一种用户自定义函数的实现方法和系统与流程
本发明涉及计算机软件的,尤其是一种用户自定义函数的实现方法和系统。
背景技术:
1、udf(user defined function)即用户自定义函数,它接受参数、执行操作并返回该操作的结果。广义udf是用户自定义标量函数(udf)、用户自定义表值函数(udtf)、及用户自定义聚合函数(udaf)三种函数的集合,狭义udf表示用户自定义标量函数(udf)。
2、大数据业务场景下,flink作为当前应用最为广泛的分布式计算组件,向用户提供了使用sql发起计算请求的能力以降低不同技术领域人员的开发和使用门槛。flink sql自身预置了许多通用函数,可以满足大部分业务场景的数据处理需求,当这些预置函数无法支撑复杂或个性化业务实现时,用户可以参考flink sql预置函数的实现,自行编写代码逻辑来创建自定义函数,以扩展flink sql查询功能,满足多样化的大数据计算和业务分析需求。
3、在正式使用udf前,通常需要由开发人员按照业务要求先在线下编辑器中分别编写java、scala、python等不同语言实现的udf源码程序,将其编译打包成jar包后与相应的flink作业一同上传到分布式集群中提交运行。若运行失败,还需要重新经历程序修改、编译打包、提交运行等流程,步骤繁琐,调试困难,也无法实现不同技术领域的开发人员和普通用户进行协同开发的需求,极大地限制了用户调试和使用udf的能力。
4、当前存在某种解决方案,可通过单独的可视化组件编辑udf并将编译后的udf文件存入数据库,之后该组件将udf唯一文件标识作为目标任务的参数提交到集群运行,此方案在udf编译和调试时期间需要频繁远程连接数据库进行udf文件的上传和下载,增加网络开销的同时会降低调试效率,并且重复调试过程容易造成数据库存放大量无效udf文件。另有解决方案可直接在线提交udf源码并在运行时编译udf,但容易造成对已验证通过的udf重复编译问题,且不能同时支持java、scala、python等通用大数据开发语言在线混合编程,无法满足普通用户和专业技术人员协同开发和调试需求。
技术实现思路
1、为了解决现有技术中存在的上述技术问题,本发明提出了一种用户自定义函数的实现方法和系统,以解决上述技术问题。
2、根据本发明的一个方面,提出了一种用户自定义函数的实现方法,包括:
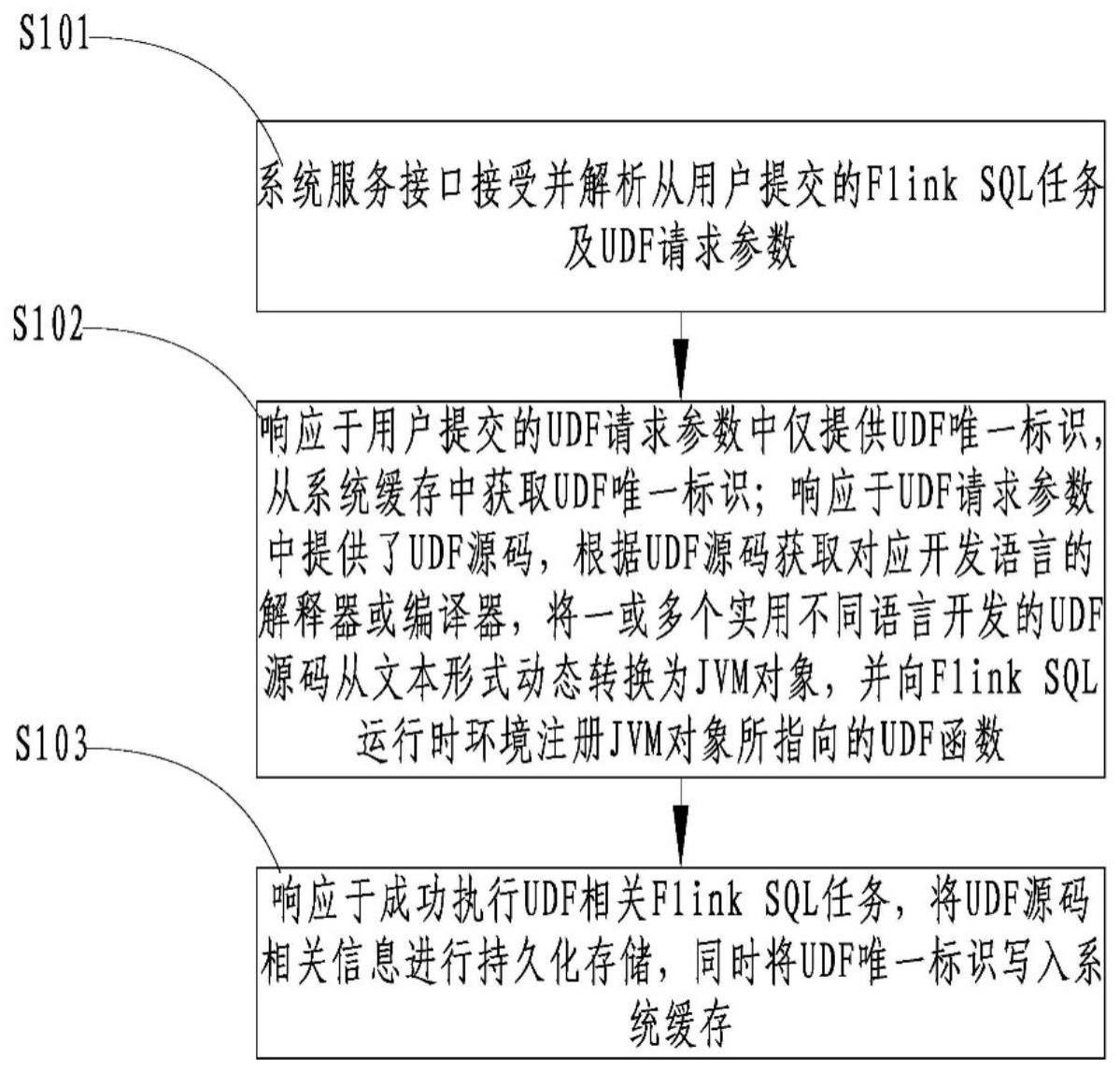
3、s1:系统服务接口接受并解析从用户提交的flink sql任务及udf请求参数;
4、s2:响应于用户提交的udf请求参数中仅提供udf唯一标识,从系统缓存中获取udf唯一标识;
5、响应于udf请求参数中提供了udf源码,根据udf源码获取对应开发语言的解释器或编译器,将一或多个使用不同语言开发的udf源码从文本形式动态转换为jvm对象,并向flink sql运行时环境注册jvm对象所指向的udf函数;
6、s3:响应于成功执行udf相关flink sql任务,将udf源码相关信息进行持久化存储,同时将udf唯一标识写入系统缓存。
7、在一些具体的实施例中,s2具体包括:
8、响应于udf唯一标识已存在,继续执行s3;
9、响应于udf唯一标识不存在,获取对应udf源码,并将udf唯一标识写入系统全局缓存,继续执行s3。
10、在一些具体的实施例中,udf源码获取对应开发语言的解释器或编译器,对udf源码进行运行时动态解析和编译,具体包括:
11、响应于udf源码为python,通过jython将udf源码动态解析为jvm对象;
12、响应于udf源码为scala,通过scala toolbox将udf源码动态解析为jvm对象;
13、响应于udf源码为java,通过javacompiler动态编译udf源码,使用类加载器将生成的java字节码载入jvm中运行。
14、在一些具体的实施例中,s3中执行udf相关flink sql任务具体包括以下步骤:
15、响应于udf函数已存在于系统缓存中,无需重复编译和注册;
16、响应于udf函数为通过解释器或编译器处理后的jvm对象,将jvm对象所指向的udf函数注册到flink sql运行时环境中,注册时使用udf唯一标识作为在flink sql运行时环境中供用户重复使用的udf函数名称;
17、在flink sql运行时环境中运行用户提交的sql作业,其中,sql中包括一或多个使用不同开发语言实现的udf函数。
18、在一些具体的实施例中,s3中将udf源码相关信息进行持久化存储,同时将udf唯一标识写入系统缓存具体包括以下步骤:
19、响应于udf参数中仅提供了udf源码,覆盖当前flink sql运行时环境或持久化存储中保存的同名udf函数,将udf源码进行运行时动态解析或编译,并向flink sql运行时环境注册编译后的jvm对象;
20、响应于udf参数中未提供udf源码,且系统缓存中不存在udf唯一标识,将udf源码进行运行时动态解析或编译,并向flink sql运行时环境注册编译后的jvm对象;
21、提交运行flink sql任务,响应于flink sql任务执行成功,将udf源码相关信息进行持久化存储,同时将udf唯一标识写入系统缓存。
22、在一些具体的实施例中,udf参数包括udf唯一标识、udf开发语言和udf源码。
23、根据本发明的第二方面,提出了一种计算机可读存储介质,其上存储有一或多个计算机程序,该一或多个计算机程序被计算机处理器执行时实施上述任一项的方法。
24、根据本发明的第三方面,提出了一种用户自定义函数的实现系统,系统包括:
25、参数解析模块,配置用于接收并解析从用户提交的flink sql任务及udf请求参数;
26、编译模块,配置用于针对不同开发语言编写的udf源码,通过各自对应的解释器或编译器对udf源码进行运行时动态解析和编译,生成能够在jvm环境中运行的对象;
27、任务执行模块,配置用于在flink sql运行时环境中运行用户提交的sql作业,其中,sql中包括一或多个使用不同开发语言实现的udf函数;
28、存储模块,配置用于,将udf源码相关信息进行持久化存储,同时将udf唯一标识写入系统缓存。
29、在一些具体的实施例中,参数解析模块接收用户提交的flink sql任务请求参数,每个任务提供一或多个不同语言开发的udf函数,每个udf函数的参数包括udf唯一标识、udf开发语言和udf源码。
30、在一些具体的实施例中,编译模块接收到udf源码参数后,根据udf开发语言类型,获取相应的解释器或编译器,对udf源码进行运行时动态解析和编译,具体包括:
31、响应于udf源码为python,通过jython将udf源码动态解析为jvm对象;
32、响应于udf源码为scala,通过scala toolbox将udf源码动态解析为jvm对象;
33、响应于udf源码为java,通过javacompiler动态编译udf源码,使用类加载器将生成的java字节码载入jvm中运行。
34、在一些具体的实施例中,任务执行模块的实现步骤包括:
35、响应于udf函数已存在于系统缓存中,无需重复编译和注册;
36、响应于udf函数为通过解释器或编译器处理后的jvm对象,将jvm对象所指向的udf函数注册到flink sql运行时环境中,注册时使用udf唯一标识作为在flink sql运行时环境中供用户重复使用的udf函数名称;
37、在flink sql运行时环境中运行用户提交的sql作业,其中,sql中包括一或多个使用不同开发语言实现的udf函数。
38、在一些具体的实施例中,存储模块通过系统缓存和持久化存储提高udf复用和可重复调试能力,系统缓存采用jvm进程内缓存,持久化存储采用基于文档的nosql数据库。
39、本发明提出了一种用户自定义函数的实现方法和系统,将调试成功的udf进行持久化保存以提高udf复用能力,通过系统缓存机制,减少持久化存储的远程连接开销,解决udf重复编译问题,加快调试效率,通过多语言在线混合编程方式,解决协同开发难题。
- 还没有人留言评论。精彩留言会获得点赞!