搭建存储与计算分离的大数据平台的方法与流程
本技术涉及存储与计算分离的大数据平台,具体地涉及一种搭建存储与计算分离的大数据平台的方法。
背景技术:
1、大数据体系成形后,大数据相关的技术、产品、落地应用、科技成果及规范标准不断发展,大数据整体生态呈现出从技术到应用转向治理的趋势。大数据不再是仅仅对数据的采集、计算、存储、查询、管理的简单层次,人们也意识到对数据的科学性治理、打破数据之间的壁垒高墙,才能进一步充分挖掘与转化数据资源中所蕴含价值。
2、从大数据基础架构来看,起初的大数据集群是考虑到单台机器网络吞吐量和集群整体网络带宽上限,才将存储与计算进行耦合,比起通过网络传输大量数据到计算节点,将计算的代码移动到计算节点上更能减少网络带宽消耗,提高数据访问效率。但这种存储与计算的耦合方式是把计算资源和存储资源是按某一比例绑定在集群节点中,若要对大数据集群扩容则必须增加节点,会导致节点存储资源闲置而内存资源紧张或者内存资源闲置而存储资源紧张的情况。由于多数大数据集群采用hdfs进行存储,内置的多副本数据存储策略也会带来较高的存储成本和冗余,虽然hdfs中的balancer角色能起到在各个节点间保持数据存储平衡的作用,但是节点的内存和cpu利用率对比差距明显,部分节点计算资源在高峰时能高达90%,但有的节点的只能达到40-%50%甚至更低,造成严重的资源浪费。
3、随着通信技术的成熟和新型大数据组件的出现,网络的限制已不是主要问题,现有的开源组件无法直接做到存算分离,着手现有的大数据领域热门的组件与工具,搭建出一个统一的管理平台对存储集群和计算集群的资源进行管理、监控、维护,能为当前的存算分离提供一种快速、简便、架构清晰的存算分离大数据平台,能解决存储与计算一体架构带来的诸多问题。现有大数据平台管理工具通过ambari进行管理一套存储与计算一体的大数据集群,ambari中的服务组件多来自于hdp,但hdp3.1.5之后的组件已关闭开源无法获取,不仅现有的服务组件中提供的版本较低,组件存在占用额外资源的冗余结构,未能满足存算分离需求的功能,还缺少存储与计算分离架构中所需的必要组件,无法对集群进行快速扩缩容,离实现存储与计算分离的大数据平台还有很大的差距。
技术实现思路
1、本技术实施例的目的是提供一种搭建存储与计算分离的大数据平台的方法,用以解决现有技术中基于ambari的大数据平台无法直接构建存储与计算分离的大数据平台的问题。
2、为了实现上述目的,本技术第一方面提供一种搭建存储与计算分离的大数据平台的方法,应用于ambari平台,ambari平台与大数据平台通信,方法包括:
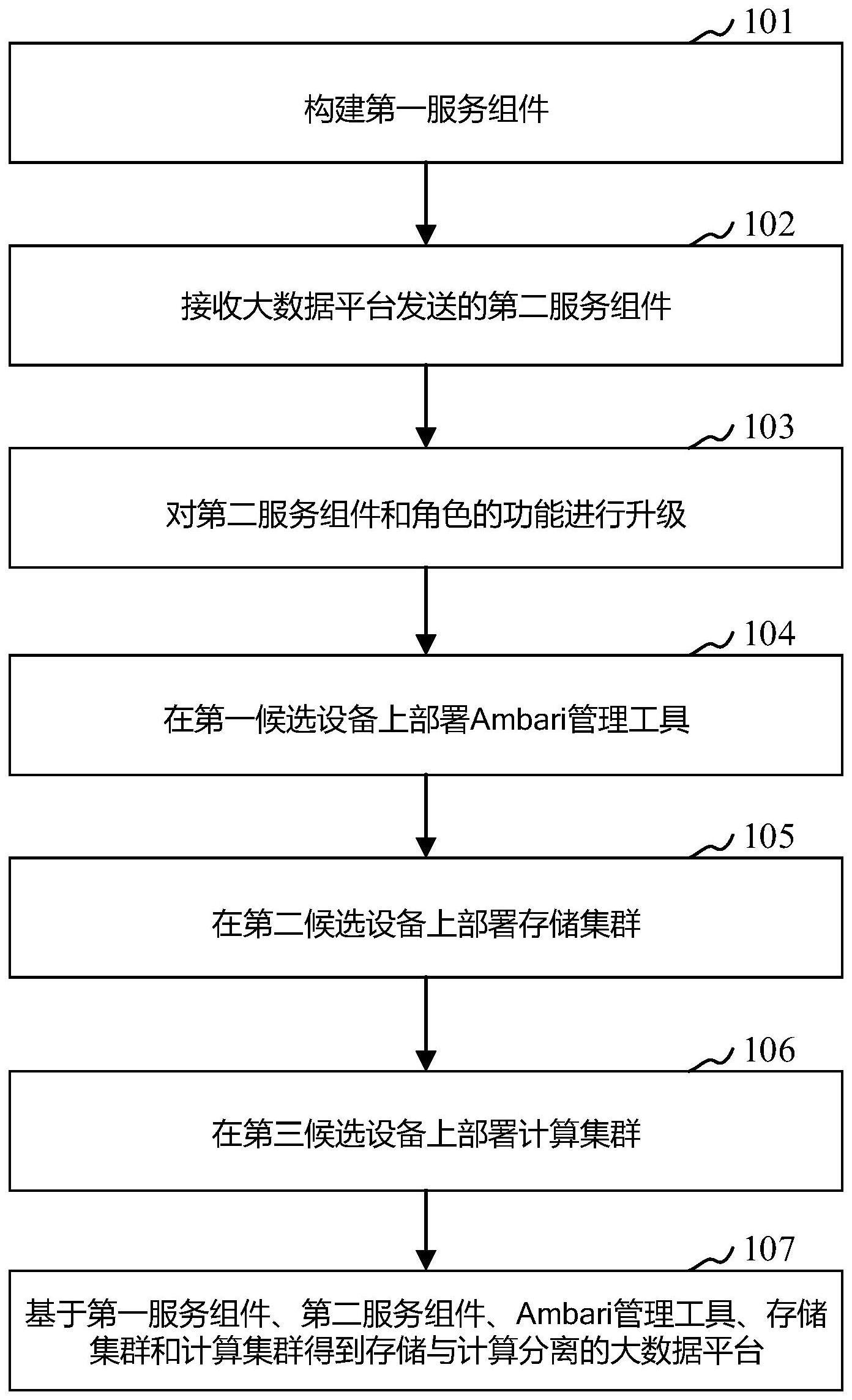
3、构建第一服务组件;
4、接收大数据平台发送的第二服务组件;
5、对第二服务组件和角色的功能进行升级;
6、在第一候选设备上部署ambari管理工具;
7、在第二候选设备上部署存储集群;
8、在第三候选设备上部署计算集群;
9、基于第一服务组件、第二服务组件、ambari管理工具、存储集群和计算集群得到存储与计算分离的大数据平台。
10、在本技术实施例中,第一服务组件包括对象存储服务组件minio和分布式文件系统组件juicefs。
11、在本技术实施例中,构建第一服务组件包括:
12、搭建与对象存储服务组件minio相关联的第一脚本;
13、搭建minio client角色;
14、搭建minio server node角色;
15、搭建链接文件信息;
16、基于第一脚本、minio client角色、minio server node角色、链接文件信息得到对象存储服务组件minio。
17、在本技术实施例中,构建第一服务组件还包括:
18、搭建与分布式文件系统组件juicefs相关联的第二脚本;
19、搭建juicefs client角色;
20、搭建juicefs mount node角色;
21、基于第二脚本、juicefs client角色、juicefs mount node角色得到分布式文件系统组件juicefs。
22、在本技术实施例中,第二服务组件包括:
23、第一版本的hadoop组件、第三版本的spark组件、hdfs组件、yarn组件、mapreduce组件、hive组件、tez组件和zookeeper组件。
24、在本技术实施例中,对第二服务组件和角色的功能进行升级还包括:
25、获取第一版本的hadoop组件的源码包;
26、修复第一版本的hadoop组件的源码包中所需要的补丁并进行编译以形成第二版本的hadoop组件;
27、将第二版本的hadoop组件中的第一版本的hadoop组件的jar包进行替换后将第二版本的hadoop组件以rpm包的格式打包;
28、修改hdfs组件、yarn组件和mapreduce组件中metainfo.xml的版本信息以完成第一版本的hadoop组件的升级。
29、在本技术实施例中,对第二服务组件和角色的功能进行升级包括:
30、获取第三版本的spark组件的源码包;
31、接收第二版本的hadoop组件的版本参数;
32、根据hadoop组件的版本参数对第三版本的spark组件的源码包进行编译以形成第四版本的spark组件;
33、配置文件路径信息后将第四版本的spark组件以rpm包的格式打包;
34、将第四版本的spark组件信息配置添加至stack_package,并根据spark2的相关信息搭建第四版本的spark组件的服务框架以完成第四版本的spark组件的升级。
35、在本技术实施例中,对第二服务组件和角色的功能进行升级还包括:
36、分别对hdfs组件、yarn组件和mapreduce组件进行特定补丁修复和升级以得到升级后的hdfs组件、yarn组件和mapreduce组件;
37、分别对升级后的hdfs组件、yarn组件和mapreduce组件进行编译打包。
38、移除升级后的hdfs组件中的name node角色、data node角色、secondarynamenode角色、zkfailover controller角色和journal node角色以完成hdfs组件、yarn组件和mapreduce组件的升级。
39、在本技术实施例中,ambari管理工具包括ambari server和ambari agent。
40、在本技术实施例中,在第二候选设备上部署存储集群包括:
41、允许管理节点通过安全外壳协议访问第二候选设备并开启免密安全外壳协议;
42、在web管理界面上添加新的主机并接收第二候选设备的主机名以作为待部署的存储节点;
43、在待部署的存储节点上获取ambari agent程序和对象存储服务组件minio的安装包并进行安装;
44、在待部署的存储节点上安装minio client角色和minio server node角色;
45、在配置对象存储服务组件minio集群每个存储节点所使用的磁盘路径、存储集群的访问键和密钥信息后启动minio server node角色以完成存储集群的部署。
46、在本技术实施例中,在第三候选设备上部署计算集群包括:
47、允许管理节点通过安全外壳协议访问第三候选设备并开启免密安全外壳协议;
48、在web管理界面上添加新的主机并接收第三候选设备的主机名以作为待部署的计算节点;
49、在待部署的计算节点上获取ambari agent程序、hadoop系列组件、spark3组件和分布式文件系统组件juicefs的安装包;
50、建立分布式文件系统组件juicefs的元数据信息的数据库;
51、在任意待部署的计算节点上通过元数据库的信息和对象存储信息建立分布式文件系统组件juicefs的文件系统;
52、在待部署的计算节点上安装hadoop client角色并修改core-site.xml中的相关配置以完成计算集群的部署。
53、本技术第二方面提供一种ambari平台,包括:
54、存储器,被配置成存储指令;以及
55、处理器,被配置成从所述存储器调用所述指令以及在执行所述指令时能够实现根据上述的搭建存储与计算分离的大数据平台的方法。
56、本技术第三方面提供一种机器可读存储介质,该机器可读存储介质上存储有指令,该指令用于使得机器执行根据上述的搭建存储与计算分离的大数据平台的方法。
57、通过上述技术方案,构建第一服务组件,接收大数据平台发送的第二服务组件并对第二服务组件和角色的功能进行升级。在第一候选设备上部署ambari管理工具,在第二候选设备上部署存储集群,在第三候选设备上部署计算集群。基于第一服务组件、第二服务组件、ambari管理工具、存储集群和计算集群得到存储与计算分离的大数据平台。本技术能大幅降低部署存储与计算分离的大数据平台的难度,同时节省了集群的服务成本和管理成本,提高了平台整体的运维效率和水平。
58、本技术实施例的其它特征和优点将在随后的具体实施方式部分予以详细说明。
- 还没有人留言评论。精彩留言会获得点赞!