特征提取器的训练方法、装置、设备和存储介质与流程
本发明涉及数据处理,特别是涉及一种特征提取器的训练方法、装置、设备和存储介质。
背景技术:
1、随着深度学习技术的发展,基于卷积神经网络的特征提取器的应用越来越广泛。
2、目前,在对特征提取器进行训练的过程中,将多个特征向量作为特征提取器的训练数据,进而对特征提取器进行迭代训练。然而,相关技术中训练完成的特征提取器存在准确性较低的问题,导致不能通过特征提取器提取具有判别性的特征向量。
技术实现思路
1、本发明实施例的目的在于提供一种特征提取器的训练方法、装置、设备和存储介质,解决现有技术中训练完成的特征提取器存在准确性较低的问题,导致不能通过特征提取器提取具有判别性的特征向量的技术问题。
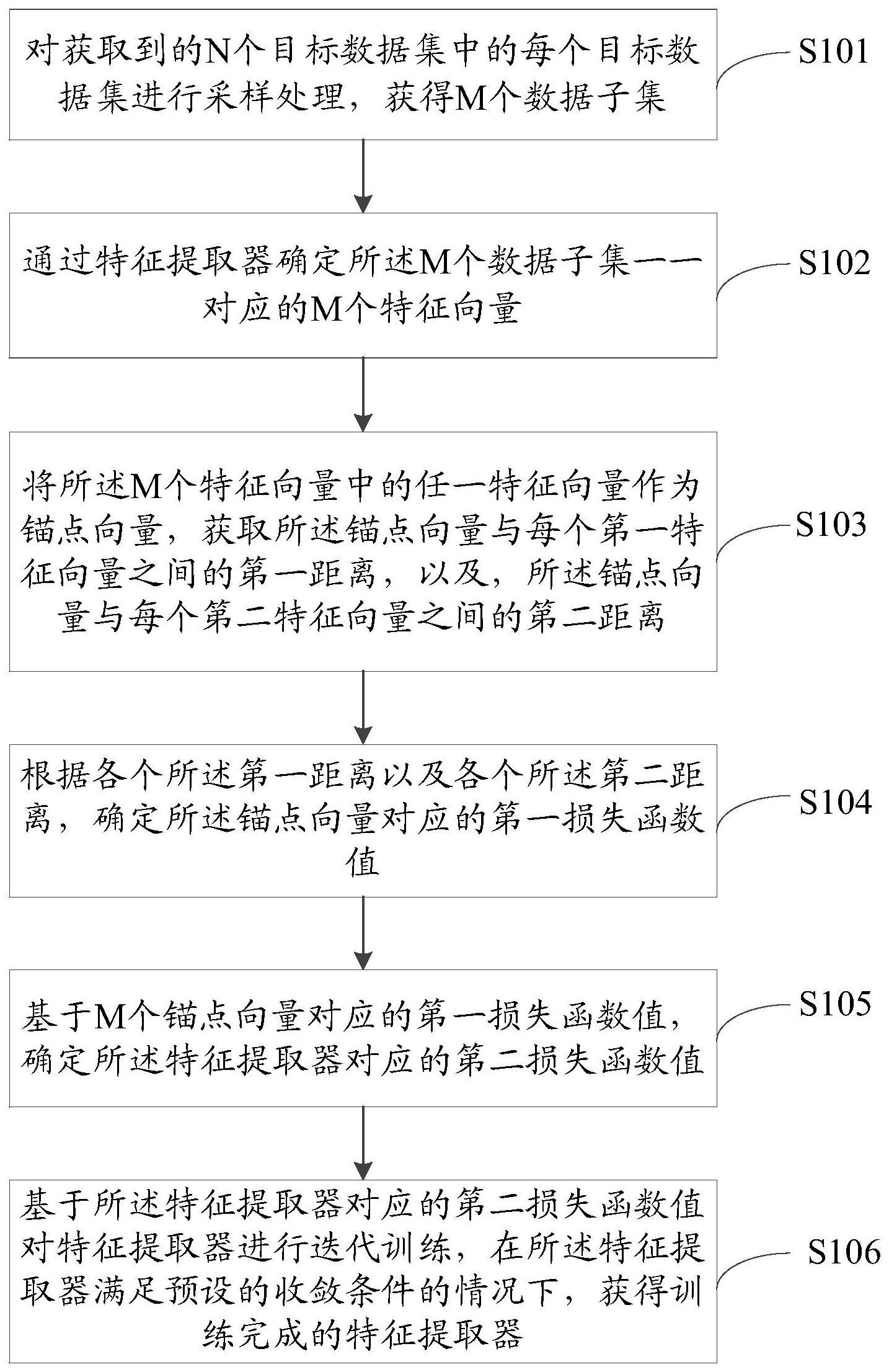
2、为了解决上述技术问题,第一方面,本发明实施例提供了一种特征提取器的训练方法,所述方法包括:
3、对获取到的n个目标数据集中的每个目标数据集进行采样处理,获得m个数据子集;n为大于1的正整数,m为大于或等于n的正整数;
4、通过特征提取器确定所述m个数据子集一一对应的m个特征向量;
5、将所述m个特征向量中的任一特征向量作为锚点向量,获取所述锚点向量与每个第一特征向量之间的第一距离,以及,所述锚点向量与每个第二特征向量之间的第二距离;所述第一特征向量为所述m个数据子集中与所述锚点向量对应的锚点数据子集属于同分布的数据子集对应的特征向量,所述第二特征向量为所述m个数据子集中与所述锚点向量对应的锚点数据子集属于异分布的数据子集对应的特征向量;
6、根据各个所述第一距离以及各个所述第二距离,确定所述锚点向量对应的第一损失函数值;
7、基于m个锚点向量对应的第一损失函数值,确定所述特征提取器对应的第二损失函数值;
8、基于所述特征提取器对应的第二损失函数值对特征提取器进行迭代训练,在所述特征提取器满足预设的收敛条件的情况下,获得训练完成的特征提取器。
9、可选地,所述根据各个所述第一距离以及各个所述第二距离,确定所述锚点向量对应的第一损失函数值包括:
10、根据各个所述第二距离,确定所述锚点向量与各个所述第二特征向量之间的距离之和;
11、根据各个所述第一距离以及所述距离之和,确定所述锚点向量对应的第一损失函数值。
12、可选地,所述根据各个所述第一距离以及各个所述第二距离,确定所述锚点向量对应的第一损失函数值包括:
13、获取所述各个所述第一距离中距离所述锚点向量最近的p个第一距离;p为正整数,且p小于所述锚点向量对应的锚点数据子集属于同分布的数据子集的数量;
14、根据所述p个第一距离以及各个所述第二距离,确定所述锚点向量对应的第一损失函数值。
15、可选地,所述根据各个所述第一距离以及各个所述第二距离,确定所述锚点向量对应的第一损失函数值包括:
16、获取基于近邻准则预先构建的损失模型;
17、将所述p个第一距离以及各个所述第二距离输入到所述损失模型进行处理,得到所述第一损失函数值。
18、可选地,所述对获取到的n个目标数据集中的每个目标数据集进行采样处理之前,所述方法还包括:
19、获取n个数据集;所述数据集包括特征变量和目标变量;
20、基于每个数据集包括的每个特征变量与每个目标变量之间的因果关系,删除所述每个数据集中与每个目标变量不存在因果关系的特征变量,获得n个目标数据集。
21、可选地,所述基于每个数据集包括的每个特征变量与每个目标变量之间的因果关系,删除所述每个数据集中与每个目标变量不存在因果关系的特征变量,包括:
22、对于所述n个数据集中的任一数据集,对所述数据集中的每个特征变量与每个目标变量进行因果关系分析,得到所述数据集对应的多个因果关系矩阵;所述因果关系矩阵用于表征所述数据集包括的每个特征变量与每个目标变量之间的因果关系;
23、基于所述数据集每个特征变量与每个目标变量之间的因果关系,获得目标因果关系矩阵;
24、基于所述目标因果关系矩阵,删除所述数据集中与目标变量不存在因果关系的特征变量,获得目标数据集。
25、可选地,所述对获取到的n个目标数据集中的每个目标数据集进行采样处理,获得m个数据子集包括:
26、对于所述n个目标数据集中的任一目标数据集,对所述目标数据集进行随机采样处理,获得采样处理结果;
27、根据所述采样处理结果,得到所述目标数据集对应的数据子集。
28、可选地,所述基于m个锚点向量对应的第一损失函数值,确定所述特征提取器对应的第二损失函数值包括:
29、基于m个锚点向量对应的第一损失函数值的和值,获得所述特征提取器对应的第二损失函数值。
30、可选地,所述方法还包括:
31、在所述特征提取器不满足预设的收敛条件的情况下,对获取到的n个目标数据集中的每个目标数据集重新进行采样处理,并基于采样结果重新计算所述特征提取器对应的第二损失函数值。
32、可选地,所述收敛条件包括以下至少一项:
33、所述特征提取器的迭代次数达到预设阈值;
34、所述特征提取器对应的第二损失函数值小于或等于预设损失函数值;
35、所述m个特征向量中任一锚点向量与所述锚点向量对应的任一第一特征向量之间的距离小于或等于预设距离。
36、第二方面,本发明实施例还提供了一种特征提取器的训练装置,包括:
37、第一处理模块,用于对获取到的n个目标数据集中的每个目标数据集进行采样处理,获得m个数据子集;n为大于1的正整数,m为大于或等于n的正整数;
38、第一确定模块,用于通过特征提取器确定所述m个数据子集一一对应的m个特征向量;
39、第二确定模块,用于将所述m个特征向量中的任一特征向量作为锚点向量,获取所述锚点向量与每个第一特征向量之间的第一距离,以及,所述锚点向量与每个第二特征向量之间的第二距离;所述第一特征向量为所述m个数据子集中与所述锚点向量对应的锚点数据子集属于同分布的数据子集对应的特征向量,所述第二特征向量为所述m个数据子集中与所述锚点向量对应的锚点数据子集属于异分布的数据子集对应的特征向量;
40、第三确定模块,用于基于m个锚点向量对应的第一损失函数值,确定所述特征提取器对应的第二损失函数值;
41、第四确定模块,用于基于m个锚点向量对应的第一损失函数值,确定所述特征提取器对应的第二损失函数值;
42、训练模块,用于基于所述特征提取器对应的第二损失函数值对特征提取器进行迭代训练,在所述特征提取器满足预设的收敛条件的情况下,获得训练完成的特征提取器。
43、可选地,所述第三确定模块,具体用于:
44、根据各个所述第二距离,确定所述锚点向量与各个所述第二特征向量之间的距离之和;
45、根据各个所述第一距离以及所述距离之和,确定所述锚点向量对应的第一损失函数值。
46、可选地,所述第三确定模块,还具体用于:
47、获取各个所述第一距离中距离所述锚点向量最近的p个第一距离;p为正整数,且p小于所述锚点向量对应的锚点数据子集属于同分布的数据子集的数量;
48、根据所述p个第一距离以及各个所述第二距离,确定所述锚点向量对应的第一损失函数值。
49、可选地,所述第三确定模块,还具体用于:
50、获取基于近邻准则预先构建的损失模型;
51、将所述p个第一距离以及各个所述第二距离输入到所述损失模型进行处理,得到所述第一损失函数值。
52、可选地,所述装置还包括:
53、获取模块,用于获取n个数据集;所述数据集包括特征变量和目标变量;
54、筛选模块,用于基于每个数据集包括的每个特征变量与每个目标变量之间的因果关系,删除所述每个数据集中与每个目标变量不存在因果关系的特征变量,获得n个目标数据集。
55、可选地,所述筛选模块,具体用于:
56、对于所述n个数据集中的任一数据集,对所述数据集中的每个特征变量与每个目标变量进行因果关系分析,得到所述数据集对应的多个因果关系矩阵;所述因果关系矩阵用于表征所述数据集包括的每个特征变量与每个目标变量之间的因果关系;
57、基于所述数据集每个特征变量与每个目标变量之间的因果关系,获得目标因果关系矩阵;
58、基于所述目标因果关系矩阵,删除所述数据集中与目标变量不存在因果关系的特征变量,获得目标数据集。
59、可选地,所述第一处理模块,具体用于:
60、对于所述n个目标数据集中的任一目标数据集,对所述目标数据集进行随机采样处理,获得采样处理结果;
61、根据所述采样处理结果,得到所述目标数据集对应的数据子集。
62、可选地,所述第四确定模块,具体用于:
63、基于m个锚点向量对应的第一损失函数值的和值,获得所述特征提取器对应的第二损失函数值。
64、可选地,所述装置还包括:
65、第二处理模块,用于在所述特征提取器不满足预设的收敛条件的情况下,对获取到的n个目标数据集中的每个目标数据集重新进行采样处理,并基于采样结果重新计算所述特征提取器对应的第二损失函数值。
66、可选地,所述收敛条件包括以下至少一项:
67、所述特征提取器的迭代次数达到预设阈值;
68、所述特征提取器对应的第二损失函数值小于或等于预设损失函数值;
69、所述m个特征向量中任一锚点向量与所述锚点向量对应的任一第一特征向量之间的距离小于或等于预设距离。
70、第三方面,本发明实施例还提供了一种电子设备,包括处理器、通信接口、存储器和通信总线,其中,处理器,通信接口,存储器通过通信总线完成相互间的通信;
71、存储器,用于存放计算机程序;
72、处理器,用于执行存储器上所存放的程序时,实现如上所述的特征提取器的训练方法。
73、第四方面,本发明实施例还提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时,实现如上所述的特征提取器的训练方法。
74、上述实施例提供的特征提取器的训练方法,在特征提取器的训练过程中,得到每个锚点向量与对应的第一特征向量之间的第一距离,其中,第一特征向量为与所述锚点向量对应的锚点数据子集属于同分布的数据子集对应的特征向量,以及该锚点向量与每个第二特征向量之间的第二距离,其中,所述第二特征向量为与所述锚点向量对应的锚点数据子集属于异分布的数据子集对应的特征向量,根据每个锚点对应的各个所述第一距离以及各个所述第二距离,获取函数损失值,进而基于该损失函数值调整特征提取器。本发明方案,通过每个锚点向量对应的第一距离,得到与锚点数据子集属于同分布的数据子集的特点,并且通过每个锚点向量对应的第二距离,得到将与锚点数据子集属于异分布的数据子集的特点。然后通过各个第一距离和各个第二距离对应的损失函数值对特征提取器进行迭代训练,实现将锚点数据子集属于同分布的数据子集的特征向量靠近锚点向量,而将锚点数据子集属于异分布的数据子集的特征向量远离锚点向量,基于本发明提供方案训练得到的特征提取器具有具有判别性,提高特征提取器提取到的特征向量的准确性。
75、另外,上述实施例通过分析数据集中特征变量和目标变量之间的因果关系,利用该因果关系对数据集进行处理,去除掉与目标变量无关的特征变量、伪相关的特征变量,能够提高用于特征提取器训练的目标数据集的数据质量,提高特征提取器训练速度,减少对系统资源的浪费。
- 还没有人留言评论。精彩留言会获得点赞!