数据模态的自适应选择以用于高效视频识别的制作方法
背景技术:
1、本发明的实施例的领域一般涉及视频识别。
2、视频识别是基于机器学习(ml)的计算机视觉任务,其涉及获取、处理和分析来自诸如视频的视觉源的数据。多模态学习广泛用于视频识别。多模态学习利用各种数据模态来改进模型的性能。经由多模态学习训练的模型表示不同数据模态的联合表示。大多数传统的深度多模态模型集中于如何融合来自多个数据模态的信息。然而,利用多模态学习的传统视频识别解决方案在计算上是昂贵的,因为这些解决方案通常处理来自视觉源的所有数据,包括数据的冗余/不相关部分。例如,传统的解决方案可能分析表示不同数据模态(诸如rgb流和音频流)上的视频的多个数据流的整体,以识别在视频中执行的活动(即,动作)。然而,可能不必分析视频的所有视频段的多个数据流来识别在视频中执行的活动。需要提供一种自适应多模态学习框架,其通过基于输入在运行中选择对于视频的每个视频段的视频识别最佳的数据模态(即,对于每个视频段的不同数据模态的数据相关选择),来提高视频识别的效率(即,提高计算效率),显著节省计算(即,降低计算成本),以及提高视频识别的准确度(即,提高预测/分类的准确度/质量)。
技术实现思路
1、本发明的实施例一般涉及视频识别,并且更具体地,涉及一种用于数据模态的自适应选择以用于高效视频识别的方法和系统。
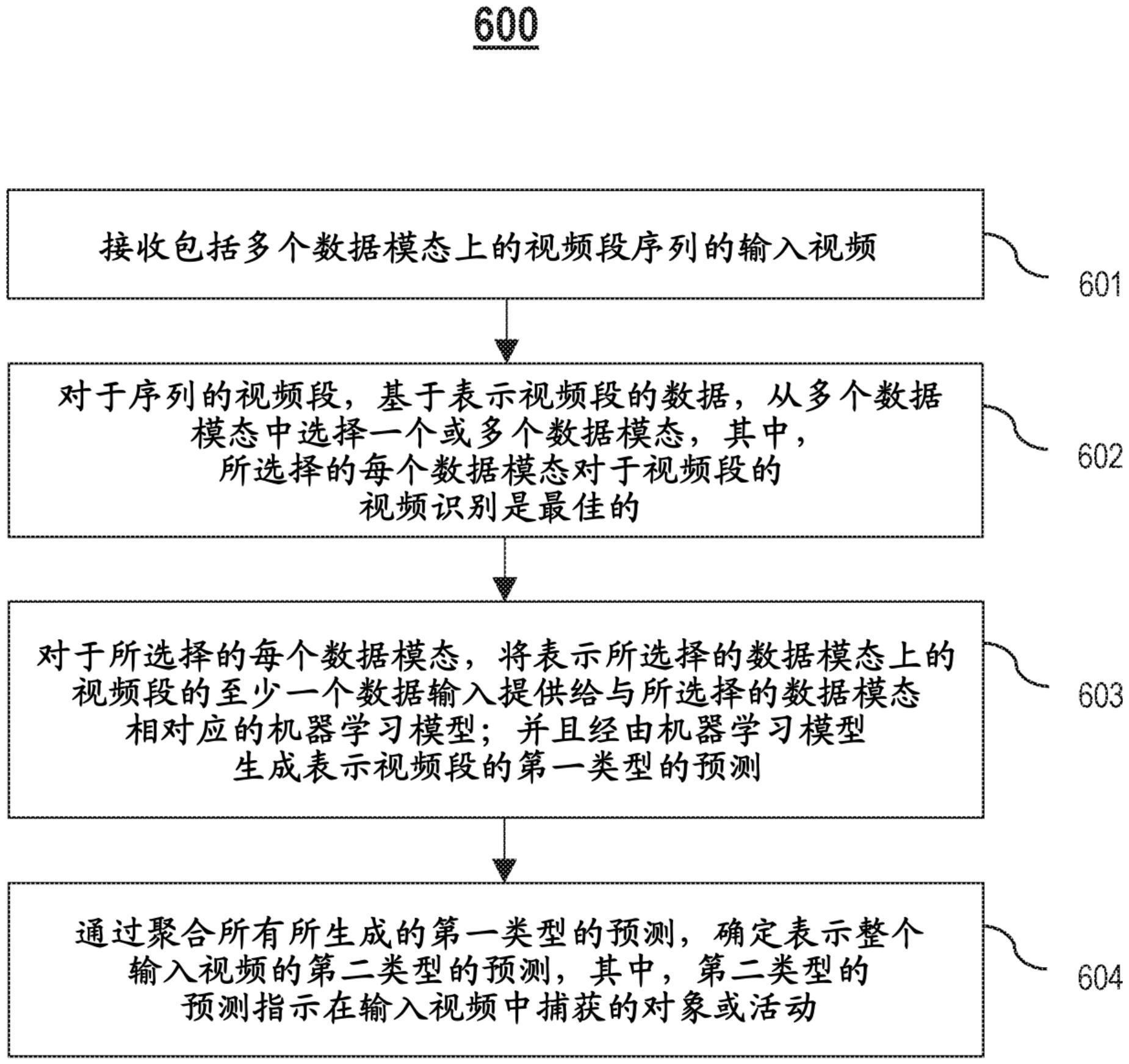
2、本发明的一个实施例提供了一种用于视频识别的方法。所述方法包括:接收包括多个数据模态上的视频段序列的输入视频。所述方法还包括:对于所述序列中的视频段,基于表示所述视频段的数据,从所述多个数据模态中选择一个或多个数据模态。所选择的每个数据模态对于所述视频段的视频识别是最佳的。所述方法还包括:对于所选择的每个数据模态,将表示所选择的数据模态上的所述视频段的至少一个数据输入提供给与所选择的数据模态相对应的机器学习模型,并且经由所述机器学习模型生成表示所述视频段的第一类型的预测。所述方法还包括:通过聚合所有所生成的第一类型的预测,确定表示整个输入视频的第二类型的预测。所述第二类型的预测指示在所述输入视频中捕获的对象或活动。其它实施例包括一种用于视频识别的系统和一种用于视频识别的计算机程序产品。这些特征有助于提供视频识别准确度与计算效率之间的最佳折衷的优点。
3、可以包括一个或多个以下特征。
4、在一些实施例中,所述多个数据模态中的每个数据模态具有对应的机器学习模型,所述对应的机器学习模型是与对应于所述多个数据模态中的一个或多个其他数据模态的一个或多个其他机器学习模型联合训练的。在一些实施例中,与所述多个数据模态中的每个数据模态相对应的每个机器学习模型包括子网络。这些可选特征有助于学习有利于选择在识别视频时在计算上更高效的数据模态的决策策略的优点。
5、本发明的实施例的这些和其它方面、特征和优点将参考附图和本文的详细描述来理解,并且将通过在所附权利要求中特别指出的各种元件和组合来实现。应当理解,本发明的附图的上述一般描述和以下简要描述以及实施例的详细描述都是本发明的优选实施例的示例和说明,而不是对所要求保护的本发明的实施例的限制。
技术特征:
1.一种用于视频识别的方法,包括:
2.根据权利要求1所述的方法,其中,所述多个数据模态包括rgb模态、光流量模态、以及音频模态中的至少一个。
3.根据权利要求1所述的方法,其中,表示所述视频段的所述数据包括以下项中的至少一项:一个或多个rgb帧、一个或多个rgb差分帧、以及一个或多个音频帧。
4.根据权利要求1所述的方法,其中,所述多个数据模态中的每个数据模态具有对应的机器学习模型,所述对应的机器学习模型是与对应于所述多个数据模态中的一个或多个其他数据模态的一个或多个其他机器学习模型联合训练的。
5.根据权利要求4所述的方法,其中,与所述多个数据模态中的每个数据模态相对应的每个机器学习模型包括子网络。
6.根据权利要求1所述的方法,其中,所选择的一个或多个数据模态提供视频识别准确度与计算效率之间的最佳折衷。
7.根据权利要求1所述的方法,还包括:
8.根据权利要求1所述的方法,其中,所述多个数据模态中的未被选择的每个数据模态对于所述视频段的所述视频识别是冗余的。
9.一种用于视频识别的系统,包括:
10.根据权利要求9所述的系统,其中,所述多个数据模态包括rgb模态、光流量模态、以及音频模态中的至少一个。
11.根据权利要求9所述的系统,其中,表示所述视频段的所述数据包括以下项中的至少一项:一个或多个rgb帧、一个或多个rgb差分帧、以及一个或多个音频帧。
12.根据权利要求9所述的系统,其中,所述多个数据模态中的每个数据模态具有对应的机器学习模型,所述对应的机器学习模型是与对应于所述多个数据模态中的一个或多个其他数据模态的一个或多个其他机器学习模型联合训练的。
13.根据权利要求12所述的系统,其中,与所述多个数据模态中的每个数据模态相对应的每个机器学习模型包括子网络。
14.根据权利要求9所述的系统,其中,所选择的一个或多个数据模态提供视频识别准确度与计算效率之间的最佳折衷。
15.根据权利要求9所述的系统,其中,所述指令还包括:
16.根据权利要求9所述的系统,其中,所述多个数据模态中的未被选择的每个数据模态对于所述视频段的所述视频识别是冗余的。
17.一种用于视频识别的计算机程序产品,所述计算机程序产品包括计算机可读存储介质,所述计算机可读存储介质存储程序指令,所述程序指令能够由处理器执行以使得所述处理器:
18.根据权利要求17所述的计算机程序产品,其中,所述多个数据模态包括rgb模态、光流量模态、以及音频模态中的至少一个。
19.根据权利要求17所述的计算机程序产品,其中,表示所述视频段的所述数据包括以下项中的至少一项:一个或多个rgb帧、一个或多个rgb差分帧、以及一个或多个音频帧。
20.根据权利要求17所述的计算机程序产品,其中,所述多个数据模态中的每个数据模态具有对应的机器学习模型,所述对应的机器学习模型是与对应于所述多个数据模态中的一个或多个其他数据模态的一个或多个其他机器学习模型联合训练的。
技术总结
提供了一种用于数据模态的自适应选择以进行高效视频识别的方法。该方法包括:接收包括多个数据模态上的视频段序列的输入视频。该方法还包括:对于序列中的视频段,基于表示视频段的数据,选择一个或多个数据模态。所选择的每个数据模态对于视频段的视频识别是最佳的。该方法还包括:对于所选择的每个数据模态,将表示所选择的数据模态上的视频段的至少一个数据输入提供给与所选择的数据模态相对应的机器学习模型,并且经由机器学习模型生成表示视频段的第一类型的预测。该方法还包括:通过聚合所有所生成的第一类型的预测,确定表示整个输入视频的第二类型的预测。
技术研发人员:R·潘达,陈均富,范权福,R·S·菲利斯
受保护的技术使用者:国际商业机器公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!