一种营商政策系统的构建方案及系统的制作方法
本发明涉及信息处理分析,具体为一种营商政策系统的构建方案及系统。
背景技术:
1、工作流,是对工作流程及其各操作步骤之间业务规则的抽象、概括描述。工作流建模,即将工作流程中的工作如何前后组织在一起的逻辑和规则,在计算机中以恰当的模型表达并对其实施计算。工作流要解决的主要问题是:为实现某个业务目标,利用计算机在多个参与者之间按某种预定规则自动传递文档、信息或者任务。
2、大数据分析技术主要由五大步骤组成:选择平台操作系统、构建hadoop集群、数据整合和预处理、数据存储、数据挖掘和分析。其中hadoop是一个用于存储和处理大数据的开源框架,存储空间与处理效率高,适用于批处理操作。同时spark属于hadoop的改进型,适用于流式与交互式数据处理与查询,实时性强且交互性好。还有较为重要的一个环节便是数据挖掘,它的主要任务包括预测建模、关联分析、聚类分析、异常检测等。在这些步骤中,有三个关键技术贯通始终:虚拟化(提升存储空间与资源利用效率),mapreduce(为大数据平台提供并行处理的计算模型,更适用于集群平台高性能计算)和人工智能(辅助分析挖掘)。
3、数据仓库技术,数据仓库可分为:操作型数据库和分析型数据库。主要由四部分组成:各个数据源单独的数据库、数据仓库技术(etl)、数据仓库和前端应用。各类数据在数据仓库中整理归纳后方可更加快速精准地进行分析预测。
4、工作流能解决政策数据的业务流转和审批,但是对于新政策的指定并没有办法提供有效的参考和分析,无法对已有的政策进行提炼共性,辅助决策新政策的指定。同样的,大数据技术对于政策信息的采集是有帮助的,采集之后的政策可以按照聚类、去重、降噪等预处理,并进行海量大数据的存储入库,但是其缺乏对于政策数据的指标化管理和段逻辑分析,进而无法形成政策影响下的企业精准画像,没办法真正的评估政策的出台对于营商环境的改善效果。
技术实现思路
1、鉴于现有技术中所存在的问题,本发明公开了一种营商政策系统的构建方案及系统,具体包括:
2、一、算法建模,具体包括:
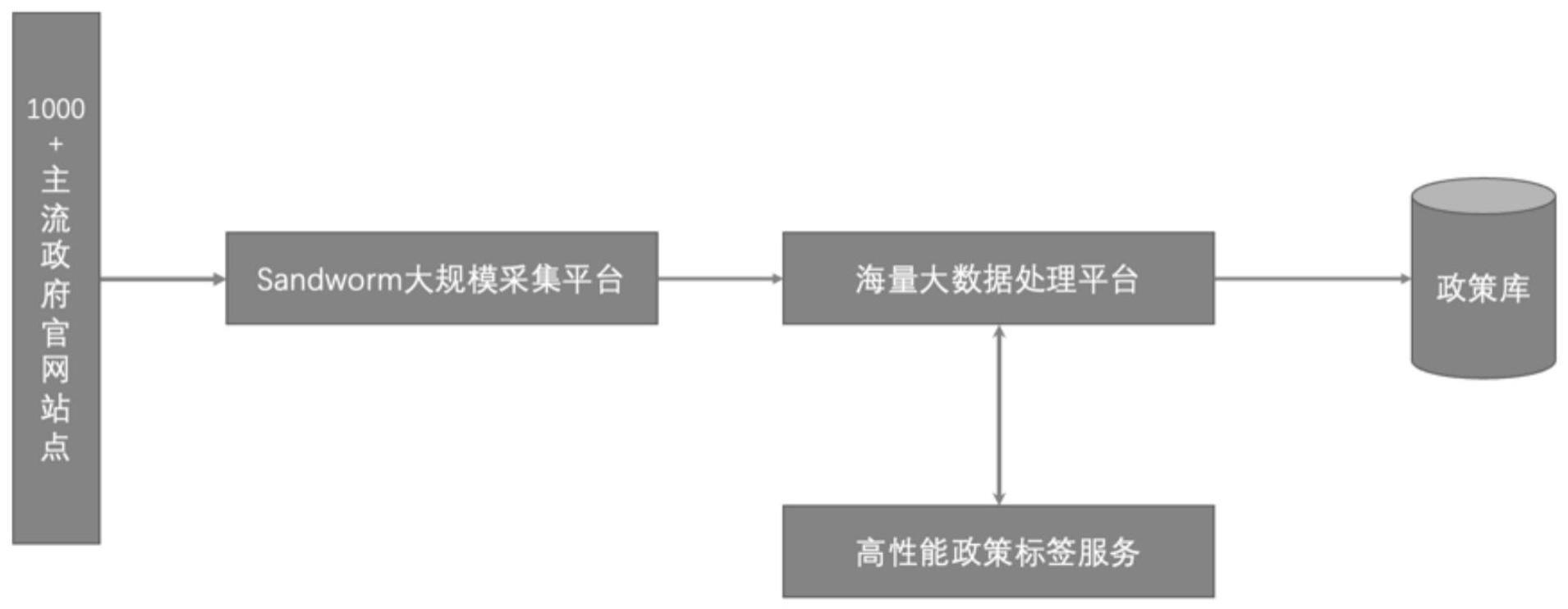
3、(1)、数据抽取:政策类站点及板块目前覆盖了26个省份、67个地级市,共122个政务网站,涉及的板块数多达3252个,覆盖了国内大部分主要政务网站的公开政策信息;资讯类站点及板块,也有74个主要政务资讯站点,涉及458个板块;在大量的采集数据语料的基础上,数据入库的时候会对数据进行数据预处理,包括对文本的分段、分句和词向量预训练;首先对政策资讯的原始文本数据进行分段分句操作,知识抽取模型训练的基础都以句子为单位处理,并剔除部分脏数据、短句;
4、(2)、通用模型抽取:使用现有的通用实体抽取模型抽取政务舆情数据中的实体,包括发文单位、发文时间、政策类型等;
5、(3)数据标注:确定标注规范,对通过通用实体抽取模型抽取的政策资讯数据进行标注,把标注的数据放入模型进行训练;目前数源政策分析系统,支持3级营商环境体系,其中一级指标有3个,包括政务环境、法务环境和市场环境;二级指标在一级类目基础上进行细分,例如开办企业、办理建筑许可等;三级指标是对二级指标进行再次细分,现有80多三级营商指标,就开办企业二级指标,就包括了开办企业环节、时间、成本、便利度等三级指标;
6、(4)、政策资讯分类模型训练:在数据标注的基础上,对词进行词向量预训练,将词以向量化形式标识;
7、(5)、政策影响力算法模型训练:在营商环境中,通过算法标注识别,可以得到政策一级营商指标,二级营商指标,三级营商指标;不同的营商环境指标,通过设置不同的权限比重来标识影响深度,通过全面的政策关键词标识政策影响广度,通过影响深度和影响广度的配置,加入到影响力模型训练中,提升政策影响力的准确性;计算模型算法,这里bm25相关度算法的基础上,结合影响深度和广度指标,对正文的数据进行影响力计算,计算公式:
8、
9、其中d是指政策资讯文本,q是指不同营商指标的关键词数据;k通过调整对应的权重比分,使得影响力比分结果;
10、(6)、生成模型:通过一系列模型训练和调优,得到业务使用的三个模型数据,包括通用模型、政策资讯分类模型、影响力评分模型,供后续的数据处理流程使用;
11、二、数据处理:营商政策数据的数据处理流程,包括数据预处理、实体抽取、关系抽取及后处理:
12、(1)、数据预处理:对输入的内容中出现的杂声进行过滤,过滤规则:根据内容去重、根据标题去除杂质、根据内容中时间出现次数去除杂志、根据命中关键字进行去重;
13、(2)、实体抽取:根据实体通用识别模型,识别内容中出现的政府部门、发文单位、一级营商指标、二级营商指标、三级营商指标,发布地,省级单位;
14、(3)、关系抽取:把实体识别抽取到的政府部门、发文单位、一级营商指标、二级营商指标、三级营商指标,发布地,省级单位,分别作为主语,与政策内容一起作为输入,抽取与该主语有关的谓语和宾语,形成三元组关系;
15、(4)、后处理:将营商环境知识图谱构建中获取大量的营商环境实体三元组数据,实现数据到政策知识的转化,并把这些数据存储到营商环境的知识图谱数据库neo4j中。
16、作为本发明的一种优选方案,所述词向量预训练利用word2vec进行,政策资讯分类利用站点算法、板块算法、链接算法对数据集进行模型训练。
17、本发明的有益效果:本发明基于大数据平台能力,获取国内政府网站全部公开政策资讯,多重组合算法区分政策和资讯信息,包括站点算法、板块算法、链接算法、索引算法,融合线下汇编政策,保障数据广度,同时,构建营商环境知识图谱,扩展营商环境政策库识别范围;另一方面,基于营商环境文本分析模型及知识图谱,识别分类实体隐性关系及关系的动态变化,精准识别、分类、分析政策,建立特有的政策影响力分析模型,从影响广度和影响深度2个方向进行深度分析。本发明利用知识图谱平台,训练6000多营商环境政策语料,输出含20000多实体,1000多关系及30000多三元组的营商领域知识图谱,用于营商环境政策库识别、段落标注,语料越多,训练时间越长,识别越准。
技术特征:
1.一种营商政策系统的构建方案及系统,其特征在于,具体包括:
2.根据权利要求1所述的一种营商政策系统的构建方案及系统,其特征在于:所述词向量预训练利用word2vec进行,政策资讯分类利用站点算法、板块算法、链接算法对数据集进行模型训练。
技术总结
本发明涉及一种营商政策系统的构建方案及系统。本发明基于大数据平台能力,获取国内政府网站全部公开政策资讯,多重组合算法区分政策和资讯信息,包括站点算法、板块算法、链接算法、索引算法,融合线下汇编政策,保障数据广度,同时,构建营商环境知识图谱,扩展营商环境政策库识别范围;另一方面,基于营商环境文本分析模型及知识图谱,识别分类实体隐性关系及关系的动态变化,精准识别、分类、分析政策,建立特有的政策影响力分析模型,从影响广度和影响深度2个方向进行深度分析。
技术研发人员:陈学言,田平,刘源
受保护的技术使用者:广东数源智汇科技有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!