相似用户预测方法、装置、设备及存储介质与流程
本申请涉及互联网,尤其涉及一种相似用户预测方法、装置、设备及存储介质。
背景技术:
1、相似用户预测,是指基于海量用户数据,从中发现或挖掘与特定用户或种子用户相似的用户,是随着互联网、大数据等技术的发展而衍生的新型数据处理模式。相似用户预测,是实现精准信息推送、精准广告推送以及感兴趣用户分析的重要处理内容。
2、目前的相似用户预测方案,通常是简单比对不同用户之间的特征数据,例如比如用户画像标签、用户特征等,实现相似用户的挖掘和预测。但是上述的方案对相似用户的预测准确度较低,通常无法准确把握用户相似性。
技术实现思路
1、基于上述技术现状,本申请提出一种相似用户预测方法、装置、设备及存储介质,能够提高相似用户预测的准确度。
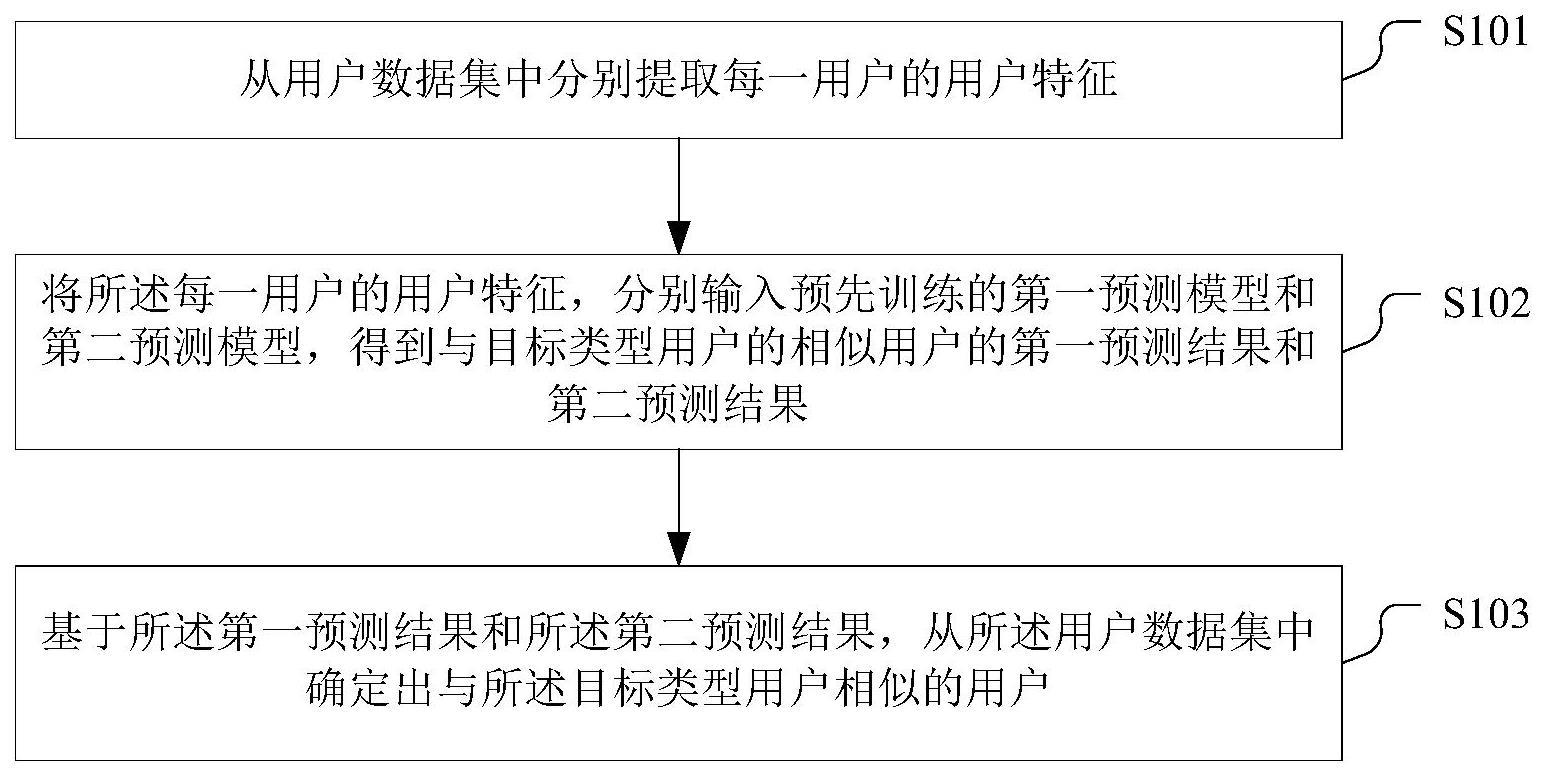
2、第一方面,本申请提出一种相似用户预测方法,包括:
3、从用户数据集中分别提取每一用户的用户特征,其中,所述用户数据集包括用户属性数据,以及用户执行特定行为的行为数据;
4、将所述每一用户的用户特征,分别输入预先训练的第一预测模型和第二预测模型,得到与目标类型用户的相似用户的第一预测结果和第二预测结果;其中,所述第一预测模型通过对线性的机器学习模型进行所述目标类型用户的相似用户预测训练得到,所述第二预测模型通过对非线性的机器学习模型进行所述目标类型用户的相似用户预测训练得到;
5、基于所述第一预测结果和所述第二预测结果,从所述用户数据集中确定出与所述目标类型用户相似的用户。
6、可选的,所述用户数据集包括用户属性数据,以及广告曝光数据,所述广告曝光数据包括用户浏览或点击广告的行为数据;
7、从用户数据集中分别提取每一用户的用户特征,包括:
8、从所述用户属性数据中分别提取每一用户的用户属性特征,以及,从所述广告曝光数据中提取每一用户的用户广告行为特征。
9、可选的,从所述广告曝光数据中提取每一用户的用户广告行为特征,包括:
10、根据广告曝光数据中用户浏览或点击广告的行为数据,确定用户在设定历史时间段内曝光过的广告的标识序列,以及广告所属活动的标识序列;
11、对用户在设定历史时间段内曝光过的广告的标识序列,以及广告所属活动的标识序列进行计数统计,得到用户广告行为特征。
12、可选的,基于所述第一预测结果和所述第二预测结果,从所述广告曝光数据中确定出与所述目标类型用户相似的用户,包括:
13、基于预先确定的第一模型权重和第二模型权重,对所述广告曝光数据中每一用户对应的第一预测结果和第二预测结果进行加权融合,得到融合预测结果;
14、根据每一用户对应的融合预测结果,从所述广告曝光数据中确定出与所述目标类型用户相似的用户。
15、可选的,用户对应的第一预测结果包括所述第一预测模型预测该用户与所述目标类型用户相似的置信度,用户对应的第二预测结果包括所述第二预测模型预测该用户与所述目标类型用户相似的置信度。
16、可选的,所述用户数据集包括用户属性数据,以及广告曝光数据,所述广告曝光数据包括用户浏览或点击广告的行为数据;
17、所述第一预测模型和所述第二预测模型的训练过程,包括:
18、基于目标类型用户的用户数据获取每一目标类型用户的用户特征,以及,从所述广告曝光数据中选择第一数量的第一类型用户,并提取每一第一类型用户的用户特征;所述第一类型用户为与所述目标类型用户不相似的用户;
19、将各个目标类型用户的用户特征以及各个第一类型用户的用户特征组成训练集,并利用所述训练集对所述第一预测模型和所述第二预测模型进行所述目标类型用户的相似用户预测训练。
20、可选的,所述第一预测模型和所述第二预测模型的训练过程,还包括:
21、从所述广告曝光数据中选择用户数据构成测试集;
22、将所述测试数据集中每一用户的用户特征,分别输入所述第一预测模型和所述第二预测模型,得到该用户与所述目标类型用户相似度的第一相似度预测结果和第二相似度预测结果;
23、根据预设的第一模型权重和第二模型权重,对所述第一相似度预测结果和第二相似度预测结果进行加权求和,得到相似度融合结果;
24、根据所述相似度融合结果,对所述第一模型权重和所述第二模型权重进行调整。
25、可选的,根据所述相似度融合结果,对所述第一模型权重和所述第二模型权重进行调整,包括:
26、根据所述相似度融合结果,确定对该用户的分类有效度,所述分类有效度表示区分该用户与所述目标类型用户是否相似的可信度;
27、以提高对该用户的分类有效度为目标,对所述第一模型权重和所述第二模型权重进行调整。
28、第二方面,本申请提出一种相似用户预测装置,包括:
29、特征提取单元,用于从用户数据集中分别提取每一用户的用户特征,其中,所述用户数据集包括用户属性数据,以及用户执行特定行为的行为数据;
30、第一预测处理单元,用于将所述每一用户的用户特征,分别输入预先训练的第一预测模型和第二预测模型,得到与目标类型用户的相似用户的第一预测结果和第二预测结果;其中,所述第一预测模型通过对线性的机器学习模型进行所述目标类型用户的相似用户预测训练得到,所述第二预测模型通过对非线性的机器学习模型进行所述目标类型用户的相似用户预测训练得到;
31、第二预测处理单元,用于基于所述第一预测结果和所述第二预测结果,从所述用户数据集中确定出与所述目标类型用户相似的用户。
32、第三方面,本申请提出一种电子设备,包括:
33、存储器和处理器;
34、所述存储器与所述处理器连接,用于存储程序;
35、所述处理器,用于通过运行所述存储器中的程序,实现上述的相似用户预测方法。
36、第四方面,本申请提出一种存储介质,所述存储介质上存储有计算机程序,所述计算机程序被处理器运行时,实现上述的相似用户预测方法。
37、本申请提出的相似用户预测方法,利用线性的第一预测模型和非线性的第二预测模型,分别根据用户数据集中的每一用户的用户特征,进行目标类型用户的相似用户的预测,得到第一预测结果和第二预测结果。然后再根据第一预测结果和第二预测结果,从用户数据集中确定出与目标类型用户相似的用户。
38、上述方案能够通过不同模型分别挖掘和度量用户数据集中的用户与目标类型用户的相似度,从而能够通过不同处理思路,更加全面、深入地把握用户特征和用户间的相似性,从而利于提供相似用户识别准确度。
39、另外,上述的线性模型和非线性模型的联合应用,使得方案整体上融合了线性模型和非线性模型各自的优点,即既能充分挖掘数据间的非线性关系,实现对大规模高维稀疏数据的有效处理,提高数据处理精细度,又能保持较好的可解释性,使得整体方案既具有较好的可解释性,又具有较高的准确度。
技术特征:
1.一种相似用户预测方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,所述用户数据集包括用户属性数据,以及广告曝光数据,所述广告曝光数据包括用户浏览或点击广告的行为数据;
3.根据权利要求2所述的方法,其特征在于,从所述广告曝光数据中提取每一用户的用户广告行为特征,包括:
4.根据权利要求1所述的方法,其特征在于,基于所述第一预测结果和所述第二预测结果,从所述广告曝光数据中确定出与所述目标类型用户相似的用户,包括:
5.根据权利要求4所述的方法,其特征在于,用户对应的第一预测结果包括所述第一预测模型预测该用户与所述目标类型用户相似的置信度,用户对应的第二预测结果包括所述第二预测模型预测该用户与所述目标类型用户相似的置信度。
6.根据权利要求1至5中任意一项所述的方法,其特征在于,所述用户数据集包括用户属性数据,以及广告曝光数据,所述广告曝光数据包括用户浏览或点击广告的行为数据;
7.根据权利要求6所述的方法,其特征在于,所述第一预测模型和所述第二预测模型的训练过程,还包括:
8.根据权利要求7所述的方法,其特征在于,根据所述相似度融合结果,对所述第一模型权重和所述第二模型权重进行调整,包括:
9.一种相似用户预测装置,其特征在于,包括:
10.一种电子设备,其特征在于,包括:
11.一种存储介质,其特征在于,所述存储介质上存储有计算机程序,所述计算机程序被处理器运行时,实现如权利要求1至8中任意一项所述的相似用户预测方法。
技术总结
本申请提出一种相似用户预测方法、装置、设备及存储介质,该方法包括:从用户数据集中分别提取每一用户的用户特征,其中,所述用户数据集包括用户属性数据,以及用户执行特定行为的行为数据;将所述每一用户的用户特征,分别输入预先训练的第一预测模型和第二预测模型,得到与目标类型用户的相似用户的第一预测结果和第二预测结果;基于所述第一预测结果和所述第二预测结果,从所述用户数据集中确定出与所述目标类型用户相似的用户。上述方案能够显著提高相似用户预测的准确度。
技术研发人员:曾忱,邵晔,贾超
受保护的技术使用者:科大讯飞股份有限公司
技术研发日:
技术公布日:2024/1/11
- 还没有人留言评论。精彩留言会获得点赞!