具有自训练分类的无监督异常检测的制作方法
背景技术:
1、神经网络是机器学习模型,该机器学习模型包括一个或多个非线性操作层以预测接收输入的输出。除了输入层和输出层之外,一些神经网络还包括一个或多个隐藏层。每个隐藏层的输出可以被输入到神经网络的另一隐藏层或输出层。神经网络的每个层可以根据该层的一个或多个模型参数的值从接收输入生成相应的输出。模型参数可以是通过训练算法所确定的权重或偏置,以使得神经网络生成精确的输出。深度神经网络包括多个隐蔽层。浅层神经网络具有一个或零个隐蔽层。
2、异常检测是将异常与正常数据区分开的任务,通常使用机器学习模型。异常检测应用于各种不同的领域中,诸如应用于制造中以检测制成品中的故障;应用于财务分析中以监视金融交易的潜在欺诈活动;以及应用于健康护理数据分析中以识别患者的疾病或其它有害状况。
技术实现思路
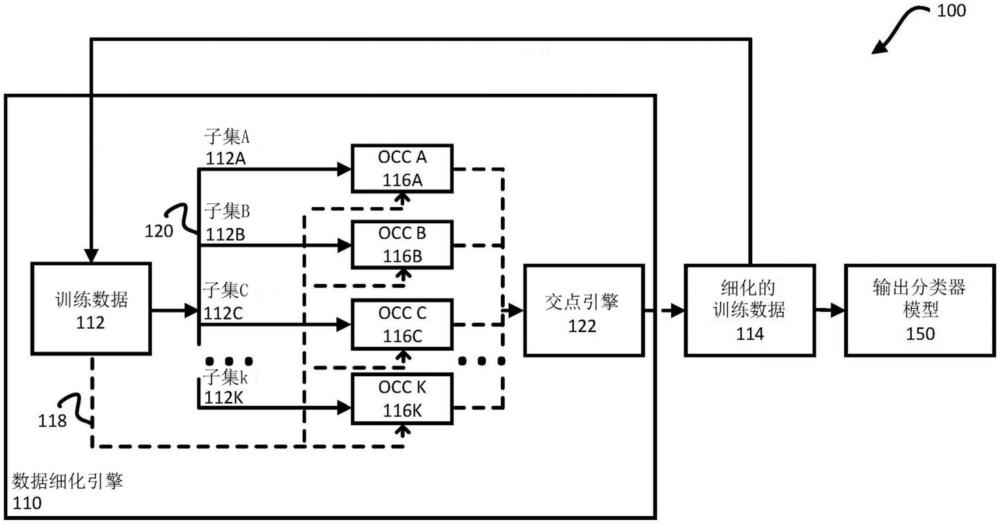
1、本公开各方面提供了一种仅使用未标记的训练数据以自监督方式被训练用于异常检测的机器学习模型框架。本公开各方面还提供了一种用于仅使用未标记的训练数据来训练机器学习模型框架以进行异常检测的方法。如本文中描述的自训练一类分类器(stoc)可以被训练为在输入数据上精确地进行异常检测,同时仅在未标记的训练数据上被训练。stoc可以接收正常和异常数据两者的未标记示例的原始训练数据或学习的表示,并且细化训练数据以生成至少部分地移除预测的异常示例的细化的训练数据集。可以使用细化的训练数据来训练stoc,以预测推理时的输入数据是正常还是异常的。
2、本公开一方面提供了一种一个或多个处理器的系统,该一个或多个处理器被配置为:接收未标记的训练数据,该未标记的训练数据包括多个训练示例;使用多个第一机器学习模型将训练示例中的每个训练示例分类为异常训练示例或非异常训练示例;生成细化的训练数据集,该细化的训练数据集包括被分类为非异常训练示例的训练示例;以及使用细化的训练数据集来训练第二机器学习模型,以接收输入数据并且生成指示输入数据是异常还是非异常的输出数据。
3、异常检测或者(通常较不频繁的)区分异常和正常样本是具有广泛应用的高度影响力的问题,诸如在制造中使用视觉传感器来检测故障产品、在信用卡交易处的欺骗行为,以及在重症监护室处的对抗性结果。异常检测经常受到标记的训练数据的可用性的限制,限制了开发和构建被训练用于异常检测的系统的方式。与限于标记的训练示例的方法相比,通过首先通过分类来细化数据,本公开各方面使得能够可行地使用大的未标记的训练数据。进而,本公开各方面提供了用于进行异常检测的更精确的系统,至少因为系统提供了使用更丰富的可用未标记训练数据。
4、本公开其它方面包括方法、装置以及存储用于一个或多个计算机程序的指令的非暂时性计算机可读存储介质,当该指令被执行时,该指令使得一个或多个处理器进行方法的动作。
5、前述和其它方面可以包括单独或组合的一个或多个以下特征。
6、未标记的训练数据可以包括一个或多个异常训练示例以及一个或多个非异常训练示例。
7、非异常训练示例的数量可以大于异常训练示例的数量。未标记的训练可以包括异常和非异常训练示例的混合,而不需要哪些示例属于哪个类别的先验知识。结果,如细化数据中描述的系统的使用更加灵活,因为提供的数据的假设相对于训练示例被标记的其它方法更加放松。此外,系统可以扩展异常检测应用的边界,其中,标记是昂贵或不完全精确的。
8、由一个或多个处理器进行的方法或操作还可以包括使用细化的训练数据集来训练多个第一机器学习模型。由一个或多个处理器进行的方法或操作还可以包括进行以下的附加迭代:使用多个第一机器学习模型对训练示例中的每个训练示例进行分类;以及基于附加迭代来更新细化的训练数据集。
9、本公开各方面提供了一种半监督系统,其中,细化的训练数据的迭代用于训练和精调一个或多个第一机器学习模型,以用于改进训练数据集的细化,从而排除异常训练示例。该迭代方法可以整体地改进系统的精度,因为系统被迭代地更新以适应可能对训练数据集唯一的异常训练示例的细微差别。与训练数据被分类用于在一次迭代中识别异常/非异常训练示例的方法相反,如本文中描述的迭代方法提供了校正系统以从非异常训练示例中更精确地细化异常训练示例的机会。
10、由一个或多个处理器进行的方法或操作还可以包括使用细化的训练数据集来训练第三机器学习模型,其中,第三机器学习模型被训练为接收训练示例,并且为接收到的训练示例中的每个训练示例生成一个或多个相应特征值;以及当使用多个第一机器学习模型对未标记的训练数据进行分类时,包括使用多个第一机器学习模型来处理未标记的训练数据中的每个训练示例的相应一个或多个特征值,其中,使用第三机器学习模型来生成相应一个或多个特征值。
11、由一个或多个处理器进行的方法或操作还可以包括进行使用细化的训练数据集来训练第三机器学习模型的附加迭代。
12、第三机器学习模型可以是表示学习模型,该表示学习模型被训练为从输入训练示例生成特征值。本公开各方面提供了基于由表示学习模型生成的训练示例的特征的学习的表示来对训练示例进行分类。代替单独的原始输入,在表示上训练还可以改进所得到的数据细化的精度。
13、多个第一机器学习模型和第二机器学习模型可以是一类分类器。
14、本文中描述的系统对于不同的机器学习模型架构是不可知的,这意味着它可以在各种不同的异常检测处理流水线中实施,而不失去通用性。除了系统在细化不同训练数据集时的灵活性之外,模型架构中的该灵活性还扩展了可能的应用领域。进而,根据本公开各方面所训练的系统可以更容易地适应于某些用例和技术限制,这可以比数据细化限于某些模型架构或用例的方法改进性能。
15、由一个或多个处理器进行的方法或操作还可以包括使用未标记的训练数据的相应子集来训练第一机器学习模型中的每个第一机器学习模型;通过多个第一机器学习模型中的每个第一机器学习模型来处理未标记的训练数据中的第一训练示例,以生成与第一训练示例是非异常或异常的相应概率对应的多个第一分数;确定至少一个第一分数不满足一个或多个阈值;以及响应于确定至少一个第一分数不满足一个或多个阈值,从未标记的训练数据中排除第一训练示例。
16、一个或多个阈值可以是基于与未标记的训练数据中的训练示例是非异常或异常的相应概率对应的分数分布的预定百分位数值。一个或多个阈值可以包括多个阈值,每个阈值是基于从由多个第一机器学习模型中的相应第一机器学习模型处理的训练示例所生成的相应分数分布的预定百分位数值。
17、由一个或多个处理器进行的方法或操作可以包括基于在优化过程的一次或多次迭代上对训练数据中的异常和非异常训练示例之间的相应类内方差进行最小化,生成一个或多个阈值。
18、提供每个机器学习模型阈值允许考虑模型处理中的差异和用于分类异常和非异常训练示例的容差,防止一个模型覆盖集合中的其余模型的决策。如下面更详细地描述的,系统可以为每个示例生成伪标签,表示在确定示例是否异常时多个模型的一致性。
19、由一个或多个处理器进行的方法或操作可以包括接收输入数据,以及使用第二机器学习模型来处理输入数据,以生成指示输入数据是异常还是非异常的输出数据。
20、由一个或多个处理器进行的方法或操作还可以包括发送输出数据,以用于在耦接到一个或多个处理器的显示设备上显示。
- 还没有人留言评论。精彩留言会获得点赞!