基于多模态知识图谱的文本分类方法、设备及存储介质与流程
本发明涉及计算机,具体地涉及一种基于多模态知识图谱的文本分类方法、设备及存储介质。
背景技术:
1、目前,文本分类算法没有充分利用语音、视频和用户对食材的偏好、喜爱和评论数据等多模态数据的语义信息表示能力,导致文本分类效果不佳。而且,这些文本数据都是基于传统机器学习方法或机器学习与神经网络浅层特征信息相结合方法,这些方法容易出现泛化、数据理解能力不足、构建模型的鲁棒性较弱,进而影响文本分类能力不足。
2、因此,如何借助知识图谱构建多模态的文本分类方法成为文本分类准确率提高的关键技术。而智能冰箱交互离不开实时语音、视频和实时文本以及历史文本等多源异构数据,故针对所述多源异构数据如何基于多模态或跨模态数据实现最优的特征信息提取和文本分类,从而优化智能冰箱文本分类准确率,进而提升冰箱使用的体验效果。
技术实现思路
1、本发明的目的在于提供一种基于多模态知识图谱的文本分类方法、设备及存储介质。
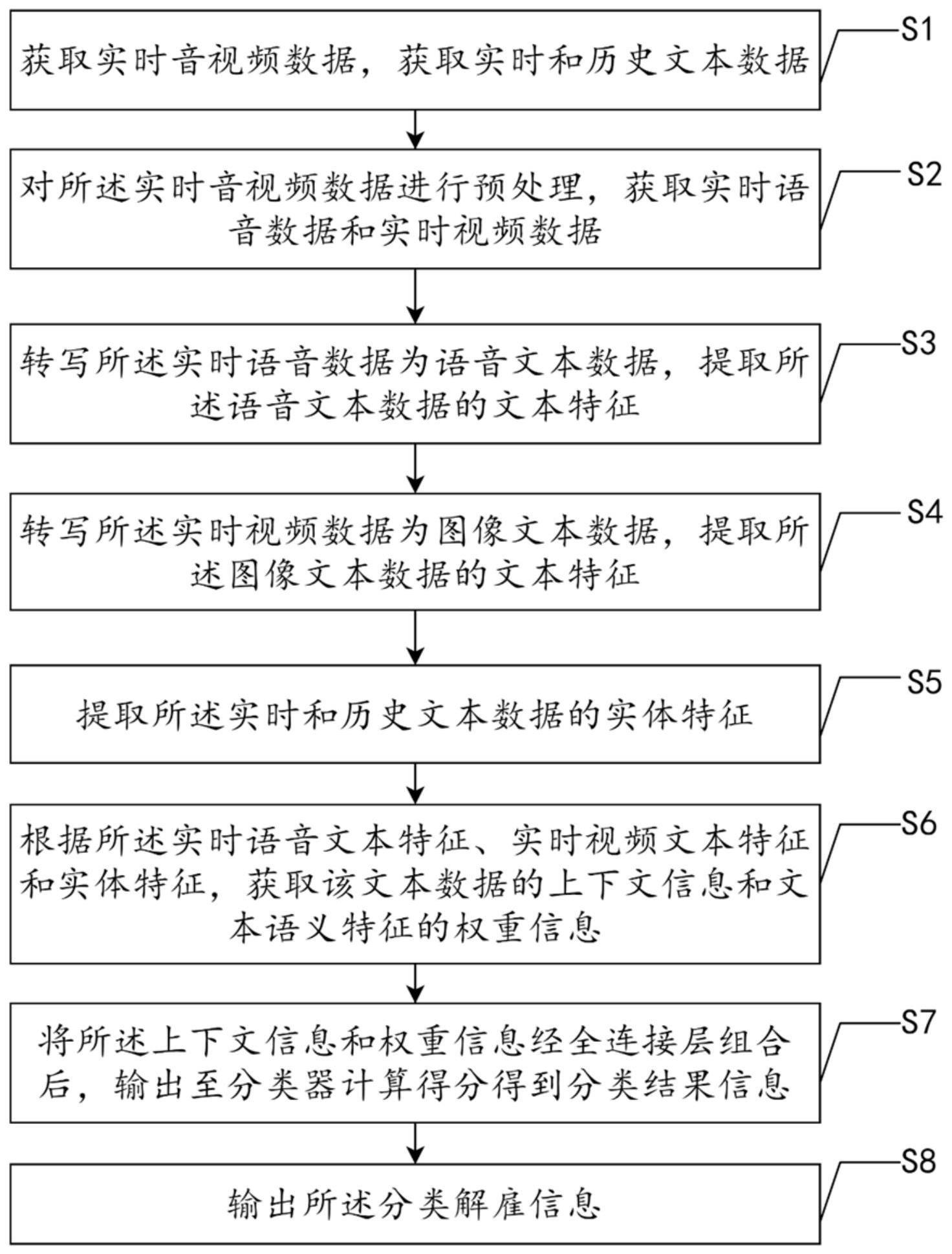
2、本发明提供种基于多模态知识图谱的生成文本分类方法,包括步骤:
3、获取实时音视频数据,获取实时和历史文本数据;对所述实时音视频数据进行预处理,获取实时语音数据和实时视频数据;转写所述实时语音数据为语音文本数据,提取所述语音文本数据的文本特征;转写所述实时视频数据为图像文本数据,提取所述图像文本数据的文本特征;提取所述实时和历史文本数据的实体特征;根据所述实时语音数据文本特征、实时视频数据文本特征和实体特征,获取该文本数据的上下文信息和文本语义特征的权重信息;将所述上下文信息和权重信息经全连接层组合后,输出至分类器计算得分得到分类结果信息;输出所述分类结果信息。
4、作为本发明的进一步改进,所述“对所述实时音视频数据进行预处理,获取实时语音数据和视频数据”,具体包括:对所述实时音视频数据进行数据清洗、格式解析、格式转换和数据存储,获得有效的音视频数据;采用脚本或第三方工具将所述有效音视频数据进行语音和视频分离,以获得所述实时语音数据和实时视频数据;对所述实时语音数据和视频数据进行预处理,包括:对所述实时语音数据进行分帧和加窗处理,对所述实时视频数据进行裁剪、分帧处理;对所述实时和历史文本数据进行预处理,包括:分词、去除停用词、去重复词。
5、作为本发明的进一步改进,所述“转写所述实时语音数据为语音文本数据”,具体包括:提取所述实时语音数据特征,得到语音特征;将所述语音特征输入语音识别多通道多尺寸深度卷积神经网络模型转写得到第一语音文本数据;基于连接时序分类方法输出所述语音特征和所述第一语音文本数据的对齐关系,以得到第二语音文本数据;基于注意力机制,获取所述第二语音文本数据的关键特征或所述关键特征的权重信息;将所述第二语音文本数据以及其关键特征或关键特征的权重信息经全连接层组合后,再经过分类函数计算得分得到所述语音文本数据。
6、作为本发明的进一步改进,所述“提取所述有效语音数据特征”,具体包括:提取所述有效语音数据特征,获取其梅尔频率倒谱系数特征。
7、作为本发明的进一步改进,所述“转写所述实时视频数据为图像文本数据”,具体包括:将所述实时视频数据输入3d深度卷积神经网络计算,得到图像特征;将所述图像特征输入多通道多尺寸时间卷积网络转写,获得第一图像文本数据;基于连接时序分类方法输出所述图像特征和所述第一图像文本数据的对齐关系,以得到第二图像文本数据;将所述第二图像文本数据经全连接层组合后,再经过分类函数计算得分得到所述图像文本数据。
8、作为本发明的进一步改进,所述“提取所述实时和历史文本数据的实体特征”,具体包括:采用实体链接方法对所述文本数据进行实体抽取,以得到多个食材实体;基于每个食材实体查询食材知识图谱,获得对应的实体向量表示;将所述实体向量表示输入多头注意力机制计算,得到实体特征向量。
9、作为本发明的进一步改进,所述“基于每个食材实体查询食材知识图谱,获得对应的实体向量表示”,具体包括:采用实体三元组形式将所述实体转换为对应的实体向量表示;采用神经网络的分布式向量表示方法来实现所述实体向量表示。
10、作为本发明的进一步改进,所述“根据所述实时语音数据文本特征、实时视频数据文本特征和实体特征,获取该文本数据的上下文信息和文本语义特征的权重信息”,具体包括:将所述实时语音文本特征和实时视频文本特征转换为语音文本词向量和图像文本词向量;将所述语音文本词向量、图像文本词向量和实体特征输入双向长短记忆网络模型,获取包含所述语音文本特征、图像文本特征和实时以及历史文本特征信息的上下文特征向量。
11、作为本发明的进一步改进,基于注意力机制,区分所述语音文本数据、图像文本数据和实时以及历史文本数据的文本特征中的词、词语的自身权重信息和/或关联权重信息,获得所述文本语义特征的权重信息。
12、作为本发明的进一步改进,所述“基于注意力机制,区分所述语音文本数据、图像文本数据和实时以及历史文本数据的文本特征中的词、词语的自身权重信息和或关联权重信息”,具体包括:分别将所述语音文本上下文特征向量、图像文本上下文特征向量和实时以及历史文本实体特征向量输入多头注意力机制;获取包含所述语音文本语义特征、图像文本语义特征和实时以及历史文本语义特征自身权重信息的自身权重文本注意力特征向量;获取包含所述语音文本语义特征、图像文本语义特征和实时以及历史文本语义特征关联权重信息的关联权重文本注意力特征向量。
13、作为本发明的进一步改进,所述“将所述上下文信息和权重信息经全连接层组合后,输出至分类器计算得分得到分类结果信息”,具体包括:将所述上下文特征向量和权重文本注意力特征向量经全连接层组合后,输出至分类函数,计算所述语音文本数据、图像文本数据和实时以及历史文本数据文本语义的得分及其归一化得分结果,得到文本的分类结果信息。
14、作为本发明的进一步改进,所述“输出所述分类结果信息”,具体包括:将所述分类结果信息转换为语音进行输出,和/或将所述分类结果信息转换为语音传输至客户终端输出,和/或将所述分类结果信息转换为文本进行输出,和/或将所述分类结果信息转换为文本传输至客户终端输出,和/或将所述分类结果信息转换为图像进行输出,和/或将所述分类结果信息转换为图像传输至客户终端输出。
15、作为本发明的进一步改进,所述“获取实时音视频数据,获取实时和历史文本数据”,具体包括:获取语音采集装置所采集的所述实时音视频数据,和/或获取自客户终端传输的所述实时音视频数据;获取文本采集装置所采集的所述实时文本数据,和/或获取自客户终端传输的所述实时文本数据;获取内部存储的所述历史文本数据,和/或获取外部存储的所述历史文本数据,和/或获取自客户终端传输的所述历史文本数据。
16、作为本发明的进一步改进,所述“转写所述语音数据为语音文本数据,提取所述语音文本数据的文本特征”,还包括:获取存储于外部缓存的配置数据,将所述语音数据基于所述配置数据执行所述多通道多尺寸深度卷积神经网络模型计算,进行文本转写和提取文本特征。
17、本发明还提供一种电器设备,包括:存储器,用于存储可执行指令;处理器,用于运行所述存储器存储的可执行指令时,实现上述的基于多模态知识图谱的生成文本分类方法。
18、本发明还提供一种冰箱,包括:存储器,用于存储可执行指令;处理器,用于运行所述存储器存储的可执行指令时,实现上述的基于多模态知识图谱的生成文本分类方法。
19、本发明还提供一种计算机可读存储介质,其存储有可执行指令,所述可执行指令被处理器执行时实现上述的基于多模态知识图谱的生成文本分类方法。
20、本发明的有益效果是:本发明所提供的方法完成了对所获取的文本数据进行识别与分类任务。首先通过引入实时语音、实时视频、实时文本、实时和历史用户对食材偏好、兴趣和历史评论数据等多模态数据,解决了单一模态数据的文本语义信息单一、数据理解不足等问题;其次,引入深度卷积神经网络模型弥补了传统机器学习方法的特征表征能力不足的现象,能更深层次的获得语义特征信息的关联性和互补性,加强语义特征,有效提高了文本分类准确度;最后,增加对多模态知识图谱的实体链接表示,提高文本语义特征信息的泛化能力,提升用户的体验效果。
- 还没有人留言评论。精彩留言会获得点赞!