一种基于渐进训练和人脸语义分割的人脸超分辨率重建方法
本发明涉及人脸图像重建,尤其涉及到一种基于渐进训练和人脸语义分割的人脸超分辨率重建方法。
背景技术:
1、图像超分辨率是指将低分辨率的图像或图像序列恢复成高分辨率图像。人脸图像超分辨率,又被称为人脸幻象重建,是属于图像超分研究领域的一个分支,其旨在通过将低分辨率人脸图像重建为高清人脸图像。当今,有如下几个工业应用需要用到大量高分辨率的人脸信息:第一,在人脸识别、人脸解析、人脸对齐等计算机视觉任务中常常需要从输入图像中获取丰富的语义信息。这些模型算法可以从高清的人脸中提取到更多的图像特征从而提高算法的精度;第二,在公安系统中,警察经常需要通过摄像头来获取犯罪嫌疑人的容貌信息,但是由于硬件设备以及拍摄环境等条件限制,从摄像头捕捉下来的图像常常是低分辨率的,从模糊图像中获取信息无疑是非常困难的,警方需要高清的人脸图像锁定嫌疑人身份。
2、图像插值法是一种简单而快速的人脸超分算法,该方法虽然已被广泛应用于生活中各个场景,但是其对极低分辨率(例如16×16像素)图像进行高倍数放大时的效果不佳。基于深度学习的人脸超分算法利用卷积神经网络的优质特性可以取得良好的超分效果。但是现有的基于深度学习的人脸超分算法存在以下几点问题:第一,许多模型为了提升算法性能会在网络结构中堆叠更多的卷积块或添加更多复杂的子结构,这样做势必会增加模型的计算复杂度。参数量庞大的模型会受限于计算资源而难以训练,同时也难以在一些轻量级的移动设备上部署应用;第二,一个人脸超分模型通常只能针对一个特定的倍数进行放大,面对多种放大倍数的需求时,只能耗费额外资源去训练新的模型;第三,当前许多人脸超分模型在训练时会使用到大量人工标注的人脸先验信息,标注数据给相关工作者带来了更多的工作量。
技术实现思路
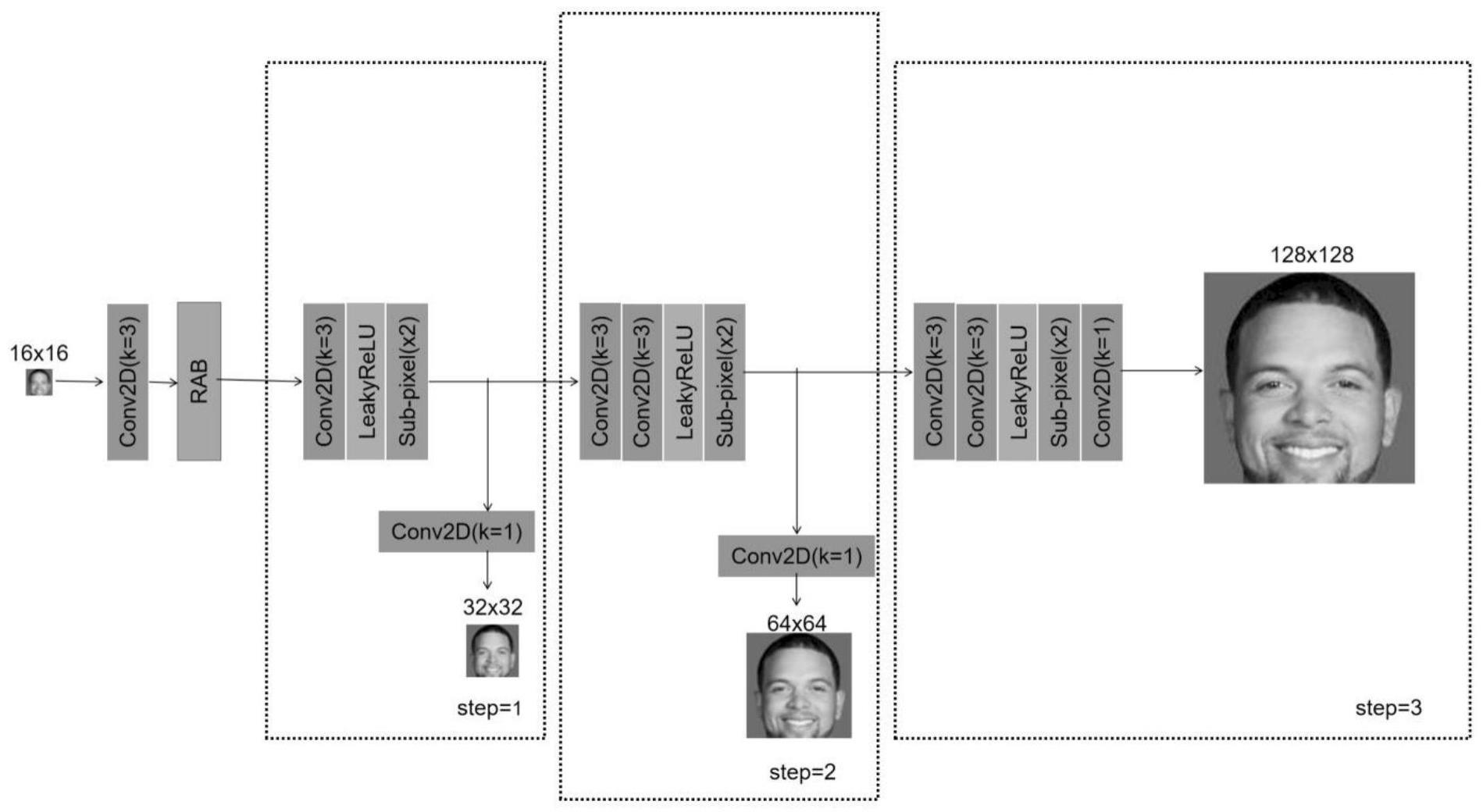
1、针对现有技术存在的问题,本发明提出了一种轻量高效的人脸超分辨率重建方法,基于rfdn(residual feature distillation network)网络进行改进,引入人脸语义分割模型协助网络获取人脸先验信息,采用渐进训练的方式使模型在一次迭代训练中分三阶段开展,提出在模型训练中加入人脸分割损失以产生更加逼真的人脸。本发明涉及的人脸超分辨率重建方法适用于超低分辨率(例如16×16像素)的人脸图像输入,并可以输出三种不同放大倍数的高分辨率重建图像。
2、为了实现上述发明目的,本发明采用的技术方案是:一种基于渐进训练和人脸语义分割的人脸超分辨率重建方法,包括以下步骤:
3、s1:准备训练数据,具体包括低分辨率人脸图像ilr16(16×16像素),高分辨率人脸图像ihr32(32×32像素)、ihr64(64×64像素)、ihr128(128×128像素)。
4、s2:提出轻量级人脸超分辨率网络lfsrnet,lfsrnet网络由残差聚合模块rab(residual aggregation block)和三个上采样块组成:
5、1)残差聚合模块rab用于获取低分辨率图像的图像特征,rab模块是由4个残差特征蒸馏块rfdb(residual feature distillation block)通过残差聚合的形式构成,这样的结构可以大大提升网络提取特征的能力。
6、其中,残差聚合的形式为:前后相连的rfdb进行残差学习,将第一个rfdb输出的特征f1、第二个rfdb输出的特征f2、第三个rfdb输出的特征f3,第四个rfdb输出的特征f4进行堆叠,将堆叠后的特征经过一个卷积进行特征融合并输出。
7、2)三个上采样块主要由卷积和亚像素卷积构成,每个上采样块可以进行两倍的图像放大,并输出重建图像。
8、其中,第一个上采样块依次由卷积、leakyrelu、pixshuffle(2倍放大)、卷积组成;第二个上采样块依次由卷积、卷积、leakyrelu、pixshuffle(2倍放大)、卷积组成;第三个上采样块依次由卷积、卷积、leakyrelu、pixshuffle(2倍放大)、卷积组成。
9、s3:将s1中的ilr16送入s2中的lfsrnet网络,分别经过rab模块和第一个上采样块,前向推理得到两倍放大的超分辨率图像isr32。
10、s4:根据以下损失函数,对网络进行反向传播,完成第一阶段网络参数的更新和优化。
11、
12、其中n表示模型训练中一个批次中的数据量。
13、s5:将s1中的ilr16送入s2中的lfsrnet网络,分别经过rab模块、第一个上采样块以及第二个上采样块,前向推理得到四倍放大的超分辨率图像isr64。
14、s6:根据以下损失函数,对网络进行反向传播,完成第二阶段网络参数的更新和优化。
15、
16、其中n表示模型训练中一个批次中的数据量。
17、s7:将s1中的ilr16送入s2中的lfsrnet网络,分别经过rab模块、第一个上采样块、第二个上采样块以及第三个上采样块,前向推理得到八倍放大的超分辨率图像isr128。
18、s8:将s1中的ihr128送入一个人脸语义分割网络中,得到高分辨率人脸语义分割预测图pseghr128,将pseghr128进行数据处理得到高分辨率人脸语义分割图seghr128。
19、其中,该人脸语义分割网络是经过预训练的,并可以对人脸图像中的左眼、右眼、鼻子、嘴唇等多个部位进行人脸语义分割。
20、其中,人脸语义分割预测图pseghr128的形状大小为(128×128×c),c代表人脸语义分割网络可以分割的种类数,pseghr128中每个像素值代表该位置上每个种类的预测置信度。
21、进一步地,将pseghr128中每个像素里置信度最高的类作为最终分割结果,生成高分辨率人脸语义分割图seghr128,seghr128是像素大小为(128×128)的灰度图像。
22、s9:将s7中的isr128送入s8中的人脸语义分割网络中,得到超分辨率人脸语义分割预测图psegsr128。
23、其中psegsr128的形状大小为(128×128×c),c代表人脸语义分割网络可以分割的种类数。
24、s10:根据以下损失函数,对网络进行反向传播,完成第三阶段网络参数的更新和优化。
25、
26、其中n表示模型训练中一个批次中的数据量,c表示人脸语义分割网络可以分割的种类数,α和β分别表示两种损失的权重。
27、其中,该阶段使用人脸语义分割网络获取人脸先验信息,将seghr128与psegsr128的交叉熵损失纳入总损失函数来更新网络参数,协助网络生成更加逼真的人脸结构。
28、进一步地,人脸语义分割网络对输入图像的分辨率大小要求较高,在一次迭代训练中最后一阶段生成的超分辨率图像像素大小为(128×128),具有较多的语义信息,可以满足人脸语义分割网络的输入需要。
29、s11:循环迭代s3至s10,将模型训练至收敛。
30、其中,使用adam梯度下降优化算法对模型进行训练,初始学习率为0.001,使用线性步长学习率调整策略调整学习率,训练若干epochs至模型收敛。
31、进一步地,训练收敛的模型可以对低分辨率(16×16像素)人脸图像进行二倍、四倍和八倍的超分辨率图像重建。
32、本发明的有益效果是:
33、1、本发明中的网络模型具备轻量、高效的特点,一个模型可以实现三种不同倍数的人脸超分辨率重建。
34、2、本发明适用于极低分辨率(例如16×16像素)的人脸图像输入,并可以产生质量良好的重建图像。
35、3、本发明使用人脸语义分割网络模型获取人脸先验信息,提出一种人脸分割损失,帮助模型重建更加逼真的人脸面部结构。
- 还没有人留言评论。精彩留言会获得点赞!