一种面向并行运算的基于节点相似性的社区发现方法
本发明涉及社交网络分析,具体涉及一种面向并行运算的基于节点相似性的社区发现方法。
背景技术:
1、随着移动互联网技术的快速发展,人们对社交网络的认识也越来越深刻。现如今生活中存在着很多网络服务平台,如twitter和新浪微博等这些网络服务平台产生了大量用户和数据,由于人际关系的存在,社交网络往往都具有明显的社区结构特征,具有社区内人们联系频繁,社区间联系较少等特点。社区发现作为社交网络分析的重点工作,能够发现社交网络中的社区,可以帮助用户找到与自己兴趣相同或相仿的其他用户,给用户带来更精准的服务需求和服务价值。
2、社区发现是用来揭示网络聚集行为的一种技术,在社交网络中可以创造可观的价值。目前存在多种优秀的社区发现算法大多数都是基于网络结构的划分,该类别主要使用网络节点之间的拓扑结构。这类方法在算法复杂度、结果有效性方面表现良好,目前已经在许多场景中投入实用。比如,基于最大化模块度划分的louvain方法、图谱聚类方法和基于边聚类的方法、基于标签传播的方法等。
3、现有的社区发现方法在静态社交网络中的社区发现方面已经取得一定成果,但仍存在以下几个问题:1)算法的时间与空间复杂度通常比较高,在处理大规模社交网络时的时间开销和空间开销过高;2)算法通常需要一次性读取整个网络,当网络规模较大时,往往无法在单机上完成;3)算法设计时通常只考虑串行步骤的执行,未引入并行运算机制,可扩展性不强4)现有社区发现法划分的结果不太稳定;5)在社区划分时网络节点间的连边属性信息常常会被忽略;6)现有社区发现方法只能在小规模社交网络中进行社区划分,大规模社交网络下,这些社区划分方法存在划分效率慢等问题7)是仅对网络结构信息建模并未充分利用到真实世界网络的全部信息。在真实世界的社交网络中除了能获得网络的结构信息之外,用户的性别、年龄、地区、兴趣等属性信息也可以容易地获取。各用户之间的属性相似度信息更加能够反应用户之间的关系。
4、为了克服以上传统社区发现算法大多基于网络结构划分、划分结果不稳定、节点之间属性常常在划分时被忽略等常见问题,引入节点间相似性来提高社区发现算法infomap的正确率,因为infomap算法是顺序社区发现算法中划分准确性比较一般,在正确性有待进一步提高,而且infomap算法只能在小规模的社交网络中进行社区划分,在大规模网络无法进行社区划分。因此为了在大规模社交网络进行社区划分,引入并行运算的方法进行社区划分,改变顺序社区发现方法的痛点。在并行运算方法就是将网络分为若干的子网络,有多个处理器同时对多个子网络进行社区划分。
5、最近十几年,多数文献中已经对面向并行运算的顺序社区发现算法提出了很多种方法,总结代表性的方法有以下几个方面,第一是使用基于c++的并行编程库openmp(openmulti-processing),openmp是一套支持跨平台共享内存方式的多线程并发的编程api,主线程生成一系列的子线程,并将任务划分给各子线程进行执行。这些子线程并行的运行,由运行时环境将线程分配给不同的处理器,支持多线程异步和同步操作达到并行运算目的。第二是通过信息传递接口mpi(message passing interface)来实现并行运算的社区发现过程,mpi是一种基于信息传递的并行编程技术,它提供了对等模式、点对点通信模式和组通信三种并行编程模式和6个mpi调用接口来实现社区发现算法的并行运算。第三是基于分布式计算框架mapreduce计算框架来实现社区发现算法的并行运算过程。mapreduce是面向大数据并行运算的计算模型和框架,它借助于函数式程序设计语言lisp的设计思想,提供了一种简便的并行程序设计方法,用map和reduce两个函数编程实现基本并行运算任务,提供了抽象的操作和并行编程接口,以简单方便地完成大规模社交网络数据的社区发现过程的计算处理。但,上述方法要求对c++编程语言、并行编程接口和并行运算物理机有深入的理解,实现难度较高,实现成本较大;基于mapreduce的编程模块虽然降低了并行编程的难度,但是由于mapreduce本身计算的中间结果是要存储磁盘,这使得mapreduce在大规模社交网络中社区划分时间耗时非常长,效率非常低。
技术实现思路
1、针对现有技术中存在的不足之处,本发明提供一种面向并行运算的基于节点相似性的社区发现方法,采用spark(专为大规模数据处理而设计的快速的计算引擎)、并引入节点相似性矩阵和所有邻居模块合并相结合的方法来对社区发现算法实现并行运算,通过优化社区发现算法infomap的目标函数最小描述长度来提高算法划分的正确率、同时降低算法划分的时间耗时,同时提高算法划分的并行效率。
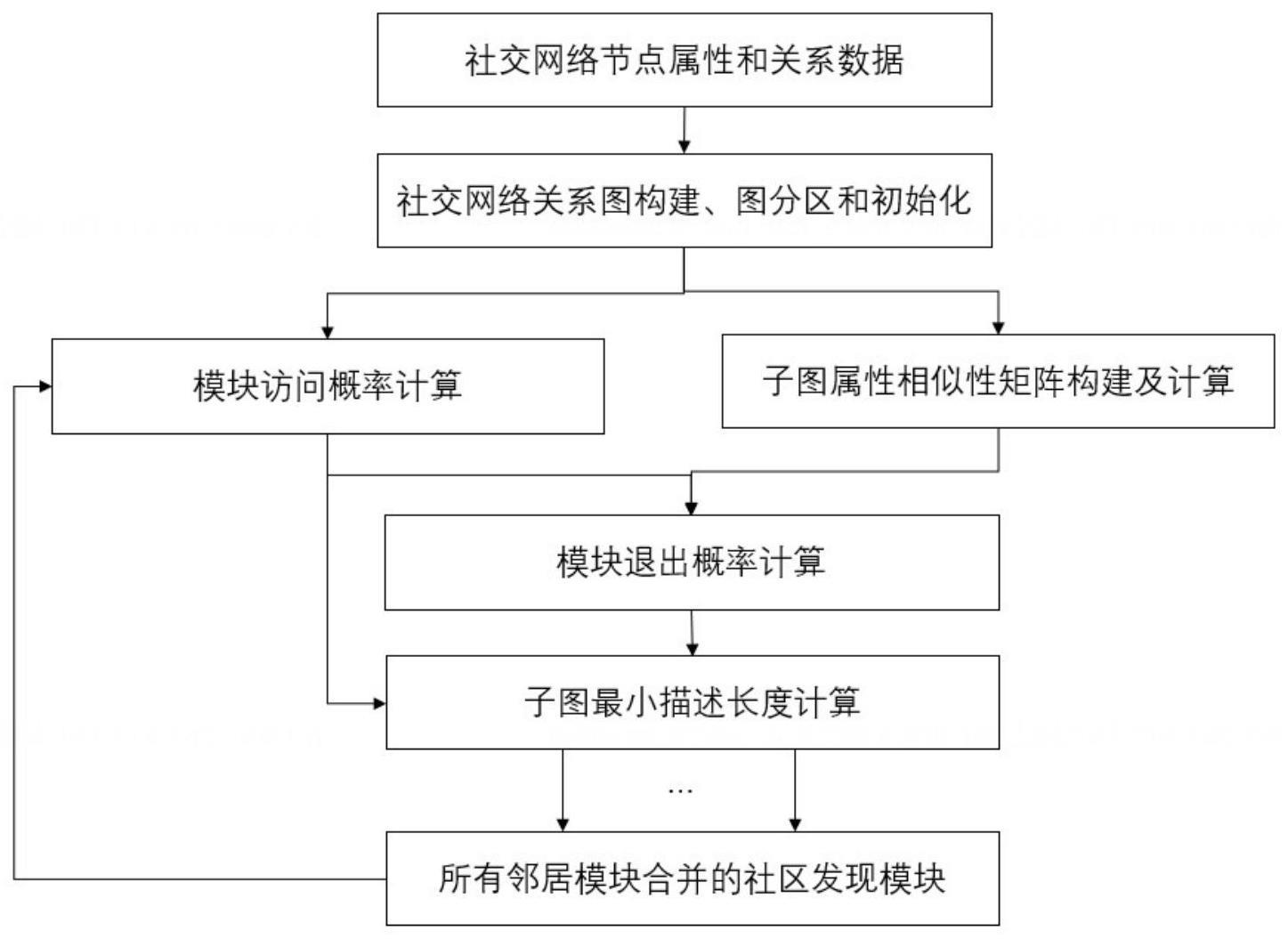
2、本发明公开了一种面向并行运算的基于节点相似性的社区发现方法,包括:
3、获取社交网络用户节点数据,所述社交网络用户节点数据包括:用户节点关系数据和用户节点固有属性数据;
4、基于用户节点关系数据构建有向图g(v,e),其中,v表示节点集合,e表示节点之间的连边集合,连边的属性值由两个用户节点属性的相似性计算得到;将图g划分为若干子图,每个子图按照邻接表方式存储在一个分区中,并由对应的一个处理器处理;
5、根据每个子图中节点的属性集合通过归一化方式构建每个节点的特征向量,采用余弦相似度计算任意两节点之间的相似度;构建每个子图的属性相似性矩阵,并将该子图中所有节点的相似度存储至对应的属性相似性矩阵中;
6、计算子图中每个节点的访问概率,并对子图中每个模块内所有节点的访问概率求和,得到模块的访问概率;
7、基于子图的属性相似性矩阵以及模块的访问概率,计算每个处理器中每个模块的退出概率;
8、基于子图的属性相似性矩阵、模块的访问概率以及模块的退出概率,计算子图最小描述长度,作为本次社区划分的目标函数值;
9、每个处理器同时试图将对应子图中一个模块合并到每个邻居模块,判断合并前后每个模块的最小描述长度降幅最大差异值是否小于零,若小于,则进行邻居模块合并,并更新子图的最小描述长度;重复上述操作,将最后划分的模块作为最终的社区划分结果。
10、作为本发明的进一步改进,节点i,j之间连边的属性值wbase(i,j)为:
11、
12、式中,simij为节点i与节点j的属性相似度。
13、作为本发明的进一步改进,多个处理器之间通过交换虚节点,并将虚节点添加到对应处理器的局部子网络图中,以实现不同处理器之间进行社区划分信息通信;其中,虚节点为实际存储在一台处理器却被多台相关处理器进行共享社区划分过程信息通信的节点。
14、作为本发明的进一步改进,节点i与节点j之间的相似度simij为:
15、
16、式中,a和b分别代表节点i和节点j属性特征向量,‖a‖和‖b‖代表特征向量a和b的长度,ac和bd分别代表特征向量a和特征向量b中对应的一个特征向量分量,c和d代表a和b中分量的序号。
17、作为本发明的进一步改进,还包括:节点分类;
18、所述节点分类,包括:
19、判断节点是否满足对外没有连接边或节点出度为零;
20、若节点满足对外没有连接边或节点出度为零,则将该节点定义为悬空节点;
21、若节点满足对外有连接边或节点出度不为零,则将该节点定义为非悬空节点。
22、作为本发明的进一步改进,
23、悬空节点的访问概率为:悬空节点所连接的非悬空节点出度数倒数;
24、非悬空节点的访问概率为:根据属性相似性矩阵计算该节点访问邻居节点的相似度simij除以该节点访问所有邻居节点的相似度simij的和。
25、作为本发明的进一步改进,模块α的退出概率qα为:
26、
27、式中,pα是模块α的访问概率,τ是阻尼系数,默认是0.85,n是子图gγ中节点数量,nα是模块内的节点数量,pi是节点i中访问概率,simij是节点i到节点j的相似度。
28、作为本发明的进一步改进,最小描述长度mdl为:
29、mdl=plogp(∑αqα)-2∑αplogp(qα)-∑iplogp(pi)+∑αplogp(pα+qα)。
30、作为本发明的进一步改进,所述每个处理器同时试图将对应子图中一个模块合并到每个邻居模块,判断合并前后每个模块的最小描述长度降幅最大差异值是否小于零,若小于,则进行邻居模块合并,并更新子图的最小描述长度;重复上述操作,将最后划分的模块作为最终的社区划分结果;包括:
31、(1)、在每个处理器p上同时试图将其中一个模块α合并到处理器p上每个邻居模块,在每个处理器p上同时计算并判断合并前后每个模块α的最小描述长度mdl降幅最大差异值是否小于零;如果在一个处理器p0(p0是处理器p中的一个处理器)上模块α试图合并在一个处理器p0上邻居模块后满足降幅最大差异值小于零条件,将在这一个处理器p0上模块α依次合并在这个处理器p0上所有邻居模块,通过spark广播机制向其他处理器p1广播所有mdl降幅最大的模块分区的模块概率、模块退出概率和子图属性相似性矩阵(p1是处理器p中的一个处理器),在每一个处理器p0上同时更新当前处理器p0上所有模块的模块概率、模块退出概率和子图属性相似性矩阵;如果在一个处理器p0上模块α试图合并这一个邻居模块后不满足降幅最大差异值小于零条件,需要在这一个处理器p0上判断下一模块u1试图合并到每个邻居模块,重复判断执行步骤(1),直到找不到下一模块满足判断条件时,返回开始执行步骤(2);
32、(2)、在每个处理器p上同时计算当前模块更新后新图的最小描述长度mdlnew,每个处理器p上同时合并模块作为在每个处理器上形成的一个新图节点,同时合并模块边作为在每个处理器上形成的一个新图边作为每个处理器p上新图的边;在每个处理处理器p上构造一个新图,当前迭代次数k加一;
33、(3)、判断合并后新子图mdlnew和合并前子图mdl的差值是否小于划分质量阈值θ并且当前迭代次数k是否小于初始迭代次数itera,如果满足条件,则返回子图属性相似性矩阵计算,如果不满足条件,则将此时划分的模块作为最终的社区划分结果。
34、与现有技术相比,本发明的有益效果为:
35、1、目前社交网络社区发现方法主要利用用户节点之间的结构关系,忽略了用户节点属性的相似性在社区发现中的积极作用;本发明通过引入社交网络节点属性的相似性来实现社区发现infomap的划分过程,解决了现有技术中infomap算法划分正确性的问题,可以提高infomap算法划分的正确性;
36、2、本发明在引入社交网络节点属性的相似性来实现社区发现infomap时,提出了基于相似性的随机游走公式,提升了模块选择其他邻居模块的退出概率,加快了infomap算法的收敛速度,减少了算法的迭代次数,降低了算法划分的时间耗时,提升了算法的正确性;
37、3、本发明通过采用spark和所有邻居模块合并相结合的方法对社区进行发现,解决了现有技术中在大规模网络中无法在单机环境进行社区发现问题和现有并行运算环境中社区划分方法带来计算效率低和易用性低等问题,引入并行运算方法提升了实现社区发现方法的正确性,计算性能和算法执行效率。
- 还没有人留言评论。精彩留言会获得点赞!