用于识别和减少性别偏差放大的方法和系统与流程
本发明的实施例一般涉及偏差(bias)放大识别和减轻。更具体地,本发明的实施例涉及用于识别多属性偏差放大并且通过综合平衡的数据集减少性别偏差放大的方法和系统。
背景技术:
1、以下背景信息可以呈现现有技术(例如,不限于方法、事实或常识)的特定方面的示例,这些示例虽然有望有助于进一步教育读者了解现有技术的附加方面,但不应被解释为将本发明或其任何实施例限制到其中所述或暗示的或由此推断的任何内容。
2、随着计算机视觉系统被越来越广泛地部署,研究界和公众越来越担心这些系统不仅复制、而且放大有害的社会偏差。偏差放大现象指的是模型在测试时放大固有的训练集偏差。
3、现有度量测量相对于单个注释属性(例如,计算机)的偏差放大。然而,几个视觉数据集由具有多个属性注释的图像组成。当前度量不会引起与多个属性(例如,{计算机,键盘})相关的相关性。另外,当前度量可能会给出错误的印象,即,由于它们涉及对正值和负值的聚合,因此发生最小偏差放大或没有偏差放大。此外,这些度量缺乏明确的期望值,从而使得它们难以解释。
4、尽管视觉数据集旨在忠实地描绘世界,但不可否认,它们存在历史和代表性偏差。未经检查的数据集偏差总是由模型学习,尤其是当它们是在给定数据集上监督学习的有效特征来源时。例如,图像字幕模型可以通过利用上下文线索学习生成性别字幕,而无需“观看”图像中的人。依赖于虚假的相关性是不可取的,原因是这些学习的关联并不总是成立的。更重要的是,这些关联不仅有可能使有害的社会偏差永久化,而且有可能放大这些偏差。
5、偏差放大的现象指的是当模型在测试时复合其训练集的固有偏差的情况。在许多任务中对偏差放大进行了研究。虽然在多标签分类中存在测量偏差放大的度量,但它们只考虑单个注释属性(例如,计算机)和群体(例如,女性)之间发生的放大。然而,现有的大规模视觉数据集通常对每个图像具有多个注释属性(例如,{计算机,键盘})。例如,在coco数据集中,78.8%的图像训练集与多于一个的属性(即,对象)相关联。因此,模型可以同时利用群体与单个或多个属性之间的相关性。
6、数据集偏差是计算机视觉中的被仔细研究的问题。数据集特别容易产生反映真实分布与其数字化表现之间的差异以及社会不平等的偏差。例如,数据集被发现在人口统计学上不平衡,尤其缺乏女性和深色皮肤个体的代表性。此外,来自不同群体的个人在图像中被表现或与对象交互的方式存在视觉差异。
7、当在这些数据集上训练模型时,数据集中的偏差可能会导致下游危害。除了再现偏差,机器学习模型也被发现放大它们。已经提出用于偏差放大的度量,该度量测量从训练到预测分布的对象共现的差异。在这项工作的基础上,其它人提出了“定向偏差放大”的度量,以理清由属性对组预测引起的偏差。替代性的工作重点是使用泄漏—分类器从训练数据到预测的预测组成员的能力的变化。
8、在数据集和模型级别上,均存在提出的用于减轻偏差放大的几种方法。在数据集级别上,流行的方法是使用生成对抗性网络(gans)以创建用于增强训练集的合成示例。在自然语言处理(nlp)领域中,先前的工作也使用生成的反事实以减少偏差。
9、假设某人一次只能与单个对象类别共现,则减轻性别偏差的第一级解决方案是收集额外的(或子样本)训练实例,使得各性别与每个对象类别平等共现。抛开这种天真的假设,立刻发现这种方法的棘手之处。此外,可能存在大量未解释的上下文线索,这些线索与性别虚假相关,诸如未标记的人-对象互动。例如,在openimages数据集中,尽管在乐器风琴和各性别的共现之间不存在显著差异,但女性不太可能被描绘成演奏风琴。因此,由于只平衡标记地址、性别相关的特征,因此在完全平衡的数据集中仍然可能出现偏差放大。
10、替换地,最近的工作提出更复杂的重新采样策略,以解决与对象的虚假相关性,模型经常利用这种虚假相关性以放大偏差。在模型级别上,现有的减轻策略包括语料库层面的约束、对抗性去偏和领域独立训练。然而,现有的方法不减轻来自多个属性的偏差放大。
11、鉴于上述情况,需要用于确定在多个属性上的性别偏差放大的度量和用于减少性别偏差放大的方法。
技术实现思路
1、本发明的各方面提供用于测量多属性偏差放大以评估由单个和多个属性引起的偏差放大的方法。本发明的各方面进一步解决聚合的偏差放大度量包括对正值和负值求和的问题。这些值可以相互抵消,从而在表面上表现出比实际上更小的放大量。最后,与缺乏明确理想值的现有度量相比,根据本发明的实施例的方法更具可解释性。
2、使用根据本发明的实施例的方法,可以确定用于偏差放大度量的coco和imsitu这两个标准基准上训练的多标签分类器的性能之间的比较。性别表达偏差放大可以被用作案例研究。这里,需要考虑多个属性。例如,在imsitu中,动词卸载和室内位置分别是倾向男性的。然而,当结合考虑{卸载,室内}时,数据集实际上是倾向女性的。值得注意的是,男性倾向于被描绘为在户外卸载包裹,而女性倾向于被描绘为在室内卸载衣服或盘子。从实验中可以发现,平均而言,由单个属性引起的偏差放大小于由多个属性引起的。因此,如果只考虑单个属性,它不仅可能掩盖多属性所提供的理解的细微差别,而且可能低估偏差放大。
3、此外,可以在根据本发明的实施例的方法的基础上对常规的偏差减轻方法进行基准测试,以证明单个属性偏差的减轻方法实际上可以增加多属性偏差放大。由于使用单个属性度量可能低估偏差放大的数值(magnitude),因此这进一步强调根据本发明的实施例的方法的重要性。
4、此外,可以通过包括各训练实例的感知二元性别表达(pbge)转换的反事实图像增强模型学习。反事实增强训练的显著特性是,它用于去关联与pbge相关的标记和未标记特征。
5、除了训练之外,反事实数据也可以用于实验性地揭示算法偏差。也就是说,反事实允许识别pbge和模型预测变化之间的因果关系。
6、此外,本发明的各方面提供对流行的“单对象”偏差放大度量的扩展,这可以被称为“多对象偏差放大”。根据本发明的实施例,该度量的独特特征是,它允许量化与各pbge同时出现的多个对象类别的偏差放大的平均数值。
7、本发明的各方面可以验证在复杂的语境共同对象(coco)数据集上的反事实增强训练的有效性。根据本发明的各方面,用反事实数据训练的模型在包括结合多对象共现的本发明的度量的几个偏差放大度量上始终优于强基线和算法干预。本发明的各方面进一步证明反事实对用于识别在coco上训练的模型中的偏差的应用。值得注意的是,虽然现有工作关注于增强训练数据或评估模型,但本发明的各方面可以被用于表示本文所述的方法可用于两个目的。
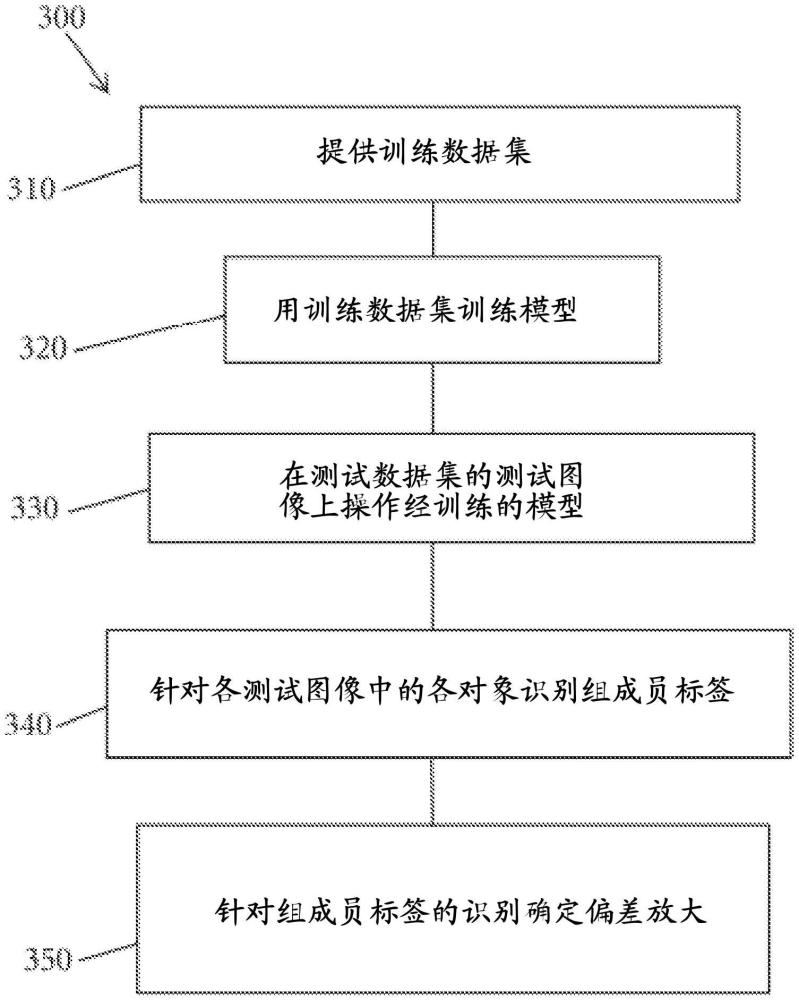
8、本发明的实施例提供一种确定模型中多个组成员标签上的偏差程度的方法,该方法包括:提供训练数据集,训练数据集具有训练数据集的多个训练图像中的多个训练数据集属性;训练模型以针对所述多个训练图像中的每一个中的训练图像对象识别所述多个组成员标签中的一个,其中,所述训练将所述多个组成员标签中的一个与所述多个训练数据集属性中的多个属性相关联;在测试数据集的多个测试图像上操作经训练的模型,所述多个测试图像中的每一个包括测试图像对象和多个测试数据集属性,以基于所述多个测试数据集属性针对各测试图像对象识别组成员标签中的一个;以及确定在针对所述多个测试图像中的每一个中的各测试图像对象识别所述多个组成员标签中的一个中的偏差放大。
9、本发明的实施例还提供一种用于测量多属性偏差放大以评估性别偏差放大的方法,该方法包括:提供训练数据集,训练数据集具有训练数据集的多个训练图像中的多个训练数据集属性;训练模型以针对所述多个训练图像中的每一个中的人识别多个组成员标签中的一个,其中,所述训练将男性性别标签或女性性别标签中的一个与所述多个训练数据集属性中的多个属性相关联;在测试数据集的多个测试图像上操作经训练的模型,所述多个测试图像中的每一个包括测试图像人和多个测试数据集属性,以基于所述多个测试数据集属性针对各测试图像人识别男性性别标签或女性性别标签中的一个;以及确定在针对所述多个测试图像中的每一个中的各测试图像对象识别男性性别标签或女性性别标签中的性别偏差放大。
10、本发明的实施例还提供一种有形地体现具有计算机可读指令的计算机可读程序代码的非暂时性计算机可读存储介质,所述计算机可读指令在被执行时使计算机设备实施提高确定模型中关于多个属性在多个组成员标签上的偏差程度的计算效率的方法,该方法包括:提供训练数据集,训练数据集具有训练数据集的多个训练图像中的多个训练数据集属性;训练模型以针对所述多个训练图像中的每一个中的训练图像对象识别所述多个组成员标签中的一个,其中,所述训练将所述多个组成员标签中的一个与所述多个训练数据集属性中的多个属性相关联;在测试数据集的多个测试图像上操作经训练的模型,所述多个测试图像中的每一个包括测试图像对象和多个测试数据集属性,以基于所述多个测试数据集属性针对各测试图像对象识别组成员标签中的一个;以及确定在针对所述多个测试图像中的每一个中的各测试图像对象识别所述多个组成员标签中的一个中的偏差放大。
11、参考以下附图、说明书和权利要求书,将更好地理解本发明的这些和其它特征、方面和优点。
- 还没有人留言评论。精彩留言会获得点赞!