座舱内监测方法及相关姿势模式分类方法与流程
本发明涉及一种姿势模式分类方法以及一种座舱内监测方法。
背景技术:
1、us 2017/0 046 568 a1披露了通过使用与身体运动相关的帧的时间序列来进行手势识别。
2、us 9 904 845 b2和us 9 165 199 b2讨论了作为姿势估计的基础的3d图像。
3、us 9 690 982 b2披露了考虑人体关键点或身体部位之间的角度和欧几里得距离以进行手势检测。通过经训练的机器学习模型基于预定义规则来推断输入手势数据的类别。输入手势数据取决于与身体运动相关联的连续帧。
4、us 2020/0 105 014 a1还披露了通过经训练的机器学习模型基于预定义规则来推断输入姿势数据的类别。
5、us 10 783 360 b1披露了通过基于处理连续帧的座舱内监测来检测车辆操作者的手势。
技术实现思路
1、本发明的目的在于提供用于姿势分类的改进的方法和系统。
2、该目的通过独立权利要求的主题来实现。优选实施例是从属权利要求的主题。
3、本发明提供了一种用于实时检测受试者的输出感兴趣姿势的计算机实施的方法,优选地该受试者位于车辆座舱内部或位于车辆的周围环境中,该方法包括:
4、a)使用成像装置录制该受试者的至少一个图像帧;
5、b)通过使用机器学习模型处理该图像帧来确定输出感兴趣姿势,该机器学习模型包括基于规则的姿势推断模型和数据驱动的姿势推断模型:
6、-利用该数据驱动的姿势推断模型,通过处理该受试者的单个图像帧来确定数据驱动的感兴趣姿势;并且
7、-利用该基于规则的姿势推断模型,通过处理该相同的单个图像帧来确定基于规则的输出感兴趣姿势;以及
8、c)如果该基于规则的姿势推断模型能够在步骤b)中确定该基于规则的输出感兴趣姿势,则将该基于规则的输出感兴趣姿势确定为该输出感兴趣姿势,否则将该数据驱动的感兴趣姿势确定为该输出感兴趣姿势。
9、优选地,在步骤b)中,从该图像帧中提取多个人体关键点,并由该机器学习模型对这些人体关键点进行处理。
10、优选地,在步骤b)中,通过以下方式来确定该数据驱动的感兴趣姿势:确定至少一个预定感兴趣姿势中的每一个的概率分数,并输出在这些预定感兴趣姿势中具有最高概率得分的姿势作为该数据驱动的感兴趣姿势。
11、优选地,在步骤b)中,通过以下方式来确定该基于规则的感兴趣姿势:将姿势描述符数据与唯一地定义预定感兴趣姿势的至少一组姿势描述符进行比较,并且输出在这些预定感兴趣姿势中与该姿势描述符数据相匹配的姿势作为该基于规则的感兴趣姿势,或者如果该姿势描述符数据不与任何预定感兴趣姿势的任何姿势描述符相匹配,则输出未找到匹配。
12、优选地,通过从该图像帧中提取多个人体关键点来获得该姿势描述符数据,并且根据这些人体关键点来确定欧几里得距离和角度中的至少一个。
13、优选地,在步骤c)中,通过对加权的基于规则的感兴趣姿势与该数据驱动的感兴趣姿势进行求和来确定该输出感兴趣姿势,其中,被确定为在该图像帧中的该基于规则的感兴趣姿势的权重被设置为1,并且该数据驱动的感兴趣姿势的权重被设置为0。
14、优选地,在步骤c)中,如果关于该图像帧中存在预定感兴趣姿势的确定性低于预定阈值,则没有输出感兴趣姿势被确定。
15、优选地,该方法包括以下步骤:
16、d)利用控制单元,基于步骤c)中确定的该输出感兴趣姿势来生成控制信号,该控制信号适于控制车辆。
17、优选地,在步骤a)中,录制来自车辆座舱内部的受试者和/或来自车辆周围环境中的受试者的该图像帧。
18、本发明提供了一种用于监测车辆座舱内部的受试者(优选为车辆驾驶员)的座舱内监测方法,该方法包括执行优选方法,其中,成像装置被布置为对车辆座舱内部的受试者进行成像,并且预定感兴趣姿势被选择为指示驾驶员异常行为。
19、本发明提供了一种用于监测存在于车辆周围的受试者的车辆环境监测方法,该方法包括执行优选方法,其中,成像装置被布置为对车辆周围环境中的受试者进行成像,并且预定感兴趣姿势被选择为指示行人行为。
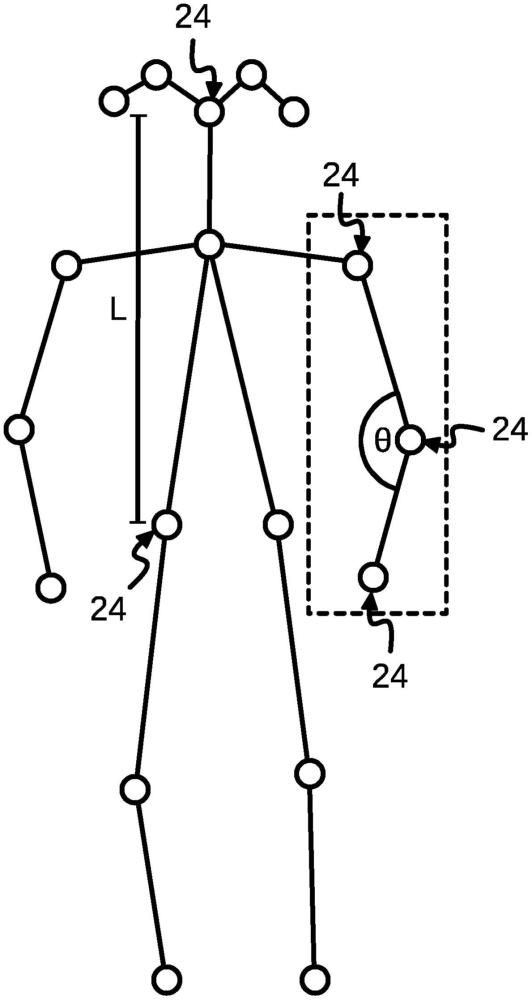
20、本发明提供了一种被配置用于执行优选方法的姿势分类系统,该姿势分类系统包括成像装置和姿势表征装置,该成像装置被配置用于录制受试者的图像帧,该姿势表征装置被配置用于从单个图像帧中确定输出感兴趣姿势,其中,该姿势分类装置包括数据驱动的姿势推断模型和基于规则的姿势推断模型,该数据驱动的姿势推断模型被配置用于通过处理受试者的单个图像帧来确定数据驱动的感兴趣姿势,该基于规则的姿势推断模型被配置用于通过处理相同的图像帧来确定基于规则的输出感兴趣姿势,其中,该姿势分类装置被配置用于:如果基于规则的姿势推断模型能够确定基于规则的输出感兴趣姿势,则将基于规则的输出感兴趣姿势确定为输出感兴趣姿势,否则将数据驱动的感兴趣姿势确定为输出感兴趣姿势。
21、本发明提供了一种包括姿势分类系统的车辆。
22、本发明提供了一种计算机程序、或计算机可读存储介质、或包括指令的数据信号,其在由数据处理装置执行时使得该装置执行优选方法的一个、一些或所有步骤。
23、所披露的端到端姿势模式分类通常具有三个阶段:
24、1)离线模型构建阶段;
25、2)在线推断阶段;以及
26、3)模型改进和优化阶段。
27、根据检测到的人体关键点的x和y坐标信息,
28、可以经由三角函数计算任意3点内的特定角度,以及任意2点之间的欧几里得距离,例如可以计算出右肩、肘部和手腕(关键点6、8和10)之间的右肘角度θ以及人或驾驶员的鼻子与左侧髋部(关键点0和11)之间的欧几里得距离l。因此,可以根据特定用例提取和预定义人体姿势模式的特征分量。例如,如果一个人躺在地上,那么颈部、髋部和膝盖之间的角度应该大于预定义的可配置阈值,例如150度;如果一个人坐在座位上,那么他的肩膀与膝盖之间的距离应该小于他站立时的距离等。这些规则(站立、坐着、睡觉等)可以在稍后的分类过程中加以考虑。
29、关键点的坐标x和y是人体姿势模式分量的另一部分。在内部相机捕获到车辆中的驾驶员的视频图像的场景中,可以使用驾驶员的关键点来定义和推断姿势模式,如手握/松开方向盘、头靠方向盘等。因此,可以相应地预定义、训练和推断驾驶员异常行为。整个过程包括以下关键步骤:
30、1.通常通过在真实场景中录制具有目标感兴趣姿势(poi)的视频来收集数据。
31、2.通过利用计算机视觉和深度学习技术识别和提取预定义的人体关键点坐标来提取人体关键点。
32、3.使用监督机器学习方法基于经处理和公式化的数据来训练模型。
33、代替仅依赖于基于规则的方法来对目标模式类别进行分类,本文呈现的解决方案结合了预定义规则(角度和距离等)和数据驱动方法,这些规则和方法应用图像上人体关键点的相对位置来训练机器学习模型(ml模型)并推断类别输出。
34、1)ml模型的训练是基于各种监督机器学习技术通过向模型馈送大量数据来完成的,这些监督机器学习技术包括但不限于基于树的、基于距离的建模、mlp和灵活堆叠在一起的技术。
35、可以计算不同人体关键点之间的特定多个角度θ=(θ1,θ2,…,θn)和欧几里得距离l=(l1,l2,…,ln),并将其作为单独的特征包括在训练结构表格数据集中。可以指配可配置且灵活的权重来表示该特征的重要性,从而可以训练与身体关键点相对位置和隐藏姿势模式的知识相结合的综合模型。
36、2)通过考虑预定义规则和数据驱动的模型预测的组合来推断类别输出。
37、该模型的工作原理如下:
38、定义类别总数c=(c1,c2,…,cn),每个类别的权重w=(w1,w2,…,wn),模型的预测p=(p1,p2,…,pn),以及每个类别的预定义规则:fn(θ,l)。
39、因此,每个类别的权重被定义为
40、
41、整体输出t定义如下
42、tn=w1c1+w2c2+…+wncn+(1-w1)(1-w2)…(1-wn)pn
43、这意味着当条件θ,l满足第n类别cn的定义时,无论模型预测如何,整体类别输出tn将仅取第n类别cn,否则无论预定义规则如何,来自模型的预测都将主导整体类别输出,例如首先将姿势模式“睡觉”的规则定义为颈部、髋部和膝盖之间的角度θ大于150度,如果满足要求,则无论模型预测如何,姿势的输出都将是“睡觉”,否则将预测作为类别输出。
44、实时推断任务应用经训练的模型来相应地分类和检测感兴趣姿势(poi)。对于每个输入帧,都会有一个预测类别及其用于表示置信水平的概率得分,这有助于优化模型。
45、该模型根据特定用例具有自适应性和灵活性,这意味着训练不同的模型来求解不同场景中的姿势模式分类问题,在评估步骤结束时,可以引入更多的特征工程方法和技术来提高和优化准确性以实现更好的性能。
46、有利地,这种解决方案不需要特殊的深度传感器,允许更容易的模型构建,提高了目标姿势类别定义的灵活性,可以直接集成到任何系统中,并且基于与输入训练数据的更好协调提高了准确性。
- 还没有人留言评论。精彩留言会获得点赞!