一种人物标注与故事情节自动提取的方法及系统
本发明涉及自然语言处理,尤其涉及一种人物标注与故事情节自动提取的方法及系统。
背景技术:
1、故事是以说服、记录和娱乐他人为主要目的,以情节和人物的叙述为主要内容,以冲突为抓手,以叙事和细节描写为手段,为目标受众提供的一种叙事性信息产品。故事强调的是信息产品的言简意赅、情节曲折、冲突单一、细节生动和易懂易记等特点,进而达到提高信息产品的可记忆和可认知的目的。相对于小说,故事的篇幅较短,一般控制在5000字以内,故事的叙述一般以情节的展开为主进行,情节是故事叙述的主线条。故事的情节具有曲折性,但不同故事的情节有规律可循。例如,每个故事的情节包括开端、发展、高潮、结局等内容。
2、故事情节的自动化提取一方面可以为快速理解故事提供依据。情节是故事所涉及的“事或事件(events)”的组织方式。通常,描述事件的故事线(storylines)称之为情节(plots)。研究者发现,故事情节是相对固定的,常见的故事模型有三种:德国剧作家gustavfreytag提出的故事叙述的金字塔结构(freytag's pyramid)、美国作家joseph campbell教授等提出的英雄之旅(hero's journey)结构、kurt vonnegut曾提出了著名的“男孩追到女孩型(boy gets girl)故事情节模型”。故事情节的自动化提取可以为故事受众提供故事线条,为快速认识和深入研究故事内容提供依据。
3、故事情节的自动提取另一方面还为计算机自动生成数据故事提供依据和评价指标。通过故事情节的提取,可以分析基于大数据分析自动生成数据故事是否符合一般故事的规律,而且还可以找到符合该故事的更多的故事大数据,进而通过相关故事精调和优化数据故事,达到生成更好故事的目的。
4、在故事情节自动化方面,现有研究关注的是如何自动化生成一则新的故事(含其情节),而对如何自动提取故事情节的研究仍属尚未开展的领域。在故事情节的提取方面,相关研究停留在如何人工识别和优化故事情节之上,而故事情节的自动提取的方法和工具尚未出现。因此,如何实现故事情节自动提取成为当前需要解决的技术问题。
技术实现思路
1、针对上述问题,本发明的目的是提供一种人物标注与故事情节自动提取的方法及系统,用以实现故事情节自动提取及标注。
2、为实现上述目的,本发明采取以下技术方案:
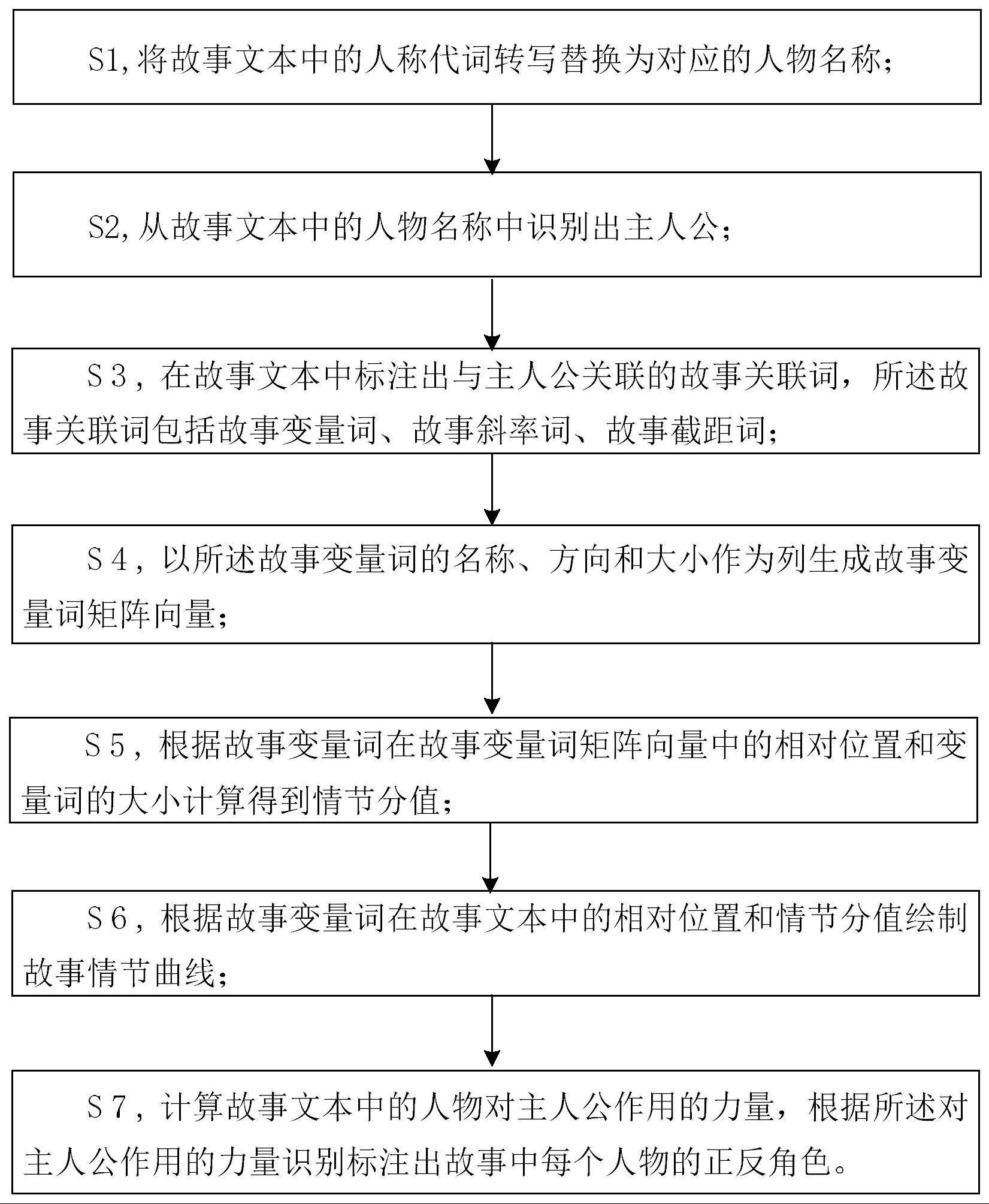
3、本发明的一个方面在于提供一种人物标注与故事情节自动提取的方法,该方法包括以下步骤:
4、从故事文本中获取与主人公关联的故事关联词,所述故事关联词至少包括故事变量词;
5、以所述故事变量词的名称、方向和大小作为列生成故事变量词矩阵向量;
6、根据故事变量词在故事变量词矩阵向量中的相对位置和故事变量词的大小计算得到情节分值;
7、根据故事变量词在故事文本中的相对位置和情节分值绘制故事情节曲线。
8、优选地,所述从故事文本中获取与主人公关联的故事关联词,包括:
9、将故事文本中的人称代词转写替换为对应的人物名称;
10、从故事文本中的人物名称中识别出主人公;
11、在故事文本中标注出与主人公关联的故事关联词。
12、优选地,所述将故事文本中的人称代词转写替换为对应的人物名称,具体包括:从故事文本的第一句开始,按照就近原则将故事文本中的人称代词替换成对应的人物名称;其中,所述人称代词包括中英文的第一人称、第二人称、第三人称代词。
13、优选地,所述从故事文本中的人物名称中识别出主人公,具体包括:统计获得每个人物名称的出现频次,从按频次降序排列的人物名称中选择出一个或多个人物名称设为主人公。
14、优选地,所述在故事文本中标注出与主人公关联的故事关联词,具体包括:
15、从故事文本中筛选得到故事变量词、故事斜率词、故事截距词,其中,故事变量词为以主人公为主语或宾语的谓语动词;故事斜率词为修饰谓语的副词;故事截距词为修饰主人公的形容词;
16、对筛选的故事变量词、故事斜率词、故事截距词进行标注,标注内容包括方向和程度信息;
17、方向信息是指相对于主人公的方向,对主人公有利的称之为“正方向”,对主人公不利的称之为“负方向”,与主人公无任何利害关系的称之为“无方向”;
18、程度信息包括“强级”和“弱级”两个等级。
19、优选地,所述根据故事变量词在故事变量词矩阵向量中的相对位置和故事变量词的大小计算得到情节分值,具体为:以故事变量词在变量词矩阵向量中的相对位置为分割线,将分割线之前的反向词的占比和分割线之后的反向词的占比之差作为系数,将该系数与所述故事变量词的大小相乘得到该故事变量词的情节分值。
20、优选地,所述根据故事变量词在故事文本中的相对位置和情节分值绘制故事情节曲线,具体包括:在笛卡尔坐标系中,以故事变量词在故事文本中的相对位置为横坐标,以故事变量词的情节分值为纵坐标,以横纵坐标对应的点表示故事变量词的方式绘制故事情节曲线。
21、优选地,所述故事变量词在故事文本中的相对位置为:故事变量词在故事文本中出现的位置除以故事总有效词数。
22、优选地,所述方法进一步包括:计算故事文本中的人物对主人公作用的力量,根据所述对主人公作用的力量识别标注出故事中每个人物的正反角色,具体为:
23、第i个人物对主人公作用的力量charactersi按照如下公式计算为:
24、
25、其中,wi表示故事斜率词,xi表示故事变量词,bi表示故事截距词;
26、判断第i个人物对主人公作用的力量charactersi是否大于零,若大于零则将该人物标识为对主人公而言的正面角色,若小于零则该人物标识为对主人公而言的负面角色,若等于零则表示该人物为对主人公而言无利害关系。
27、本发明的另一个方面还提供一种人物标注与故事情节自动提取的系统,该系统包括:
28、关联词识别模块,用于从故事文本中获取与主人公关联的故事关联词,所述故事关联词至少包括故事变量词;
29、向量生成模块,用于以所述故事变量词的名称、方向和大小作为列生成故事变量词矩阵向量;
30、分值计算模块,用于根据故事变量词在故事变量词矩阵向量中的相对位置和变量词的大小计算得到情节分值;
31、绘图模块,用于根据故事变量词在故事文本中的相对位置和情节分值绘制故事情节曲线。
32、本发明由于采取以上技术方案,其具有以下优点:
33、(1)灵活性强。本发明通过动词谓语方向的设置,将多主题视角问题转换为主人公单一主体视角问题,不仅可以支持多人物场景,而且还可以支持人物之间关系不确定的故事等复杂故事的自动处理。
34、(2)经济性。本发明属于轻量级应用,不需要大量的训练数据和计算资源,可以对单篇文献进行分析。
35、(3)客观性。本发明中对情节的计算基于故事上下文中的文本分析,可以客观的描述情节变化,能够如实表现出故事叙述者的叙述能力。
36、(4)可扩展性强。本发明不仅可以用于小数据,也可以用于大数据,而且还支持深度学习,可以将深度学习引入本发明之中。
37、(5)全自动化。本发明中的故事情节的提取为全自动过程,不需要人工干预。
38、(6)故事创作者用词习惯的适应性强。在计算故事词性大小计算时,仅对故事中出现的同性词进行比较,分为强/弱级两种,充分考虑到了创作者用词上的习惯性特点和不足。
39、本发明的人物标注与故事情节自动提取的方法及系统可以广泛用于故事情节的提取、故事类型的识别以及故事人物的标注等领域。
- 还没有人留言评论。精彩留言会获得点赞!