一种视频图像暴力行为检测模型及检测方法
本发明属于人工智能和视频理解,涉及一种视频图像暴力行为检测模型及检测方法,能够实现从实时监控视频中自动检测暴力行为,提供实时预警,并完成监控日志记录,可用于公共安全领域,协助治安管理及案件侦破。
背景技术:
1、
2、现有技术的方案:受到高精度目标检测算法faster r-cnn的启发,现有大多数工作将经典的两阶段网络架构应用于暴力行为检测中,基本思路为:对于待检测视频片段,首先,在第一阶段对视频中每帧图像执行目标检测算法,以产生多个动作候选框;其次,在第二阶段利用动作分类模型对行为进行分类和定位细化。
3、feichtenhofer等人在文献“feichtenhofer c,fan h,malik j,et al.slowfastnetworks for video recognition[c]//proc of ieee/cvf iccv.piscataway,nj:ieeepress,2019:6201-6210”中提出了用于视频行为识别的slowfast网络,该网络首先利用faster r-cnn目标检测算法将每个视频帧中的人体进行定位,然后利用一个低频的慢速路径和高频的快速路径分别用于提取空间特征和时间特征,进而实现暴力行为检测。
4、dong等人在文献“dong min,fang zhenglin,li yongfa,et al.ar3d:attentionresidual 3d network for human action recognition[j].sensors,2021,21(5):1656-1669”中利用残差结构和注意机制对现有的3d卷积模型进行了改进,提出了注意残差3d网络(ar3d),加强了人体行为特征的提取。
5、李颀等人在文献“基于轻量级图卷积网络的校园暴力行为识别”中提出了一种基于轻量级图卷积的人体骨架数据的行为识别方法,通过多信息流数据融合与自适应图卷积相结合的方式,实现了行为识别。
6、现有技术的缺点:以上方法在暴力行为检测中存在三个缺陷,首先,由跨多个帧的边界框组成的动作管道的生成要比二维的情况复杂得多,也更加费时;其次,动作候选框只关注视频中人体的特征,忽略了人体与背景的潜在关联,此种潜在关联往往能够为行为预测提供关键的上下文信息;第三,分别训练目标检测网络和行为分类网络并不能保证找到全局最优,训练成本也比单阶段网络高,因此需要更长的时间和更多的内存。
技术实现思路
1、要解决的技术问题
2、为了避免现有技术的不足之处,本发明提出一种视频图像暴力行为检测模型及检测方法,采用双分支结构的骨干特征提取网络,一路专注于提取时空特征,一路专注于提取空间特征,两分支特征对于最终的目标行为定位具有互补作用,克服了两阶段方法只关注视频中人体区域特征的不足,表现出与现有最优方法相当的检测精度;同时,本发明采用轻量化结构和单阶段检测流程,可以端到端进行模型训练与预测,大幅度降低了训练成本,并具有更高的检测效率。
3、技术方案
4、一种视频图像暴力行为检测模型,其特征在于包括特征提取网络依次连接通道融合注意力模块和分类回归模块;所述特征提取网络为双分支骨干特征提取网络,其中i3d网络,进行时空特征提取,另一路为优化的repvgg网络,对关键帧进行空间特征提取;通道融合注意力模块强化得到的时空特征,得到两个尺度不同的有效特征层;以1×1卷积调整特征图通道数,输入分类器和回归器获得目标行为位置及其所属行为分类;所述优化的repvgg网络是将repvggblock4模块的输出的特征图作为aspp的输入,首先经过并行的卷积和空洞卷积操作进行特征提取;其次,将提取到的特征图进行合并;然后,对合并后的特征图进行1×1卷积,压缩特征,得到最终输出。
5、一种利用述视频图像暴力行为检测模型对监控视频中的暴力行为检测方法,其特征在于步骤如下:
6、步骤1、建立基础数据集:以m段暴力行为的视频图像作为视频数据,将每段视频切分为长度为16的图像帧序列作为基础数据集viodata;
7、步骤2、数据集标注:在切分得到的视频帧图像中,标注是否包含暴力行为以及发生暴力行为的位置;
8、步骤3、数据增强:将视频帧序列中的每幅图像做左右镜像处理,使训练集样本数扩充为原来的2倍;再随机改变扩充后图像rgb通道的亮度、对比度、饱和度来进行图像的色彩增强;
9、步骤4、检测模型训练:将步骤3的图像输入到视频图像暴力行为检测模型进行训练,得到暴力行为检测模型;
10、其中训练网络模型的损失函数包含:分类预测损失lcls、定位损失lrect以及置信度损失lobj;
11、所述分类预测损失公式:
12、
13、
14、其中,n代表行为类别总数,xi为类别预测值,yi为激活函数后得到的当前类别概率,y为当前类别真实值;
15、所述定位损失公式:
16、
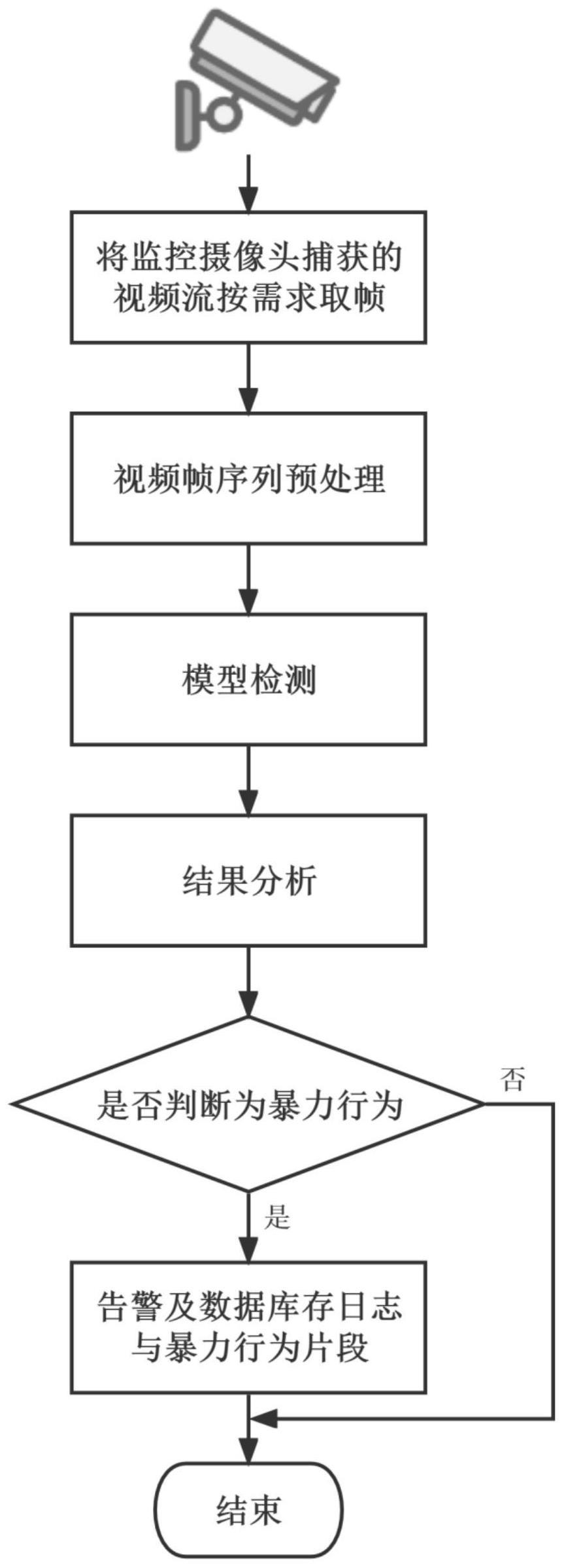
17、
18、
19、
20、其中,wgt和hgt表示真实框的宽和高,w和h表示预测框的宽和高,v表示预测框与真实框长宽比例差值的归一化,p2表示计算真实框与预测框之间的中心点距离,α是权衡长宽比例造成损失和iou造成损失的平衡因子;
21、所述置信度损失公式:
22、
23、
24、其中,n表示特征点数量,ci为置信度预测值,ci为激活函数后得到的当前置信度概率,c则为当前位置置信度真实值,有目标为1,无目标为0;
25、最后,将三个损失函数整合成一个总的损失函数,l=a1×lcls+a2×lrect+a3×lobj,其中,a1=0.4,a2=0.3,a3=0.3,当最小化该损失函数能使暴力行为检测模型收敛;
26、步骤5:将监控摄像头实时获取的视频数据切分成视频帧序列,并将一段段视频帧序列作为暴力行为检测模型的输入;然后进行模型前向推理,得到检测结果,当暴力行为预测的分类置信度大于0.5时,视为发生了暴力行为;一旦检测到暴力行为就进行告警,并做日志记录包括但不限于时间地点,一同将检测到的暴力行为片段和日志存到数据库中。
27、构建了基础数据集viodata,并对视频帧序列数据进行数据增强,执行暴力行为检测时将依次经过特征提取网络、通道融合注意力模块以及分类回归模块。
28、有益效果
29、本发明提出的一种视频图像暴力行为检测模型及检测方法,采用轻量化结构和单阶段检测流程。采用双分支骨干特征提取网络,一路使用改进的i3d网络专注于提取时空特征,一路通过优化的repvgg网络专注于提取关键帧的空间特征。通过通道融合注意力模块进一步强化骨干网络得到的时空特征,挖掘特征图各通道间的重要程度,得到两个尺度不同的有效特征层。通道剪枝加快模型推理速度。
30、本发明由于采用了双分支结构的骨干特征提取网络、合理的特征融合方法、轻量化结构以及单阶段的检测流程,能够从视频流中自动检测暴力行为,取得了较优异的效果,并将暴力行为检测模型部署到了嵌入式设备上,能够从监控摄像头获取的视频影像中,实时识别暴力行为并及时告警,验证了本发明在实际使用中的有效性。
- 还没有人留言评论。精彩留言会获得点赞!