应用游走优化方法实现在语义隐空间进行图像搜索,从而迭代优化完成图像重构。本发明中突破脑电数据信噪比低的困难,利用特殊的人在回路在线实验方式,通过稳态视觉诱发电位指导图像生成,达到了磁共振成像数据的重构效果,让脑电在视觉重构研究领域得到了突破。
附图说明
33.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
34.图1为本发明实施例提供的一种人在回路语义级视觉重构系统的结构示意图;
35.图2为本发明实施例提供的一种stylealae生成对抗网络模型的结构示意图;
36.图3为本发明实施例提供的一种人在回路视觉重构范式的结构示意图;
37.图4为本发明实施例提供的一种视觉重构实验结果示意图;
38.图5为本发明实施例提供的又一种视觉重构实验结果示意图;
39.图6为本发明实施例提供的一种人在回路语义级视觉重构方法的流程示意图;
40.图7为本发明实施例提供的一种人在回路语义级视觉重构设备的结构示意图。
具体实施方式
41.为使本发明的目的、技术方案和优点更加清楚,下面将对本发明的技术方案进行详细的描述。显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所得到的所有其它实施方式,都属于本发明所保护的范围。
42.视觉重构是指通过脑机接口采集大脑活动数据并生成视觉图像。直观而言,视觉重构旨在重现人眼所看到的文字、形状、物体、场景等画面。视觉重构技术可以在刑侦、军事等领域产生非常大的作用。例如在刑侦案件中,如果目击者能够将脑海中的视觉记忆通过同样的方式解码,那么其效果将会远远超出文字描述,真实性也会大大提升。
43.大脑活动通常指大脑皮层的各类生理活动,当视觉信息进入大脑后会刺激中枢系统,所带来的神经元活动会产生大脑皮层电活动、血氧变化等生理现象,可以通过脑机接口对此类生理信号进行采集。采集到的大脑活动数据蕴含了视觉刺激经过人脑系统处理后的各类特征信息,例如语义信息、类别信息、刺激时间、刺激强度等。视觉重构工作希望对大脑
活动数据进行解码,得到视觉刺激的相关特征,并通过特征重现原始的视觉刺激。通过这种方式,可以对视觉图片、视频、场景信息进行更加高效的分析,突破查询视觉信息时因表达方式欠缺而产生的约束。最早图片搜索只能用文字进行描述,后来在深度学习的发展下,人们可以通过图像识别的方法在互联网中进行图片检索。但是,这种方法依旧需要一张完整清晰的图片。如果视觉重构技术得到发展,我们或许可以直接对双眼所见甚至是脑中所想的某样东西进行重现,使得计算机可以直接对人类大脑中的视觉信号进行识别、分析甚至理解,自动开启检索系统进行查询,并立即反馈结果,这将大大提升人-机语义级别的交互水平。
44.但是,现有的基于大脑活动视觉重构相关研究大多存在以下局限性:第一,如背景技术记载现有技术中基于头皮脑电数据的视觉重构难度大。第二,可生成的图像类别单一,无法在连续的语义空间内进行图像生成。第三,生成图像往往质量差,缺少语义细节,难以生成人脸等包含丰富高维细节特征的图像。
45.基于此,本发明实施例提供了一种人在回路语义级视觉重构方法、系统和设备。
46.图1为本发明实施例提供的一种人在回路语义级视觉重构系统的结构示意图,参阅图1,本发明实施例提供的系统,可以包括以下结构:
47.图像生成模块11,用于根据生成对抗网络的隐空间中的高维变量生成目标图像以及优化图像。
48.例如,在生成对抗网络的隐空间生成高维随机变量,将高维随机变量作为高维变量,根据高维变量生成目标图像;根据隐空间的高维随机变量生成优化图像;其中,优化图像为多个。
49.在一些实施例中,图像生成模块中根据隐空间的高维随机变量生成一组图像,包括:
50.随机生成多个隐向量,经过标准化后与目标图像相加实现随机游走;随机游走后的多个隐向量通过生成网络,得到对应的优化图像;其中,优化图像中的图像个数与隐向量的个数相同。其中,生成网络可以为gan网络。
51.例如,可以在对抗网络的生成器隐空间内随机生成一个512维的隐变量作为初始样本;可以随机生成9个512维隐向量,经过标准化后与初始样本相加实现随机游走。通过对抗网络生成器生成目标图像。随机游走后的9个隐向量样本通过gan网络,将会生成9张图片,组成图片九宫格,即,优化图像。
52.ssvep人在回路感知模块12,用于将目标图像和优化图像进行不同频率的闪烁展示,通过ssvep实验,获取对应图像的脑电活动,以实现图像像素空间到脑电活动空间的映射。
53.在一些实施例中,ssvep人在回路感知模块中将目标图像和优化图像进行不同频率的闪烁展示,通过ssvep实验,获取对应图像的脑电活动,包括:
54.在预设时长内展示目标图像,将优化图像中的图像分别按照不同的频率进行展示,以刺激被测者,使得被测者对刺激图像进行感知与决策,获取被测者的脑电活动。
55.例如,可以展示目标图像5s,此时要求被试对图片上的人脸进行记忆。随机游走后的9个隐向量样本通过gan网络,将会生成9张图片,组成图片九宫格。每场图片将会分别以不同的频率进行刺激,刺激频率分别为8~12hz,频率间隔0.5hz,相邻频率之间相位差0.5
π。实验中,受试者被告知注视与目标图片接近的人脸。
56.脑电解码模块13,用于通过cca算法对脑电活动进行解码,选择最接近目标图像的一幅图像作为当前最优图像。
57.语义隐空间优化迭代模块14,用于当前最优图像不满足重构效果要求时,基于当前最优图像对应的隐空间随机变量,进行随机游走,产生新的隐空间的高维随机变量,更新高维随机变量,重新根据更新后的隐空间的高维随机变量生成优化图像。
58.其中,ssvep人在回路感知模块,实现从多幅备选图像像素空间到脑电活动空间的映射。稳态视觉诱发电位(ssvep)是一种在脑电实验中经常使用的范式。当人脑受到视觉刺激时,神经元的活动也会带来大脑的电位变化。当外界刺激为一恒定频率的周期刺激时,人脑也会产生相应频率或谐波频率的周期性变化。稳态视觉诱发电位就是通过恒定频率的视觉刺激产生的周期性脑电信号。ssvep被广泛用于判断大脑思维活动,在脑电信号中,ssvep信号会在在功率谱中刺激频率或谐波上出现谱峰。通过分析检测谱峰出现的频率位置以及信号强度,即能检测到受试者视觉注视的刺激源以及所受到的刺激的强度,从而能识别受试者的意图以及视觉信息。
59.脑电解码模块,实现从视觉刺激下的脑电活动到图像语义隐空间的映射。
60.典型相关分析(canonical correlation analysis,cca)利用综合变量对之间的相关关系来反映两组指标之间的整体相关性的多元统计分析方法。它的基本原理是:为了从总体上把握两组指标之间的相关关系,分别在两组变量中提取有代表性的两个综合变量,利用这两个综合变量之间的相关关系来反映两组指标之间的整体相关性。简单相关系数描述两组变量的相关关系的缺点:只是孤立考虑单个变量间的相关,没有考虑变量组内部各变量间的相关。两组间有许多简单相关系数,使问题显得复杂,难以从整体描述。典型相关是简单相关、多重相关的推广。典型相关是研究两组变量之间相关性的一种统计分析方法。典型相关分析在脑电领域主要应用ssvep信号的检测与分类。
61.语义隐空间优化迭代模块,实现基于当前选择结果对备选图像在语义空间进行迭代更新,生成新的语义种群。
62.随机游走算法是一种解决全局优化问题的优化算法。随机游走用来描述数学空间中通过随机过程产生的路径。随机游走是模拟布朗运动而建立的数学模型,其特点是随机游走的粒子会做无规则随机运动,这种运动不受粒子过去状态的影响。随机游走算法通常给定粒子运动的步长,每一次优化随机生成一个随机向量,粒子沿该向量方向运动相应的步长,运动后若所优化函数值降低,则找到了一个更优的点,否则粒子保持不动。通过这种方式优化粒子位置,可以实现任意复杂函数的全局优化。随机游走算法也可以在生成随机向量时生成多个随机向量,分别沿各个向量运动一个步长的距离,选择运动后被优化函数值最小的点作为随机运动的方向,并与运动前进行比较决定是否进行运动。随机游走算法与相关模型被广泛应用于链路预测、推荐算法、计算机视觉等任务之中。
63.图像生成模块,实现从语义空间向图像像素空间的映射。
64.生成对抗网络是一种为解决生成建模问题而设计的人工智能算法。生成模型的目标是研究一组训练示例,并学习其概率分布,进而从概率分布中生成更多的样本。gan网络相较于其他生成模型而言,可以产生更加逼真的高分辨率高质量图像。gan是一种基于博弈论的生成模型。在生成真实的数据,特别是图像方面取得了巨大的实际成功。越来越多的研
究希望能够将其投入到各个领域的应用之中。但是生成网络的图像合成过程仍然近似黑箱,为了能够更好的控制生成效果,研究者希望能够对隐空间的性质以及生成器的原理进行更加深入的探索。
65.本技术中,可以采用ssvep脑电范式,为被试同时提供多组图片刺激,每组图片刺激由一张共同的刺激图像与不同的优化目标组成,每组两张图像进行不同频率的闪烁。在实验中,被试将会提供感知与决策的作用。其中感知作用反映刺激的图像信息,决策作用反映最优组别。本技术中可以设计基于cca的脑电解码模型对以上两种信息分别进行解码,并用解码结果指导优化模型。优化模型参考随机游走原理,依据解码模型得到的感知与决策信息对随机生成的初始结果进行随机游走优化,优化的数学空间为生成对抗网络的隐空间。
66.在一个具体的实现过程中,可以采用本技术的人在回路语义级视觉重构系统进行人在回路语义级视觉重构。可以首先在隐空间生成一组高维随机变量;根据隐空间随机变量生成一组图像;在ssvep人在回路感知模块中,通过ssvep实验,实现从多幅备选图像像素空间到脑电活动空间的映射;进入脑电解码模块,通过cca解码脑电活动,选择最接近目标图像的一幅作为当前代最优图像;判断当前代最优图像是否收敛,或者满足重构效果要求;若满足要求退出迭代,输出最优图像,否则,进入语义隐空间优化迭代模块;在语义隐空间优化迭代模块中,基于图像对应的隐空间随机变量,进行随机游走,产生新的隐空间高维随机变量;并返回根据隐空间随机变量生成一组图像。
67.在一些实施例中,判断当前最优图像是否满足重构要求,包括:判断当前最优图像是否收敛。
68.在一些实施例中,生成对抗网络采用对抗隐空间自编码器的结构;其中,自编码器为基于stylegan的自编码器。
69.本技术中,对脑电解码模块进行说明:脑电解码模块可以为脑电解码模型,通过脑电解码模型对脑电信息进行解码:
70.被试对刺激图像进行感知与决策过程可以表示为式(1),在该模型中,x∈rm表示图片空间:
[0071][0072]
其中是采集到的脑电信号数据空间,c为通道数,t为窗口长度,在本实验中c=8,t=200。
[0073]
cca模型表示为式(2),其中r表示该样本对应频段的能量,该模型将脑电映射为检测到的各频段对应能量分布。
[0074][0075]
在解码模型中,cca作用于脑电信号s与参考信号y。参考信号是ssvep实验中的视觉刺激信号,对于实验中数目为n的刺激而言,会有n个参考信号,其中第i个参考信号如式(3)所示。
[0076][0077]
在式(3)中,fi表示刺激频率,k表示参考信号中的谐波数,ns表示采样点数量。s与yi的线性组合表示如式(4)和式(5),其中ws和wy是权重矩阵。s对应于第i组参考信号的相关系数如式(6)所示。
[0078]
s=s
tws
ꢀꢀꢀꢀꢀꢀ
(4)
[0079]
y=y
t
wyꢀꢀꢀꢀ
(5)
[0080][0081]
本技术中,将刺激信号与脑电信号cca相关系数作为不同频段的能量分布依据,其中包含了被试所收到的视觉刺激后产生的感知信息与决策信息。
[0082]
图像生成模块,可以为图像生成模型:
[0083]
本技术中采用的生成对抗网络称之为对抗性潜式自动编码器(alae,adversarial latent autoencoders),该网络采用对抗隐空间自编码器的结构。自动编码器是一种无监督学习模型,旨在通过同时学习编码器与生成器的映射来生成图像并表现其属性。本技术中,可以采用基于stylegan的自动编码器,称之为stylealae。stylealae不仅可以生成与stylegan质量相当的人脸图像,而且在相同的分辨率下,还可以基于真实图像生成人脸重构和操作。stylealae是第一个能够与仅生成器类型的体系结构进行比较并超越其功能的自动编码器,图2为本发明实施例提供的一种stylealae生成对抗网络模型的结构示意图,参阅图2,stylealae生成对抗网络模型,可以包括:不同的3*3卷积层,具体结构参阅图2,本技术中不做赘述。
[0084]
在本技术中,可以将生成对抗网络自编码器表示为式(7)与式(8):
[0085][0086][0087]
其中e表示生成对抗网络的编码器,g表示生成对抗网络的生成器,表示是图片空间。表示生成模型的隐空间,在本技术中n=512。
[0088]
优化模型:
[0089]
首先在隐空间中随机生成实验样本w0,作为第0代最优样本。
[0090]
之后采用迭代更新的方法进行优化。对于第t代实验最优样本w
t
,采用随机游走优化算法生成n个新样本w
t,1
,w
t,2
,...,w
t,n
,生成过程如式(9)所示,在本技术中n为9。在式(9)中ui为经过标准化的随机向量,λ为随机游走的步长。
[0091]wt,i
=w
t
+λu
t,i
ꢀꢀꢀ
(9)
[0092]
将实验全部样本w
t,1
,w
t,2
,...,w
t,n
通过生成模型g生成图片样本x
t,1
,x
t,2
,...,x
t,n
。经过在线ssvep实验后,采集到脑电信号片段s
t,1
,s
t,2
,...,s
t,n
,通过脑电解码模型将
会得到频段能量分布r
t,1
,r
t,2
,...,r
t,n
,并通过式(10)选择当前最优目标样本为w
t,k
。
[0093][0094]
在t轮次中如果没有检测到最优目标,则样本不动,即更新方式如式(11):
[0095]wt+1
=w
t
ꢀꢀꢀꢀ
(11)如果检测到稳态电位,则样本的更新方式如式(12):
[0096]wt+1
=(1-ρ)
×wt
+ρ
×wt,k
ꢀꢀꢀꢀ
(12)
[0097][0098]
式(12)表示当前代最优样本向着新的最优样本的方向前进,式(13)计算前进的距离占两样本之间距离的比例,其值通过频段能量强度确定,取值范围在0.2与0.5之间。通过这种方式经过多个轮次实验直到收敛,此时最优样本隐变量即可通过生成模型g生成最为接近目标图像的结果。
[0099]
基于此,本技术还提供一具体实验实施例,以对本技术的技术方案和技术效果进行说明:
[0100]
数据集:人脸数据集ffhq(flickr faces high quality)由英伟达于2019年开源。ffhq是一个高质量的人脸数据集,包含1024
×
1024分辨率的70000张png格式高清人脸图像,在年龄、种族和图像背景上丰富多样且差异明显,在人脸属性上也拥有非常多的变化,拥有不同的年龄、性别、种族、肤色、表情、脸型、发型、人脸姿态等,囊盖普通眼镜、太阳镜、帽子、发饰及围巾等多种人脸周边配件,因此该数据集也是可以用于开发一些人脸属性分类或者人脸语义分割模型的。
[0101]
本技术在ffhq数据集上训练stylealae模型,使其具备从任意人脸图像到隐空间向量,以及隐空间任意向量到人脸图像映射的能力。
[0102]
实验设计:本技术提供的实验搭建支持离线和在线的ssvep-bci系统。该系统使用16英寸ips显示器(分辨率1920
×
1080,刷新率144hz)展示刺激图片(rgb,3
×
200
×
200)。图像刺激程序采用基于matlab的psychtoolbox工具箱实现。
[0103]
实验采用ssvep脑电范式,对每个被试(被测者)分别进行10组在线实验。在每组实验开始时,在对抗网络的生成器隐空间中随机生成一个512维的隐变量作为目标样本,随机生成一个512维的隐变量作为初始样本。同时随机生成9个512位隐向量,经过标准化后与初始样本相加实现随机游走。通过对抗网络生成器生成目标样本图片,即目标图像,展示目标图像5s,此时要求被试对图片上的人脸进行记忆。随机游走后的9个隐向量样本通过gan网络,将会生成9张图片,组成图片九宫格。每场图片将会分别以不同的频率进行刺激,刺激频率分别为8~12hz,频率间隔0.5hz,相邻频率之间相位差0.5π。实验中,受试者被告知注视与目标图片接近的人脸。经过5s的刺激时间,通过解码模型对图片进行分类,通过分类结果根据随机游走优化算法对9个样本进行更新。通过20个轮次的训练后,最后一轮实验所选取的最优样本即为视觉重构的结果。每两组实验之间被试将会有5分钟的时间进行休息。
[0104]
数据采集:图3为本发明实施例提供的一种人在回路视觉重构范式的结构示意图。由于视觉刺激产生的ssvep信号大多集中在顶叶和枕叶,实验选择的通道为po6、o1、oz、o2、
po5、po3、poz、po4,如图3所示,参考电极ref位于头顶cz电极之侧。实验使用32导湿电极脑电帽,电极是由ag/agcl涂层聚合物构成,可以提高实验者的舒适程度并且能够采集稳定的、高质量的研究级脑电信号。脑电帽通过置于头皮表面的ag/agcl涂层聚合物电极进行脑电信号的采集与传送。本技术中,实验采用32导脑电信号采集放大器将脑电帽采集到的脑电信号进行放大并转换为数字信号,采样频率为1000hz。计算机模块可以直接使用该放大后的数字信号进行后续的实验。在在线实验中,通过在线数据分析程序实时记录脑电图数据和触发信号并进行分析。在matlab环境下开发了在线数据分析程序。
[0105]
结果:研究对3位被试分别进行了10次实验。图4为本发明实施例提供的一种视觉重构实验结果示意图,参阅图4,本技术中,随机展示4次实验里的重构过程与重构结果,这4次实验对象为不同的实验被试。参阅图4,其中第1列图像为原始刺激图像,即目标图像,第2列图像为从隐空间中随机生成的图像,此时迭代次数为零。之后的3至11列分别为迭代2至18次的重构结果。
[0106]
值得说明的是,本技术中,提出的指标为隐空间欧氏距离。对于目标样本隐向量w
target
和重构结果w
best
,通过以下方式计算其在隐空间中的欧式距离:
[0107][0108]
两张人脸图片在隐空间中的距离可以反映人脸图像的相似度,当该指标越小时,隐空间中两张图片越接近,人脸重构的相似度也越高,视觉重构结果越好。
[0109]
图5为本发明实施例提供的又一种视觉重构实验结果示意图,参阅图5,
[0110]
展示以上所选择的4次实验中样本在隐空间中的运动趋势。其中横坐标表示迭代次数,纵坐标表示隐空间欧式距离,每个折线图都反映了当前实验中的收敛情况。其中,图id:01为第一次实验中样本在隐空间中的运动趋势;图id:02为第二次实验中样本在隐空间中的运动趋势;图id:03为第三次实验中样本在隐空间中的运动趋势;图id:04为第四次实验中样本在隐空间中的运动趋势。
[0111]
本发明采用以上技术方案,能够达到的有益效果包括:
[0112]
第一,本发明实现了基于脑电数据实现视觉重构。本技术中突破脑电数据信噪比低的困难,利用特殊的人在回路在线实验方式,通过稳态视觉诱发电位指导图像生成,达到了磁共振成像数据的重构效果,让脑电在视觉重构研究领域得到了突破。
[0113]
第二,本发明实现了在完备的空间内进行视觉重构。本发明突破训练数据样本类别有限的瓶颈,具备将脑电数据重构为任意一种现实中可能存在的人脸图像的能力。本发明充分发挥生成对抗网络的优势,利用生成对抗网络隐空间的特性实现对于任意人脸图像都能够实现视觉重构。
[0114]
第三,本发明所生成的图像具有高真实度,高分辨率的特点。相较于当前其余视觉重构研究的生成结果而言,本发明可以通过生成对抗网络所具有的强大的生成能力生成高分辨率、高质量、以假乱真的人脸图像。
[0115]
基于一个总的发明构思,本发明实施例还提供一种人在回路语义级视觉重构方法。
[0116]
图6为本发明实施例提供的一种人在回路语义级视觉重构方法的流程示意图,参
阅图6,本实施例可以包括以下步骤:
[0117]
步骤s61、在生成对抗网络的隐空间生成高维随机变量,得到目标图像;根据隐空间的高维随机变量生成优化图像;其中,优化图像为多个。
[0118]
步骤s62、将目标图像和优化图像进行不同频率的闪烁展示,通过ssvep实验,获取对应图像的脑电活动,以实现图像像素空间到脑电活动空间的映射。
[0119]
步骤s63、通过cca算法对脑电活动进行解码,选择最接近目标图像的一幅图像作为当前最优图像。
[0120]
步骤s64、判断当前最优图像是否满足重构效果要求;
[0121]
当当前最优图像不满足重构效果要求时,基于当前最优图像对应的隐空间随机变量,进行随机游走,产生新的隐空间的高维随机变量,更新高维随机变量,重新根据更新后的隐空间的高维随机变量生成优化图像;
[0122]
当当前最优图像满足重构效果要求,输出最优重构图像。
[0123]
在一些实施例中,根据隐空间的高维随机变量生成优化图像,包括:
[0124]
随机生成多个隐向量,经过标准化后与目标图像相加实现随机游走;随机游走后的多个隐向量通过gan网络,得到对应的优化图像;其中,优化图像中的图像个数与隐向量的个数相同。
[0125]
在一些实施例中,将目标图像和优化图像进行不同频率的闪烁展示,通过ssvep实验,获取对应图像的脑电活动,包括:
[0126]
在预设时长内展示目标图像,将优化图像中的图像分别按照不同的频率进行展示,以刺激被测者,使得被测者对刺激图像进行感知与决策,获取被测者的脑电活动。
[0127]
在一些实施例中,判断当前最优图像是否满足重构要求,包括:判断当前最优图像是否收敛。
[0128]
在一些实施例中,生成对抗网络采用对抗隐空间自编码器的结构;其中,自编码器为基于stylegan的自编码器。
[0129]
关于上述实施例中的方法,其中各个步骤执行操作的具体方式已经在有关该系统的实施例中进行了详细描述,此处将不做详细阐述说明。
[0130]
基于一个总的发明构思,本发明还提供了一种人在回路语义级视觉重构设备,用于实现上述方法实施例。
[0131]
图7为本发明实施例提供的一种人在回路语义级视觉重构设备的结构示意图,参阅图7,本发明实施例提供的人在回路语义级视觉重构设备包括处理器71和存储器72,处理器71与存储器72相连。其中,处理器71用于调用并执行存储器72中存储的程序;存储器72用于存储程序,程序至少用于执行以上实施例中的人在回路语义级视觉重构方法。
[0132]
可以理解的是,上述各实施例中相同或相似部分可以相互参考,在一些实施例中未详细说明的内容可以参见其他实施例中相同或相似的内容。
[0133]
需要说明的是,在本发明的描述中,术语“第一”、“第二”等仅用于描述目的,而不能理解为指示或暗示相对重要性。此外,在本发明的描述中,除非另有说明,“多个”的含义是指至少两个。
[0134]
流程图中或在此以其他方式描述的任何过程或方法描述可以被理解为,表示包括一个或更多个用于实现特定逻辑功能或过程的步骤的可执行指令的代码的模块、片段或部
分,并且本发明的优选实施方式的范围包括另外的实现,其中可以不按所示出或讨论的顺序,包括根据所涉及的功能按基本同时的方式或按相反的顺序,来执行功能,这应被本发明的实施例所属技术领域的技术人员所理解。
[0135]
应当理解,本发明的各部分可以用硬件、软件、固件或它们的组合来实现。在上述实施方式中,多个步骤或方法可以用存储在存储器中且由合适的指令执行系统执行的软件或固件来实现。例如,如果用硬件来实现,和在另一实施方式中一样,可用本领域公知的下列技术中的任一项或他们的组合来实现:具有用于对数据信号实现逻辑功能的逻辑门电路的离散逻辑电路,具有合适的组合逻辑门电路的专用集成电路,可编程门阵列(pga),现场可编程门阵列(fpga)等。
[0136]
本技术领域的普通技术人员可以理解实现上述实施例方法携带的全部或部分步骤是可以通过程序来指令相关的硬件完成,所述的程序可以存储于一种计算机可读存储介质中,该程序在执行时,包括方法实施例的步骤之一或其组合。
[0137]
此外,在本发明各个实施例中的各功能单元可以集成在一个处理模块中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个模块中。上述集成的模块既可以采用硬件的形式实现,也可以采用软件功能模块的形式实现。所述集成的模块如果以软件功能模块的形式实现并作为独立的产品销售或使用时,也可以存储在一个计算机可读取存储介质中。
[0138]
上述提到的存储介质可以是只读存储器,磁盘或光盘等。
[0139]
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
[0140]
尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1