提高目标检测模型鲁棒性的对抗训练方法及目标检测方法
1.本发明属于人工智能技术领域,涉及一种对抗训练方法及目标检测方法,具体涉及一种基于对抗攻击强度感知的提高目标检测模型鲁棒性的对抗训练方法及目标检测方法。
背景技术:
2.人工智能技术目前使用的算法与人类大脑的工作方式并不一样,人类能够借助某些伎俩来欺骗人工智能系统,比如在图像上叠加肉眼难以识别的修改,就可以欺骗主流的深度学习模型。这种经过修改的对机器具有欺骗能力而人类无法觉察出差别的样本被称为对抗样本(adversarial samples),机器接受对抗样本后做出的后续操作可能给无人驾驶之类智能无人系统造成灾难性后果。例如,已有研究者构造出一个图片,在人眼看来是一个stop 标志,但是在汽车看来是一个限速60的标志。当前学术界已经披露了几十种针对深度学习模型的对抗性攻击(adversarial attacks)手段,人工智能系统尤其是基于深度学习的智能系统的可靠性面临严峻挑战。
3.目前针对目标检测的深度学习模型的对抗攻击手段大多是基于pgd (project gradient descent)攻击。这种对抗攻击方法基于输入的图片进行迭代优化,优化目标为模型预测的目标种类损失l
cls
或目标定位损失l
loc
。通过这种方式可以对目标检测器的种类预测或位置预测做出有效的攻击,亦可通过l
cls
和l
loc
结合的方式,同时攻击二者,这种专门针对目标检测模型的对抗攻击方法被称为mtd。
4.现有针对深度学习模型对抗攻击的防御手段主要包括4种类型。对抗性样本检测:发现具有潜在危险的对抗样本,并将他们排除在处理范围之内;鲁棒优化:设计能够对扰动(perturbation)的影响完全鲁棒的目标模型,正确预测样本的原始类别;对抗训练:将对抗样本添加到训练集中进行针对性训练,从而增加预测模型的免疫力;扰动去除预处理:预处理输入样本以消除对抗性扰动。
5.其中对抗训练被认为是最有效的增强深度学习模型鲁棒性的方法,对抗训练可以很好的帮助模型学习鲁棒的特征,大大提高模型在处理对抗攻击图片时的准确性。
技术实现要素:
6.为了更好的学习具有鲁棒性的特征,提高目标检测模型应对不同强度的对抗攻击的能力,本发明提供的了一种基于对抗攻击强度感知的提高目标检测模型鲁棒性的对抗训练方法及目标检测方法。
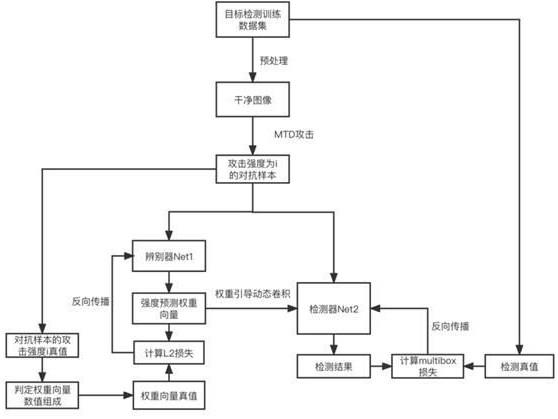
7.本发明的对抗训练方法采用的技术方案是:一种提高目标检测模型鲁棒性的对抗训练方法,所述目标检测模型包括辨别器net1和检测器net2;包括以下步骤:步骤1:采集干净样本图片作为训练数据集,并攻击样本图片,攻击的迭代次数为i,其中i=0则为输入干净的样本图片,攻击后生成的图片记为i;步骤2:将i输入辨别器net1,获得权重向量w(i)=[w1,w2,w3];其中w1,w2,w3表示
生成的权重值,它们被用于控制动态卷积。
[0008]
步骤3:将权重w(i)与检测器net2的动态卷积结合,使其感知对抗强度;设第j层动态卷积的参数组为{convj1,convj2,convj3},则与w(i)结合后,第j层最终采用的卷积参数为(convj1*w1+convj2*w2+convj3*w3);步骤4:将i输入已感知对抗强度的net2中,获得检测结果net2(i);步骤5:根据迭代次数i,获得w(i)的真值wgt;步骤6:将wgt与w(i)计算l2损失,并以此损失反向传播,更新net1的网络参数;步骤7:将net2(i)与训练数据集中给出的目标检测真值标签计算multibox损失,并以此损失反向传播,更新net2的网络参数;步骤8:重复步骤1-7,训练net1与net2至收敛,获得训练好的net1与net2。
[0009]
本发明的目标检测方法采用的技术方案是:一种目标检测方法,采用训练好的目标检测模型;包括以下步骤:(1)将待检测的图像i预处理成300
×
300
×
3的大小并输入到辨别器net1中,并对输出额外增加一层全连接与softmax处理,得到代表输入图片i的对抗攻击强度的一组1
×
3向量w(i);(2)将检测器net2中所有的卷积层用k=3的动态卷积层替代,然后将(1)中得到的w(i)作为所有动态卷积的权重;(3)将i输入net2中,获得最终的目标检测结果。
[0010]
与现有的对抗攻击样本的对抗学习防御方法相比,本发明具有以下优点和积极效果:(1)本发明基于攻击强度感知的对抗训练方法,使得目标检测网络可以感知对抗攻击强度,并具体体现在动态卷积的权重分配上,对于不同强度的对抗攻击有更好的鲁棒性,表现出了更好的检测效果;(2)本发明可以应对更广泛的对抗攻击场景,展现出了很好的适应性。
附图说明
[0011]
图1:本发明实施例的对抗训练方法流程图;图2:本发明实施例的辨别器net1网络结构图;图3:本发明实施例的检测器net2网络结构图;图4:本发明实施例的目标检测方法流程图;图5:本发明防御不同强度的cls对抗攻击的效果优越性。
具体实施方式
[0012]
为了便于本领域普通技术人员理解和实施本发明,下面结合附图及实施例对本发明作进一步的详细描述,应当理解,此处所描述的实施示例仅用于说明和解释本发明,并不用于限定本发明。
[0013]
在对抗训练中,干净样本与对抗样本对于网络参数的优化是矛盾的,这被通过采用动态卷积的方式解决。然而,不同强度的对抗攻击样本同样会影响网络的学习情况,单纯的分辨是否为对抗样本简单的将所有攻击强度的对抗样本归为一类,严重影响了深度学习
模型防御不同强度攻击的鲁棒性。而基于攻击强度感知的对抗训练方法,可以提高目标检测模型应对不同强度的对抗攻击的鲁棒性。
[0014]
请见图1,本发明提供的一种提高目标检测模型鲁棒性的对抗训练方法,目标检测模型包括辨别器net1和检测器net2;请见图2,本实施例的辨别器net1,采用resnet18网络的骨架,并将所有的batchnorm与其后续的relu用filter response normalization与thresholded linear unit替代。
[0015]
本实施例的分辨器net1包括18层采用残差连接的卷积模块,为生成指定形状输出所添加的线性函数全连接层,以及改进输出数值形式的softmax函数层。
[0016]
本实施例的卷积模块,第一层是卷积核为3*3的卷积层,第二层是用于替代relu的激活函数thresholded linear unit,第三层是用于替代批规范化层bn的规范化函数filter response normalization。
[0017]
本实施例的18层残差连接卷积模块,输出大小依次为112
×
112,56
×
56,28
×
28,14
×
14。下采样由maxpooling层实现,每两层模块会进行一次残差连接。
[0018]
本实施例的线性函数全连接层输入为14
×
14的卷积网络特征提取结果,输出为k=3的权重向量。
[0019]
本实施例的softmax函数层将权重和归一化,以输出最终的预测向量w(i)。
[0020]
请见图3,本实施例的检测器net2,采用vgg16网络作为骨架,用ssd网络的预训练模型填充网络参数,并通过复制参数的方式将其所有卷积层扩展为k=3的动态卷积。
[0021]
本实施例的检测器net2由vgg网络骨架的特征提取网络与用于目标检测的检测头组成。
[0022]
本实施例的vgg网络骨架的特征提取网络将所有的卷积层替换为包含3个卷积核{conv1,conv2,conv3}的动态卷积。最终用于目标检测的卷积核由net1生成的权重向量控制{conv1,conv2,conv3}计算生成。此外,为提高模型对抗鲁棒性,vgg骨架中的所有批规范化层均被去除。
[0023]
本实施例的检测头结合vgg骨架中提取的多尺度特征信息,按照检测类的数量与锚点数量生成相应形式的检测结果。
[0024]
本实施例的对抗训练方法包括以下步骤:步骤1:采集干净样本图片作为训练数据集,并采用基于pgd攻击的mtd方法攻击样本图片,攻击的迭代次数为i,i∈[0,20],其中i=0则为输入干净的样本图片,攻击后生成的图片记为i;本实施例中,在选取一个大小为32的训练批次(batch)时,随机选取32张样本图片并预处理为预设大小300
×
300
×
3;其中n为训练批次大小;对其中的16张图片施加一次迭代的基于pgd攻击的mtd方法攻击,生成16张对抗样本,其对抗攻击强度为i=1;将16张对抗样本与16张干净样本合并作为一个训练批次batch,输入到net1中;在后续训练迭代中,重新选择干净样本,保持上一迭代的对抗样本,重复执行迭代,当迭代次数大于i后,重置i=1,并重新选取对抗样本。
[0025]
步骤2:将输入辨别器net1,获得权重向量w(i)=[w1,w2,w3];其中w1, w2,w3 表示生成的权重值,它们被用于控制动态卷积。
[0026]
步骤3:将权重w(i)与检测器net2的动态卷积结合,使其感知对抗强度;设第j层动态卷积的参数组为{convj1,convj2,convj3},则与w(i)结合后,第j层最终采用的卷积参数为(convj1*w1+convj2*w2+convj3*w3)。
[0027]
步骤4:将i输入已感知对抗强度的net2中,获得检测结果net2(i)。
[0028]
步骤5:根据迭代次数i,获得w(i)的真值wgt;本实施例中,根据i值预设获取wgt向量的数值,若i=0,则wgt=[1,0,0];若i∈{1,2,3},则wgt=[0,1,0];若i∈{18,19,20},则wgt=[0,0,1]。
[0029]
步骤6:将wgt与w(i)计算l2损失,并以此损失反向传播,更新net1的网络参数。
[0030]
步骤7:将net2(i)与数据集中给出的目标检测真值标签计算multibox损失,并以此损失反向传播,更新net2的网络参数;本实施例中,将wgt与w(i)计算l2损失,如下:当i∈[5,17]时,不计算损失,不更新辨别器net1的网络参数。
[0031]
步骤8:重复步骤1-7,训练net1与net2至收敛,获得训练好的net1与net2。
[0032]
请见图4,本实施例提供的一种目标检测方法,采用训练好的目标检测模型;包括以下步骤:(1)将待检测的图像i预处理成300
×
300
×
3的大小并输入到辨别器net1中,并对输出额外增加一层全连接与softmax处理,得到代表输入图片i的对抗攻击强度的一组1
×
3向量w(i);(2)将检测器net2中所有的卷积层用k=3的动态卷积层替代,然后将(1)中得到的w(i)作为所有动态卷积的权重;(3)将i输入net2中,获得最终的目标检测结果。
[0033]
在对抗训练的过程中,干净样本与对抗样本对于网络参数的梯度影响是互相矛盾的。为了让干净与对抗样本同时对改善网络参数做出贡献,一种方法是预测样本是否为对抗样本后,利用动态卷积来分离干净与对抗样本的影响。然而这种方法仅仅对对抗样本有感知,即判别是否为对抗样本,分类的粒度有限。同时尽管在训练过程中使用了不同攻击强度的对抗攻击样本,但已知的攻击强度信息并没有被利用起来,这导致训练好的模型在应对不同强度的对抗攻击时,表现出较差的防御鲁棒性。为了解决这个问题,本发明提出了一种感知对抗样本的攻击强度的训练方法,可以细粒度的分辨输入的样本是干净样本,弱攻击样本或强攻击样本。通过这种方式可以更好的学习具有鲁棒性的特征,提高目标检测模型应对不同强度的对抗攻击的能力。
[0034]
请见图5,为本实施例对voc数据集的训练集施加不同强度的cls攻击后,使用不同目标检测方法的检测结果。可以看到本发明的方法(ours)在面对不同攻击强度时,效果是最稳定最好的。
[0035]
应当理解的是,上述针对较佳实施例的描述较为详细,并不能因此而认为是对本发明专利保护范围的限制,本领域的普通技术人员在本发明的启示下,在不脱离本发明权利要求所保护的范围情况下,还可以做出替换或变形,均落入本发明的保护范围之内,本发明的请求保护范围应以所附权利要求为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1