一种面向矿山微震事件预警时间序列的动态矩阵聚类方法
本发明属于流式数据挖掘领域,特别涉及一种工业物联网时间序列异构数据的处理设计,具体涉及一种面向矿山微震事件预警时间序列的动态矩阵聚类方法。
背景技术:
1、近年来,随着信息化技术的快速发展,金融、生物、气象、医学,工业物联网等各个领域产生了大量的时间序列数据,挖掘数据中的潜在价值对决策者具有重大的指导作用。聚类作为一种无监督学习方法,由于其事先无需对任一样本打类别标记,在分析数据的内在关系及蕴含的信息、知识等方面发挥着至关重要的作用。
2、冲击地压一直是煤矿开采过程中最严重的灾害之一,当微震事件发生时会释放巨大能量,可能在短时间内摧毁煤矿井下的开采工作面,造成严重的人员伤亡以及巨额的直接经济损失。在微震事件的监测系统中,采集器会采集微震事件发生时产生的弹性波数据,数据为时间序列形式,如图1所示。通过对微震事件波形的聚类,可实现事件的无监督识别,从而定位出冲击地压的发生区域,为煤矿的开采提供安全风险预警。
3、现实中,时间序列数据受环境及人为因素干扰,数据的结构总是存在伸缩、漂移等失真问题,使得序列间距离计算的精度较低,进而影响聚类准确率。此外,时间序列数据集多含有大量的噪声,如图1中的第4个子图所示,受外部环境的影响,采集器采集的数据很多并非是真实事件的弹性波,而是爆破、背景噪声、矿车振动等干扰数据,去噪不彻底或去噪过度均极大地影响聚类准确率与效率。因此,如何在含噪数据集上对结构失真的时间序列进行精准高效的聚类,一直是流数据挖掘领域研究的难点,也是当前亟待解决的问题。
技术实现思路
1、本发明针对上述问题,设计一种面向矿山微震事件预警时间序列的动态矩阵聚类方法,通过精准、高效地构建rds与数据集的距离矩阵,将对原始数据集的聚类转化为对动态化矩阵的聚类,实现对矿山微震预警时间序列的事件有效预警。
2、本发明的目的是通过下述技术方案实现的:一种面向矿山微震事件预警时间序列的动态矩阵聚类方法,其步骤为:
3、1)构建近邻评价体系,根据评价值优劣衡量微震事件的代表性,通过近邻评分的后向差分计算策略构建rds候选集,具体方法为:
4、近邻评价体系构建:
5、提出rds及其候选集概念,并基于矿山微震近邻密度和反向近邻数构建事件近邻评价体系,为衡量数据集中序列之间的相似程度并实现rds候选集的选取及去噪,结合序列的近邻密度和反向近邻数,提出序列近邻评价规则,通过序列近邻评分的高低将数据集中的所有序列划分为三种不同类型;
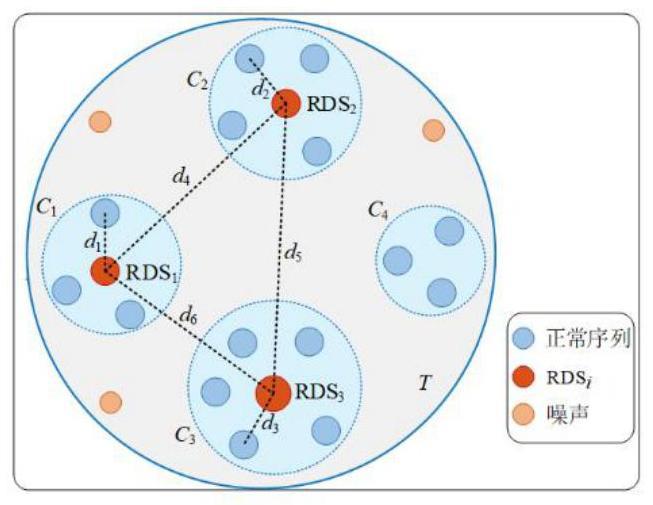
6、定义1rds:给定时间序列数据集d={t1,t2,...,ti,...,tn},rds为从d中选出的可最大化地代表不同类簇且差异性最大的k个序列,其中的一个序列记为rdsi,1≤k≤n且1≤i≤k;
7、数据集d被划分为四个类簇c1~c4,每个类簇包含许多序列,d中有最佳的rds,其中,rds1与类簇c1中任一序列的距离d1较小,使得它与c1的整体相似度最大,最大化地代表c1;rds2、rds3分别最大化地代表c2、c3;rds1~rds3间的距离d4~d6均较大,在最大化地代表d中不同类别的同时,满足互相之间的差异性最大;
8、rds选取策略影响时间序列聚类效率,直接从数据集d中选取的代价过高,因而先构建其候选集,再从候选集中查找k个代表性与差异性同时最大的序列构成rds;
9、为刻画数据集中每个序列与其他序列的近邻关系,根据序列间的互相关距离的大小,给出序列r邻域的定义;
10、定义2r邻域:给定大小为n的数据集d,时间序列x的r邻域nnr(x)定义为d中与x距离最近的r个序列的集合,即:
11、nnr(t)={x|d(t,x)≤dr(t)} (5)
12、其中,1≤r<n,d(x,y)表示x与序列y的互相关距离,dr(x)表示x与其他序列的第r近邻互相关距离;
13、对于一个序列x,使用x的近邻密度量化x与其r邻域内的所有序列的总体相近程度;
14、定义3近邻密度:给定给定序列x的r邻域nnr(x),x的近邻密度f(x)为x与其r邻域内的所有序列的距离和的倒数,即:
15、
16、p(t)越大,表示t与所有在其r邻域内的温度的整体相似性越高;反之,则相似性越低,此外,通过反向近邻数可从反向角度衡量温度t与其他温度的相近程度;
17、定义4反向近邻数:反向近邻数nb(x)表示在对数据集d中的每个序列构建其r邻域的过程中,序列x被其他序列近邻的总次数;即:对于若则nb(x)=nb(x)+1;
18、nb(x)越大,表明x被更多的序列近邻,反向说明x与更多序列的距离越近,即x与更多序列的相似度越高;在近邻密度和反向近邻数的基础上,本文提出序列近邻评分的概念,同时从正反两方面综合衡量序列x与其他序列的整体相似性;
19、定义5近邻评分:给定序列x的反向近邻数nb(x)与近邻密度f(x),x的近邻评分s(x)为ln(nb(x)+1)与f(x)的乘积,即:
20、
21、公式(3)中,给定x的r邻域nnr(x),若x的反向近邻数nb(x)与近邻密度f(x)越大,则s(x)越大,表明x与更多序列相似,即x为具有代表性的序列,因此x属于rds候选集;若nb(x)或f(x)越小,使得s(x)越小时,表明几乎没有与x相似的序列,x应属于噪声。
22、2)提出基于组合优化的rds选取方法,从候选集上快速得到rds最优解,具体方法为:
23、基于后向差分法的rds候选集构建:
24、在近邻评价体系的基础上,提出近邻评分的后向差分计算策略,依据差分计算结果快速筛选rds候选集;
25、矿区实际微震数据集包含多种类型的微震事件及部分噪声,事件与噪声都是时间序列形式的数据,对该数据集中的所有序列需要计算近邻评分,归一化并排序;
26、提出近邻评分的后向差分计算策略,通过比较差分值的大小确定边界并构建候选集,后向差分计算公式如下:
27、
28、其中,为差分算子,s(t)与s(t-1)为两个相邻温度。
29、3)动态构建rds与数据集的距离矩阵,提出基于k-means的矩阵聚类方法,通过对微震事件波形的聚类,实现事件的无监督识别,定位出冲击地压的发生区域,为煤矿的开采提供安全风险预警,具体方法为:
30、步骤3-1最优rds解选取
31、由定义1可知,rds需同时满足相似性与差异性两个条件,故rds的选取为多条件约束最优解问题,通过组合优化的方法求解,依据近邻评分计算候选集中所有可行解的质量指标qi,通过比较qi的大小得到最优解;
32、定义6:质量指标质量指标qi用于同时衡量rds的一个可行解f的双重约束条件,计算公式如下:
33、qi(f)=αu+(1-α)v (7)
34、其中,0<α<1,系数α用于均衡u与v的占比,默认情况下,α=0.5;u,v越大,则qi(f)越大,表明f的“相似性”与“差异性”越大,选取质量越高;当qi(f)最大时,rds取得最优解o,即:
35、
36、步骤3-2基于k-means的矩阵聚类
37、在步骤3-1选出的rds的基础上,通过动态构建rds与数据集的距离矩阵进行聚类对象的转化,提出基于k-means的矩阵聚类方法,根据矩阵聚类结果得到矿山微震时间序列的类别标签;
38、rds与数据集的距离矩阵m的形式如下所示:
39、
40、m的大小为[n,i],i≤k,表示rds中实际参与聚类的rds的数量,n表示数据集中所有时间序列的数量,m中的元素mji表示rds i与序列j的互相距离;
41、此外,m不是由rds与数据集的距离向量直接构成,而是逐步扩展、动态构建生成。其目的是进一步提高聚类的准确率和效率,当计算rdsi与数据集的距离向量后,将该向量添加为矩阵m的一列横向扩展m,根据当前的聚类纯度pur的大小,再决定是否需要继续拓展m以及进行聚类操作;
42、聚类纯度的计算公式如下:
43、
44、其中,n表示总的时间序列数量,c={c1,c2,…,cj}表示真实的类簇划分,ω={w1,w2,…,wk}表示当前聚类的类簇划分。pur(c,ω)∈[0,1],值越大,表示聚类准确率越高。
45、本发明创造的有益效果是:
46、本发明针对煤矿灾害流式数据上事件模板构建过程中存在的计算量过大,使用的数据节点较多,误差较大等问题进行了深入的研究。针对模板构建中存在不足,提出了一种基于b-spline曲线的流式大数据事件模板构建方法。提出了流式数据上的事件定义和事件模板定义。确定了煤矿灾害基本尺度事件,并且利用线性变换将同类事件进行归一化处理,最后采用平均值法得到b-spline的标准输入曲线。针对b-spline曲线拟合的几个重要因素,提出在均匀的节点矢量下使用遗传算法求解b-spline的节点矢量,分别从煤矿灾害事件编码方案,事件适应度函数,选择算子,交叉变异这几个方面来探讨具体的求解过程。从而减少了煤矿灾害事件模板构建过程中的计算量大,数据节点多,误差较大等问题。
- 还没有人留言评论。精彩留言会获得点赞!