一种基于FPGA的图神经网络高DSP资源利用率的稀疏稀疏矩阵乘法阵列
本发明涉及机器学习,更具体的,涉及一种基于fpga的图神经网络高dsp资源利用率的稀疏稀疏矩阵乘法阵列。
背景技术:
1、近年来,电子商务,知识图谱或分子生物学等应用场景将关系复杂的对象建模为图或流形等非欧几里得数据结构,这种数据结构难以通过传统神经网络提取和分析潜在的信息。而图神经网络在处理这一类非结构化数据上有无可比拟的优势,且已经在如阿里巴巴的aligraph、euler平台和pontry平台上成功部署。
2、在图中,每一个顶点代表一个对象,顶点中包含特征向量,也就是该对象的属性。而顶点之间的边代表对象之间的关系。以电子商务为例,使用商品作为顶点的话,很容易就拥有百万以上的节点数量,且商品之间边的数量在一张图中变化剧烈,但通常遵循幂律分布。在不同的应用场景中,每个顶点拥有的特征特点也大不相同,从知识图谱的向量维度大但极度稀疏到社区论坛图谱中向量维度中等但中等稠密。这种不规则性给gnn的部署过程带来巨大的挑战。
3、每一层的gnn推理一共主要包含两个阶段:聚合和组合。聚合阶段中,每个节点将会聚合其邻居的特征向量来进行更新,由于节点之间的邻接矩阵极其稀疏,且特征矩阵较为稀疏,所以其涉及的计算强度不高。但所设计的两个矩阵都基本满足幂率分部,且维度较大,所以涉及大量不规则访存。组合阶段中,将聚合完的边和节点通过组合函数进行转换,其涉及的权重矩阵是稠密的,所以其涉及密集的矩阵乘法计算。目前已有的gnn加速器主要部署在专用集成芯片(asic)和现场可编程门阵列(fpga)上,相比起其他器件上的加速方案,这些gnn加速器的计算效率更高,也更加节能,但由于asic的开发周期长,其定制化的特性使其灵活性不足,一个固定规模的加速器,在一个固定应用场景不同数据集上的性能使用率可能出现很大的变化,难以克服对输入图特征的数据依赖性,也难以满足不同应用场景中不同的性能目标。
4、现有的针对gnn聚合阶段的稀疏稀疏矩阵乘法阵列设计中,主要通过合并切片数据或对稀疏矩阵片去零来提高数据稠密度,在尽可能维持数据规整性的同时复用所输入的数据,导致其需要复杂的数据预处理且计算过程中出现了很多无效操作,使得乘法器的有效利用率低,平均每个周期能进行有效运算的乘法器不到所使用乘法器的25%。
技术实现思路
1、本发明为了解决以上现有技术存在的不足与缺陷的问题,提供了一种基于fpga的图神经网络高dsp资源利用率的稀疏稀疏矩阵乘法阵列,其在保证gnn聚合阶段的输入数据复用率的情况下,减少所需乘法单元的数量,使得乘法单元的整体利用率提高。
2、为实现上述本发明目的,采用的技术方案如下:
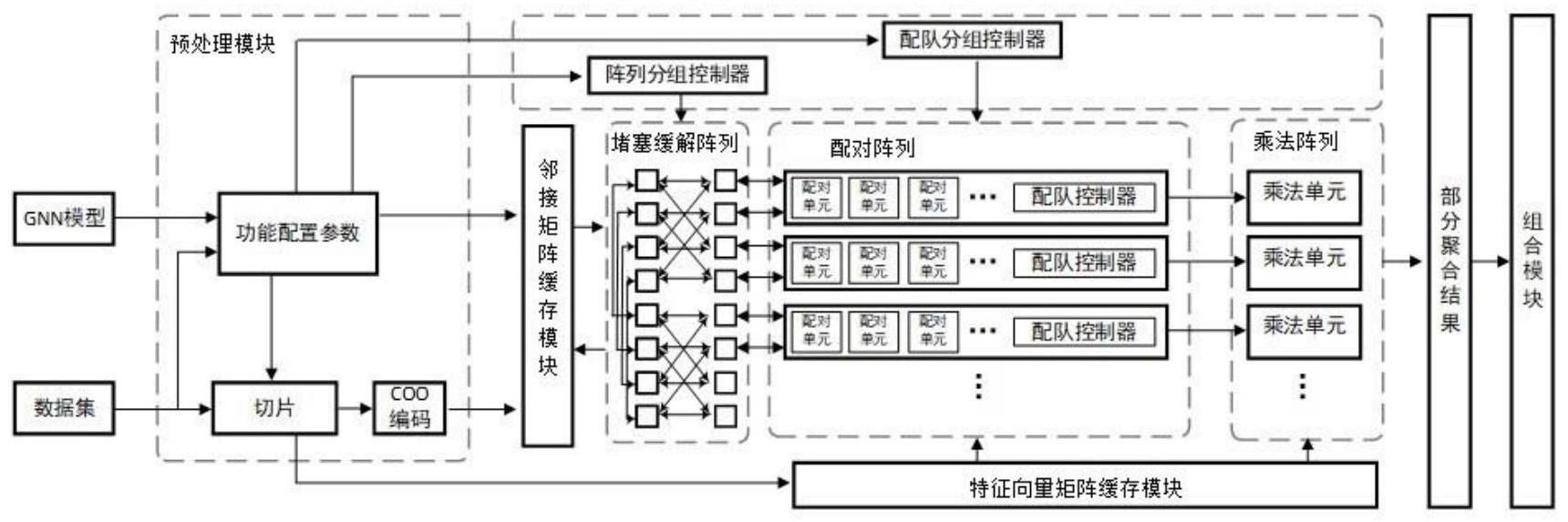
3、一种基于fpga的图神经网络高dsp资源利用率的稀疏稀疏矩阵乘法阵列,应用于gnn聚合阶段,其利用fpga上的dsp资源进行计算,包括预处理模块、邻接矩阵缓存模块、堵塞缓解阵列、配对阵列、乘法阵列、特征矩阵缓存模块、
4、所述的预处理模块,用于根据所使用的gnn模型以及其数据集,生成所需的功能配置参数以及特征向量矩阵、邻接矩阵,并控制切片大小对特征向量矩阵、邻接矩阵进行切片处理;
5、所述的特征矩阵缓存模块,用于缓存通过切片处理后的特征向量矩阵有效值;
6、所述的邻接矩阵缓存模块,用于缓存通过切片处理后的邻接矩阵有效值;
7、所述的堵塞缓解阵列,按照堵塞缓解策略将邻接矩阵有效值传输到配对阵列;
8、所述的配对阵列获取堵塞缓解阵列传输的邻接矩阵有效值,和特征矩阵缓存模块传输的特征向量矩阵有效值,将邻接矩阵有效值和特征向量矩阵有效值按照一定的顺序输入乘法阵列中;
9、所述的乘法阵列根据接收到的邻接矩阵有效值和特征向量矩阵有效值进行乘法处理,并输出部分聚合结果。
10、优选地,所述的邻接矩阵有效值通过切片处理后,先进行coo编码再输入邻接矩阵缓存模块;所述的coo编码将邻接矩阵有效值通过其行、列、数值三个部分来表示;邻接矩阵的行、列、数值一起传输给堵塞缓解阵列;
11、特征矩阵缓存模块中将配对阵列所需的特征向量矩阵的列单独存储,特征向量矩阵的行和数值在乘法阵列中单独进行存储和调用。
12、优选地,所述的配对阵列包括若干个配对单元组,每个配对单元组包括若干个串联的配对单元;还通过配对控制器将串联的多个配对单元与乘法阵列中的乘法单元相连接;
13、在配对单元中对配对结果进行计数,得到堵塞情况与是否拥有有效值;并采用二分法搜索每份配对结果中最高和最低的有效位,通过比较所得结果判断是否存在两个不同的有效值;将配对结果的最高和最低的有效位置零后,再进行线与获得是否拥有超过两个有效值。
14、在一个具体的实施例中,还包括配对分组控制器、阵列分组控制器;
15、所述的配对分组控制器根据不同gnn模型以及其数据集的预处理与乘法阵列中的乘法单元实现情况,对配对阵列中的配对单元进行分组,使并联的不同配对单元能对不同的邻接矩阵片进行计算,且串联的配对单元也能将输出结果分配到对应乘法单元的乘法器中;
16、所述的阵列分组控制器根据配对分组控制器的分组情况对堵塞缓解阵列进行分组,使得数据传输过程中不同组的数据不相互传递与干扰。
17、再进一步地,所述的堵塞缓解阵列采用深度为log2(aefftp)-1,宽度为aefftp的堵塞缓解阵列;其中处于配对单元中的缓存寄存器为深度0,缓存寄存器与深度为log2(aefftp)-2的堵塞缓解阵列中的堵塞单元相连;并获取从堵塞单元向缓存寄存器的方向传输堵塞信息,获取从缓存寄存器向堵塞单元传输有效值信息;
18、将位置为(depth_m,position_n)(depth_m,position_n±2m),(depth_m-1,position_n),(depth_m-1,position_n±2m)的四个堵塞单元分成一组,同一组中两个深度较浅的堵塞单元根据堵塞缓解策略自由传输到两个深度较深的堵塞单元中;
19、同时,同一深度的一个堵塞单元(depth_m,position_n),在每个时钟周期结束时,将自己的缓存寄存器的内容传输到另一个堵塞单元(depth_m,position_n+2m+1)中,从而使任意堵塞单元的有效值能传输到任意配对模块中,最大程度缓解堵塞。
20、再进一步地,所述的邻接矩阵缓存将邻接矩阵有效值输入堵塞缓解阵列时,在不打乱输入数据前后顺序的同时,将邻接矩阵有效值输入到同一位置中最靠近配对单元的空闲的堵塞缓解单元中;
21、为了提高切换特征有效值输入和换片的效率,在邻接矩阵有效值输入堵塞缓解阵列时携带特征值编号,用来索引最高不同片或不同批的特征向量矩阵有效值输入,使得在最靠近邻接矩阵缓存模块的堵塞缓存阵列有有效值时,或者在遍历完一片标记为a_sign=x的邻接矩阵,且堵塞缓解阵列中存在标记为x+1的数据时,发生堵塞。
22、再进一步地,所述的乘法单元,在接收到配对单元的输出后,先对邻接矩阵有效值进行缓存,此时根据特征值编号索引对应的特征寄存器并使用配对结果最高和最低有效值位置当作地址进行索引,得到所需的特征向量矩阵有效值;在下个周期与邻接矩阵有效值进行乘法后,与邻接矩阵有效值的列和特征向量矩阵有效值的行合并成一个coo编码的部分聚合结果有效值,用于输送到后面的组合模块中。
23、优选地,所述的邻接矩阵有效值按照先列坐标从小到大,再行坐标从小到大的顺序存入邻接矩阵缓存模块;
24、特征向量矩阵在每一小片邻接矩阵遍历完毕后输出新的有效值;根据数据集特点,若出现切片内的有效值数小于所设置的阈值时,则调整切片大小,使每个切片的有效值与所设定的阈值的差值最小;若切片内的有效值数大于所设置的阈值,则输入的有效值数根据所设定的阈值大小进行调整,使同一切片每个周期输入的数据量变化量最小。
25、进一步地,当每周期输入的邻接矩阵有效值数为aefftp,对每个邻接矩阵有效值分配dsppera个乘法单元时,如果乘法单元利用率是满的,则完成单层聚合操作时间为:
26、
27、其中,agg_opera_num是单层聚合阶段的配对总数,clkaggregration代表一个邻接有效值从输入到输出所需的时钟周期,clk_period代表每个时钟周期所需的时间。
28、再进一步地,由于单层聚合阶段的配对总数难以直接得到,因此通过计算得出单层配对操作所需的最小时钟周期clkcompare来估算单层聚合操作的最小时间,具体如下:
29、在配对阵列中,每一次输入的特征向量矩阵有效值数为fefftp时,每一组aefftp个邻接矩阵有效值数与fefftp个特征有效值进行配对时都至少需要花费一个周期:
30、设:ceil(x)是向上取整函数
31、邻接矩阵中顶点维度大小、行切片大小和列切片大小分别为a_size,a_rowsize和a_colsize时,得到:
32、邻接矩阵中行切片数:
33、邻接矩阵中列切片数:
34、特征向量矩阵中特征维度大小、行切片大小和列切片大小分别为fea_size,fea_rowsize和fea_colsize时,得到:
35、fea_rowsize=a_colsize
36、特征向量矩阵中列切片数:
37、如果邻接矩阵缓存的宽度能存下aefftp个有效值,第m片邻接矩阵有效值数为a_effnumm,则其深度为:
38、
39、如果特征向量矩阵缓存的宽度能存下fefftp个有效值,第n片特征向量矩阵有效值数为fea_effnumn,则其深度为:
40、
41、所以单层配对操作所需时钟周期clkcompare为:
42、
43、单层聚合操作时间至少为:
44、taggregration_min=(clkcompare+clkaggregration)×clk_period。
45、本发明的有益效果如下:
46、1)本发明充分利用了邻接矩阵极度稀疏和图神经网络满足乘法结合律的特性,通过改变数据切片大小,遍历顺序和每周期输出数据量,利用一种有堵塞缓解策略的配对阵列和配套的堵塞缓解阵列,使输入乘法阵列的有效值尽可能的多,使得乘法阵列利用率尽可能的高。在相同计算量的情况下比起其他方案只需要更少的乘法器数量。
47、2)本发明的访存具有规则性,每次从邻接矩阵缓存模块、特征向量矩阵缓存模块中读取的邻接矩阵和特征向量矩阵有效值都是充分利用带宽且顺序遍历的,这也使得本发明在不同数据集上具有泛用性,且无需进行顶点重排等复杂数据预处理的情况下,能根据切片大小输出组合模块所需的结果。
- 还没有人留言评论。精彩留言会获得点赞!