一种基于分散训练的标签推理攻击的防御方法和装置与流程
1.本发明涉及一种联邦学习及密码学技术领域,尤其涉及一种基于分散训练的标签推理攻击的防御方法和装置。
背景技术:
2.机器学习在做决策、风险识别和疾病诊断等众多领域取得了巨大成功。机器学习的广泛使用及其有效性,除了因为机器学习算法的进步外,还有收集、存储和处理大量数据,但是这样做的成本越来越高。特别是,整合使用来自多个来源的数据(例如,不同机构收集的数据或存储在不同数据中心的数据)。然而,共享数据可能会遇到安全和隐私问题。随着数据隐私保护意识的增强,法律禁止共享包含公民敏感信息的数据。例如,欧盟的一般数据保护条例(gdpr)、新加坡的个人数据保护法案(pdpa)、美国的加利福尼亚消费者隐私法案(ccpa)和我国的《个人信息保护法》等法规。
3.在这种情况下,联邦学习(fl)被提出并得到了广泛的使用。它使多个数据所有者(例如,客户端或数据中心)能够协作培训机器学习模型,而不会泄露其私人数据。基本工作流程是,联邦学习的参与者迭代地(i)对其数据进行本地计算,以得出某些中间结果,(ii)使用某些加密工具隐藏中间结果,以及(iii)与其他参与者共享受保护的结果,直到获得最终的训练结果。
4.根据数据划分的不同,联邦可以分为横向联邦学习(hfl)、纵向联邦学习(vfl)和迁移学习。横向联邦学习处理数据水平划分的情况,即数据集共享相同的特征空间,但样本空间不同。例如,两家医院拥有不同患者群体的病历(即样本空间),描述他们是否患有某种疾病(即特征空间)。相比之下,纵向联邦学习处理数据垂直划分的情况,即数据集共享相同的样本空间,但特征空间不同。纵向联邦学习的一个典型例子是,两家医院持有同一组患者的病历(即健全的样本空间),但每一家医院都描述了患者医疗状态的不同方面,例如,医院a的数据集记录了患者的covid拭子测试,而医院a的数据集记录了他们的胸部ct扫描(即不同的特征空间)。
5.横向联邦学习模型的构造简单,它通常是通过模型平均来构建的——对于每次迭代,客户端都会为几个阶段训练一个模型,并将其模型发送给客户端,客户端随后会聚合上传的本地模型并获得更新的全局模型。但对于纵向联邦学习来说,特别是用模型划分构造的纵向联邦学习来说,训练过程相对复杂。在具有模型划分的纵向联邦学习中,整个模型被分为一个顶层模型(在服务端上保存)和几个底层模型(作为在客户端保存的特定中间状态)。训练过程通过反复的双边通信完成。客户端使用本地数据运行其底层模型,并将结果上传到服务端;服务端运行一个顶层模型来聚合参与者的输出,计算损失的梯度,并将梯度发回给每个参与者。
6.因此,横向联邦学习的潜在攻击者有机会窥探模型所有参数的梯度,这些参数可用于推断隐私信息。相比之下,纵向联邦学习的攻击者只控制联邦模型的一部分,因此只能获取不完整模型的梯度。因此,人们普遍认为纵向联邦学习具有更高的安全保障,特别是对
作为新的第一训练集,得到的 作为第三训练集。
13.进一步地,所述步骤s2中底层模型为线性模型,其中的激活函数也为线性关系。
14.进一步地,所述步骤s3中所述合并函数为mergeshare,所述第一模型根据所述第一模型参数产生的中间结果和所述影子模型根据所述影子模型参数产生的中间结果利用合并函数mergeshare进行加和得到更新后的第一模型的中间结果。
15.进一步地,所述步骤s3中将更新后的第一模型的中间结果和所述第二模型根据所述第二模型参数产生的中间结果采用函数concat进行汇聚得到底层模型的所有的输出结果。
16.进一步地,所述步骤s5中当顶层模型将梯度下传给恶意参与方a时,首先生成恶意参与方a的梯度,以秘密分享函数得到新的恶意参与方梯度和新的诚实参与方c梯度,然后将新的恶意参与方梯度下传给恶意参与方a,将新的诚实参与方c梯度下传给诚实参与方c。
17.本发明还提供一种基于分散训练的标签推理攻击的防御装置,包括存储器和一个或多个处理器,所述存储器中存储有可执行代码,所述一个或多个处理器执行所述可执行代码时,用于实现上述任一项所述的一种基于分散训练的标签推理攻击的防御方法。
18.本发明还提供一种计算机可读存储介质,其上存储有程序,该程序被处理器执行时,实现上述任一项所述的一种基于分散训练的标签推理攻击的防御方法。
19.本发明的有益效果是:在本发明中,提出了分散训练的模型框架,以此来抵抗此类攻击并实现纵向联邦学习的安全性。本发明分散训练的基本思想是利用秘密共享打破梯度和训练数据之间的相关性。参与者b拥有自己带标签的数据,希望训练模型;他希望利用参与者a的数据来提高模型的质量。参与者a是敌手,他打算推断参与者b的标签。在分散训练的框架中,为参与者a创建一个影子模型(即参与者c),参与者b的部分数据共享给参与者c。在训练阶段,客户端(即参与者a和c)使用共享的数据更新其底层模型,并将其部分输出上传到服务端。服务端聚合客户端的部分输出并训练其顶层模型;由于秘密共享方案的线性性质,它们的输出可以有效地聚合。服务端的训练输出也分为两部分,分别提供a和c两个部分,后者随后迭代地训练和更新其底层模型。使用这种方法,即使攻击者在训练阶段收到梯度,他也无法从底层模型推断标签的特征表示。本发明可以将纵向联邦学习的标签推理攻击的效果降低到随机猜测的程度,避免了在联邦学习训练时标签信息的泄露,有效防御了纵向联邦学习中的标签推理攻击。
附图说明
20.图1为本发明一种基于分散训练的标签推理攻击的防御方法的示意图;图2为本发明一种基于分散训练的标签推理攻击的防御方法的流程示意图;图3为原始的标签推理攻击效果和防御之后的效果对比图;图4为主动标签推理攻击和防御之后的攻击效果对比图。
具体实施方式
21.以下对至少一个示例性实施例的描述实际上仅仅是说明性的,决不作为对本发明及其应用或使用的任何限制。基于本发明中的实施例,本领域普通技术人员在没有作出创
造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
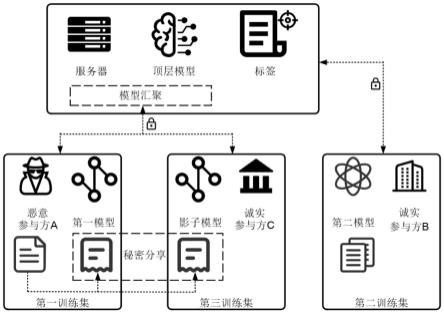
22.参见图1-图2,一种基于分散训练的标签推理攻击的防御方法,包括以下步骤:步骤s1:初始化参与方的底层模型;其中,所述参与方包括有推理标签能力的恶意参与方a、诚实参与方b和诚实参与方c,所述恶意参与方a中的底层模型为第一模型,所述诚实参与方b中的底层模型为第二模型,所述诚实参与方c中的底层模型为影子模型,所述第一模型与所述影子模型结构相同;所述影子模型和所述第一模型结构相同。
23.步骤s2:所述参与方根据各自的训练集和各自的参数进行梯度的前向传播、后向传播对底层模型进行训练,得到底层模型参数;其中,训练第一模型的训练集为第一训练集,训练第二模型的训练集为第二训练集,训练影子模型的训练集为第三训练集,所述第三训练集由所述第一训练集拆分得到;所述底层模型参数包括第一模型参数、第二模型参数和影子模型参数,所述第一模型参数是所述恶意参与方a基于第一训练集对所述第一模型训练得到,所述第二模型参数是所述诚实参与方b基于第二训练集对所述第二模型训练得到,所述影子模型参数是所述诚实参与方c基于第三训练集对所述影子模型训练得到;所述恶意参与方a采用局部优化器训练第一模型,所述诚实参与方b和所述诚实参与方c采用sgd训练各自的模型;所述步骤s2中所述恶意参与方a采用局部优化器训练第一模型,所述诚实参与方b和所述诚实参与方c采用sgd训练各自的模型;所述第三训练集由所述第一训练集拆分得到具体为:选择一个随机数,所述随机数为0-1,利用所述随机数将第一训练集进行拆分,得到的作为新的第一训练集,得到的作为第三训练集;所述底层模型为线性模型,其中的激活函数relu()也为线性关系;在整个的训练过程中,第一模型和影子模型之间各层参数之间也一直是线性关系;步骤s3:将所述第一模型根据所述第一模型参数产生的中间结果和所述影子模型根据所述影子模型参数产生的中间结果通过合并函数合并得到更新后的第一模型的中间结果,将更新后的第一模型的中间结果和所述第二模型根据所述第二模型参数产生的中间结果进行汇聚,得到底层模型的所有的输出结果;虽然恶意参与方a和诚实参与方c都参与了训练,但是对于顶层模型来说,仍然只与恶意参与方a的第一模型之间有接口;所述合并函数为mergeshare,所述第一模型根据所述第一模型参数产生的中间结果和所述影子模型根据所述影子模型参数产生的中间结果利用合并函数mergeshare进行加和得到更新后的第一模型的中间结果;在恶意参与方a的第一模型和诚实参与方c的影子模型训练好本地模型产生输出第一模型参数产生的中间结果oa和影子模型参数产生的中间结果oc后,该函数将oa、oc看作两个份额,通过mergeshare ()(e.g.加法)将第一模型参数产生的中间结果和影子模型参数产生的中间结果合并为一个更新后的第一模型的中间结果oa。这个更新后的第一模型的中间结果oa通过顶层模型和第一模型的接口传送给顶层模型。然后将汇聚后的结果传送给顶层模型。
24.需要注意的是:第一模型和影子模型在训练的时候就保持线性关系,因此他们的
合并结果和第一模型单独训练之后的上传结果是一致的。也就是说,本发明中合并之后传给更新后的第一模型的中间结果oa和直接将结果上传给顶层模型的是一样的。这里假设在第一模型、影子模型与顶层模型之间有一个输出合并层。它的主要功能是合并第一模型和影子模型的输出给顶层模型。与此同时,还需要将从顶层模型接收到的梯度,首先进行秘密分享,然后分别下传给第一模型和影子模型。
25.将更新后的第一模型的中间结果和所述第二模型根据所述第二模型参数产生的中间结果采用函数concat进行汇聚得到底层模型的所有的输出结果;第一模型和第二模型的输出汇聚:经过上一步的汇聚之后,顶层模型通过与第一模型和第二模型的接口,分别获得更新后的第一模型的中间结果oa和第二模型参数产生的中间结果ob,利用函数concat(),将更新后的第一模型的中间结果oa和第二模型参数产生的中间结果ob进行汇聚,生成底层模型的所有的输出结果o
all
,由顶层模型进一步训练。
26.步骤s4:将底层模型的所有的输出结果作为服务器中的顶层模型的输入,并根据顶层模型参数进行梯度的前向传播、后向传播进行训练,得到训练后的顶层模型并且更新顶层模型的参数;顶层模型的本地训练:接收到底层模型的所有的输出结果o
all
后,将其作为顶层模型的输入,进一步训练顶层模型,得到顶层模型的输出o
finall
。由于从第一模型和影子模型是接受的汇聚之后的结果,因此,本发明的顶层模型的本地训练与单独训练第一模型和影子模型结果是一致的。
27.步骤s5:利用训练后的顶层模型参数和顶层模型的标签进行损失函数的计算,根据得到的损失函数和顶层模型参数进行梯度求解,得到顶层模型的梯度,顶层模型将梯度下传给恶意参与方a和诚实参与方b;当顶层模型将梯度下传给恶意参与方a时,首先生成恶意参与方a的梯度,以秘密分享函数得到新的恶意参与方梯度和新的诚实参与方c梯度,然后将新的恶意参与方梯度下传给恶意参与方a,将新的诚实参与方c梯度下传给诚实参与方c;顶层模型的本地训练之后,首先计算损失函数,然后将梯度下传到底层模型中。顶层模型会分别将梯度传给第一模型和第二模型,第二模型接受梯度。但是在下传梯度给第一模型时,因为涉及到影子模型,所以首先生成第一模型的梯度ga,以秘密分享函数ss()得到新的ga和gc,然后下传给第一模型和影子模型,这一功能由输出合并层实现。
28.步骤s6:重复步骤s1-s5直至顶层模型和底层模型收敛。
29.实施例:一种基于分散训练的标签推理攻击的防御方法,包括以下步骤:步骤s1:初始化参与方的底层模型;其中,所述参与方包括有推理标签能力的恶意参与方a、诚实参与方b和诚实参与方c,所述恶意参与方a中的底层模型为第一模型,所述诚实参与方b中的底层模型为第二模型,所述诚实参与方c中的底层模型为影子模型,所述第一模型与所述影子模型结构相同;所述影子模型和所述第一模型结构相同。
30.步骤s2:所述参与方根据各自的训练集和各自的参数进行梯度的前向传播、后向传播对底层模型进行训练,得到底层模型参数;其中,训练第一模型的训练集为第一训练集,训练第二模型的训练集为第二训练集,训练影子模型的训练集为第三训练集,所述第三
训练集由所述第一训练集拆分得到;所述底层模型参数包括第一模型参数、第二模型参数和影子模型参数,所述第一模型参数是所述恶意参与方a基于第一训练集对所述第一模型训练得到,所述第二模型参数是所述诚实参与方b基于第二训练集对所述第二模型训练得到,所述影子模型参数是所述诚实参与方c基于第三训练集对所述影子模型训练得到;所述恶意参与方a采用局部优化器训练第一模型,所述诚实参与方b和所述诚实参与方c采用sgd训练各自的模型;所述步骤s2中所述恶意参与方a采用局部优化器训练第一模型,所述诚实参与方b和所述诚实参与方c采用sgd训练各自的模型;所述第三训练集由所述第一训练集拆分得到具体为:选择一个随机数,所述随机数为0-1,利用所述随机数将第一训练集进行拆分,得到的作为新的第一训练集,得到的作为第三训练集;所述底层模型为线性模型,其中的激活函数relu()也为线性关系;在整个的训练过程中,第一模型和影子模型之间各层参数之间也一直是线性关系;本实施例选用top1准确率作为对联邦原始任务和标签推理攻击效果的性能指标,top1 准确率是指预测的标签取最后概率向量里面最大的一个作为预测结果。如果这个预测结果是实际标签,则意味着预测正确,否则预测错误。本文在训练攻击模型过程中,选用额外少量带标签的数据对底层模型进行半监督训练。在攻击模型实验中cifar-10,cinic-10实际选取的是40个带标签的样本,bcw数据集选取了20个带标签的数据来进行半监督训练。带标签的数量会影响到标签推理攻击的效果,当样本达到一定数量后,标签推理攻击的结果会增长缓慢。
31.步骤s3:将所述第一模型根据所述第一模型参数产生的中间结果和所述影子模型根据所述影子模型参数产生的中间结果通过合并函数合并得到更新后的第一模型的中间结果,将更新后的第一模型的中间结果和所述第二模型根据所述第二模型参数产生的中间结果进行汇聚,得到底层模型的所有的输出结果;虽然恶意参与方a和诚实参与方c都参与了训练,但是对于顶层模型来说,仍然只与恶意参与方a的第一模型之间有接口;所述合并函数为mergeshare,所述第一模型根据所述第一模型参数产生的中间结果和所述影子模型根据所述影子模型参数产生的中间结果利用合并函数mergeshare进行加和得到更新后的第一模型的中间结果;在恶意参与方a的第一模型和诚实参与方c的影子模型训练好本地模型产生输出第一模型参数产生的中间结果oa和影子模型参数产生的中间结果oc后,该函数将oa、oc看作两个份额,通过mergeshare ()(e.g.加法)将第一模型参数产生的中间结果和影子模型参数产生的中间结果合并为一个更新后的第一模型的中间结果oa。这个更新后的第一模型的中间结果oa通过顶层模型和第一模型的接口传送给顶层模型。然后将汇聚后的结果传送给顶层模型。
32.需要注意的是:第一模型和影子模型在训练的时候就保持线性关系,因此他们的合并结果和第一模型单独训练之后的上传结果是一致的。也就是说,本实施例中合并之后传给更新后的第一模型的中间结果oa和直接将结果上传给顶层模型的是一样的。这里假设在第一模型、影子模型与顶层模型之间有一个输出合并层。它的主要功能是合并第一模型
和影子模型的输出给顶层模型。与此同时,还需要将从顶层模型接收到的梯度,首先进行秘密分享,然后分别下传给第一模型和影子模型。
33.将更新后的第一模型的中间结果和所述第二模型根据所述第二模型参数产生的中间结果采用函数concat进行汇聚得到底层模型的所有的输出结果;第一模型和第二模型的输出汇聚:经过上一步的汇聚之后,顶层模型通过与第一模型和第二模型的接口,分别获得更新后的第一模型的中间结果oa和第二模型参数产生的中间结果ob,利用函数concat(),将更新后的第一模型的中间结果oa和第二模型参数产生的中间结果ob进行汇聚,生成底层模型的所有的输出结果o
all
,由顶层模型进一步训练。
34.步骤s4:将底层模型的所有的输出结果作为服务器中的顶层模型的输入,并根据顶层模型参数进行梯度的前向传播、后向传播进行训练,得到训练后的顶层模型并且更新顶层模型的参数;顶层模型的本地训练:接收到底层模型的所有的输出结果o
all
后,将其作为顶层模型的输入,进一步训练顶层模型,得到顶层模型的输出o
finall
。由于从第一模型和影子模型是接受的汇聚之后的结果,因此,本实施例的顶层模型的本地训练与单独训练第一模型和影子模型结果是一致的。
35.步骤s5:利用训练后的顶层模型参数和顶层模型的标签进行损失函数的计算,根据得到的损失函数和顶层模型参数进行梯度求解,得到顶层模型的梯度,顶层模型将梯度下传给恶意参与方a和诚实参与方b;当顶层模型将梯度下传给恶意参与方a时,首先生成恶意参与方a的梯度,以秘密分享函数得到新的恶意参与方梯度和新的诚实参与方c梯度,然后将新的恶意参与方梯度下传给恶意参与方a,将新的诚实参与方c梯度下传给诚实参与方c;顶层模型的本地训练之后,首先计算损失函数,然后将梯度下传到底层模型中。顶层模型会分别将梯度传给第一模型和第二模型,第二模型接受梯度。但是在下传梯度给第一模型时,因为涉及到影子模型,所以首先生成第一模型的梯度ga,以秘密分享函数ss()得到新的ga和gc,然后下传给第一模型和影子模型,这一功能由输出合并层实现。
36.步骤s6:重复步骤s1-s5直至顶层模型和底层模型收敛。
37.(1)数据集介绍:本实施例选用的数据集分别是cifar-10、cinic-10、bcw数据集。 cifar-10是一个典型的分类数据集,它包含60000张图片,其中50000张图片作为训练集,10000张图片作为测试集。其中每张照片都是32*32的彩色图片,整个数据集的图片一共有10个不同类别。cinic-10: cinic-10是cifar-10通过下采样的imagenet图像扩展而来的,和cifar-10一样,也是分为10个类别。为了解决cifar-10数量较少的问题,所以出现了cinic-10数据集。它包含270000张图片,是cifar-10的4.5倍。这些图片平均划分为三个子集:训练集、验证集和测试集。每个子集有90000张图像,训练集的数量是cifar-10的1.8倍,测试集的数量是cifar-10的9倍,通过这个数据集可以测试本实施例在大数据集上的效果。bcw:bcw数据集是乳腺癌的数据集,总共569条数据,32个特征列,主要针对于细胞核特征,样本的标签是诊断的结果是良性还是恶性。实验中所用的数据集是fu等人用的数据集,该数据集随机选取426个样本作为训练集,剩下的143个样本作为测试集。
38.(2)实验结果及分析:经过分散训练后的模型,面对被动标签推理攻击的性能表现如图3所示,在三个数据集上的攻击预测第一个标签为真实标签的准确率(top1准确率)上
可以看出,相比于fu等人提出的标签推理攻击,效果有了大幅度的下降,尤其在cifar-10数据集上下降了70%左右。经过分散训练后在cifar-10、cinic-10、bcw数据集上的攻击的预测第一个标签为真实标签的准确率(top1准确率)分别为9.99%、10.02%、36.36%。对于cifar-10、cinic-10数据集来说,攻击的预测第一个标签为真实标签的准确率(top1准确率)降低到了10%左右,这两个数据集只有十个类别,所以10%的攻击预测第一个标签为真实标签的准确率(top1准确率)相当于对这十个类别的随机猜测。从cifar-10数据集到cinic-10数据集的结果都在10%左右,说明了本实施例在大数据集上也有很好的防御效果。总体来说,本实施例提出的分散训练,可以有效的防止被动标签推理攻击。
39.除此之外,本实施例对主动标签推理攻击也做了比较。由图4可知,经过分散训练后的模型对主动标签推理攻击同样有效。在cifar-10数据集上将攻击预测第一个标签为真实标签的准确率(top1准确率)从84.84%下降到10%左右,对于另外两个数据集的攻击预测第一个标签为真实标签的准确率(top1准确率)也有明显的下降。总的来说本实施例可以将标签推理攻击的准确率降低到随机猜测,证明了分散训练可以有效的缓解标签推理攻击。
40.表1展示了分散训练后各个数据集在原始联邦学习的准确率。与原始联邦学习相比,分散后的联邦准确率下降了。在bcw、cifar-10和cinic-10数据集分别下降了4%、15%和18%。其中cifar-10和cinic-10数据集的准确率下降较为明显,是由数据集过大导致。虽然经过分散后可以有效的防止标签推理攻击,但是联邦准确率也进行了一定程度的下降,尤其是在大型数据集上下降效果明显。因此,实施分散训练需要权衡防御标签推理攻击和联邦训练准确率。
41.表1 原始联邦任务的性能和应用本发明防御后的性能比较
数据集衡量标准原始联邦任务防御后的联邦任务cifar-10预测第一个标签为真实标签的准确率(准确率)0.82020.6784cinic-10预测第一个标签为真实标签的准确率(top1准确率)0.71320.5306bcw预测第一个标签为真实标签的准确率(top1准确率)0.86710.8252
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1