模型训练方法、装置、电子设备及存储介质与流程
本技术涉及眼底图像处理,尤其涉及一种模型训练方法、装置、电子设备及存储介质。
背景技术:
1、早产儿视网膜病变(rop)是早产儿视网膜发育过程中的一种增殖性疾病。它仍然是全世界儿童失明的一个主要原因。早产儿的眼科检查需要频繁和密切的监测,导致大量的人工图像阅读工作量。然而,在临床上,对眼底病1、2、3期的诊断存在主观性和诊断差异。如果不能及时发现和治疗rop,就会导致晚期rop,从而导致视力低下甚至失明。此外,经验丰富的小儿眼科医生供不应求,大部分集中在大城市或大型医疗中心。居住在偏远地区的婴儿患早产儿必须长途跋涉才能转诊,这就延误了治疗。因此,远程医疗和计算机辅助的rop眼底图像阅读具有重要意义。
2、目前,在rop图像分析领域,许多深度学习模型也被提出用于计算机辅助筛查和诊断。然而,深度学习方法往往需要大量的注释数据进行模型训练。在临床场景中,注释大量的数据往往是费时费力的,即使是有经验的医生也是如此。对于rop眼底图像的注释,临床医生通常根据rop眼底图像中脊柱的形状和大小来确定rop的阶段。4期或5期的rop眼底图像很容易区分,而正常的眼底图像、1期rop图像或2期rop图像由于处于疾病的早期阶段,疾病不是很明显,可能会被临床医生误解,从而增加临床医生的负担。
技术实现思路
1、本技术实施例提供一种模型训练方法、装置、电子设备及存储介质,以解决现有技术中深度学习方法需要大量的注释数据费时费力,且对于早期阶段的眼底图像可能会被临床医生误解导致注释错误,增加临床医生的负担的问题。
2、为了解决上述技术问题,本技术实施例是这样实现的:
3、第一方面,本技术实施例提供了一种模型训练方法,所述方法包括:
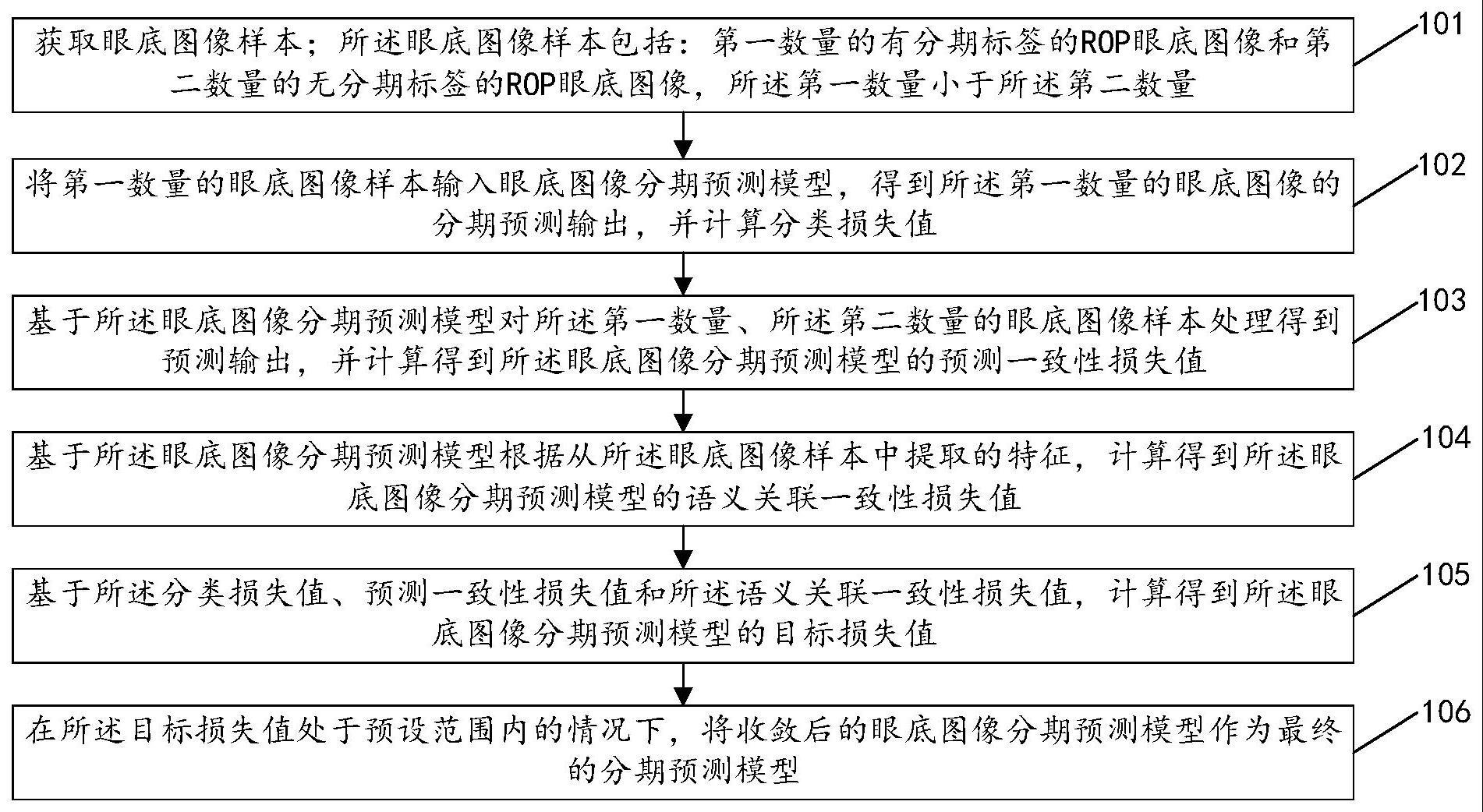
4、获取眼底图像样本;所述眼底图像样本包括:第一数量的有分期标签的rop眼底图像和第二数量的无分期标签的rop眼底图像,所述第一数量小于所述第二数量;
5、将第一数量的眼底图像样本输入眼底图像分期预测模型,得到所述第一数量的眼底图像的分期预测输出,并计算分类损失值;
6、基于所述眼底图像分期预测模型对所述第一数量、所述第二数量的眼底图像样本处理得到预测输出,并计算得到所述眼底图像分期预测模型的预测一致性损失值;
7、基于所述眼底图像分期预测模型根据从所述眼底图像样本中提取的特征,计算得到所述眼底图像分期预测模型的语义关联一致性损失值;
8、基于所述分类损失值、预测一致性损失值和所述语义关联一致性损失值,计算得到所述眼底图像分期预测模型的目标损失值;
9、在所述目标损失值处于预设范围内的情况下,将收敛后的眼底图像分期预测模型作为最终的分期预测模型。
10、可选地,所述获取眼底图像样本,包括:
11、获取原始眼底图像样本;
12、将所述原始眼底图像样本的尺寸调整为设定尺寸,得到处理后的眼底图像样本;
13、对所述处理后的眼底图像样本执行数据增强操作,得到所述眼底图像样本。
14、可选地,所述眼底图像分期预测模型包括:第一分期预测子模块和第二分期预测子模型,所述第一分期预测子模型包括:第一特征提取层和具有n个输出单元的第一全连接层,所述第二分期预测子模型包括:第二特征提取层和具有n个输出单元的第二全连接层,n为正整数,
15、所述基于所述眼底图像分期预测模型对所述第一数量、所述第二数量的眼底图像样本处理得到预测输出,包括:
16、对所述无分期标签的rop眼底图像施加第一随机噪声,得到第一眼底图像样本;
17、对所述无分期标签的rop眼底图像施加第二随机噪声,得到第二眼底图像样本;
18、将所述第一眼底图像样本输入至所述第一分期预测子模型,并将所述第二眼底图像样本输入至所述第二分期预测子模型;
19、调用所述第一特征提取层从所述第一眼底图像样本中提取高层语义特征,并调用所述第一全连接层基于所述高层语义特征对所述第一眼底图像样本进行分期预测,并输出所述第一眼底图像样本的第一分期预测标签;
20、调用所述第二特征提取层从所述第二眼底图像样本中提取高层语义特征,并调用所述第二全连接层基于所述高层语义特征对所述第二眼底图像样本进行分期预测,并输出所述第二眼底图像样本的第二分期预测标签。
21、可选地,所述计算得到所述眼底图像分期预测模型的预测一致性损失值,包括:
22、获取所述第一分期预测子模型的第一模型参数,及所述第二分期预测子模型的第二模型参数;
23、基于所述第一模型参数、所述第二模型参数、所述第一数量、所述第二数量、所述第一随机噪声和所述第二随机噪声,计算得到所述第一分期预测子模型与所述第二分期预测子模型之间的所述预测一致性损失值。
24、可选地,所述基于所述眼底图像分期预测模型根据从所述眼底图像样本中提取的特征,计算得到所述眼底图像分期预测模型的语义关联一致性损失值,包括:
25、获取所述第一眼底图像样本和所述第二眼底图像样本的高层语义特征之间的相似度;
26、基于所述第一模型参数、所述第二模型参数、所述第一数量、所述第二数量、所述第一随机噪声、所述第二随机噪声、所述相似度,计算得到所述第一分期预测子模型与所述第二分期预测子模型之间的所述语义关联一致性损失值。
27、可选地,所述基于所述分类损失值、所述预测一致性损失值和所述语义关联一致性损失值,计算得到所述眼底图像分期预测模型的目标损失值,包括:
28、基于所述分类损失值、所述预测一致性损失值、所述语义关联一致性损失值和损失平衡系数,计算得到所述目标损失值。
29、第二方面,本技术实施例提供了一种模型训练装置,所述装置包括:
30、图像样本获取模块,用于获取眼底图像样本;所述眼底图像样本包括:第一数量的有分期标签的rop眼底图像和第二数量的无分期标签的rop眼底图像,所述第一数量小于所述第二数量;
31、分类损失计算模块,用于将第一数量的眼底图像样本输入眼底图像分期预测模型,得到所述第一数量的眼底图像的分期预测输出,并计算分类损失值;
32、预测一致损失计算模块,用于基于所述眼底图像分期预测模型对所述第一数量、所述第二数量的眼底图像样本处理得到预测输出,并计算得到所述眼底图像分期预测模型的预测一致性损失值;
33、语义一致损失计算模块,用于基于所述眼底图像分期预测模型根据从所述眼底图像样本中提取的特征,计算得到所述眼底图像分期预测模型的语义关联一致性损失值;
34、目标损失值计算模块,用于基于所述分类损失值、预测一致性损失值和所述语义关联一致性损失值,计算得到所述眼底图像分期预测模型的目标损失值;
35、分期预测模型获取模块,用于在所述目标损失值处于预设范围内的情况下,将收敛后的眼底图像分期预测模型作为最终的分期预测模型。
36、可选地,所述图像样本获取模块包括:
37、原始图像样本获取单元,用于获取原始眼底图像样本;
38、处理图像样本获取单元,用于将所述原始眼底图像样本的尺寸调整为设定尺寸,得到处理后的眼底图像样本;
39、眼底图像样本获取单元,用于对所述处理后的眼底图像样本执行数据增强操作,得到所述眼底图像样本。
40、可选地,所述眼底图像分期预测模型包括:第一分期预测子模块和第二分期预测子模型,所述第一分期预测子模型包括:第一特征提取层和具有n个输出单元的第一全连接层,所述第二分期预测子模型包括:第二特征提取层和具有n个输出单元的第二全连接层,n为正整数,
41、所述分类损失计算模块包括:
42、第一图像样本获取单元,用于对所述无分期标签的rop眼底图像施加第一随机噪声,得到第一眼底图像样本;
43、第二图像样本获取单元,用于对所述无分期标签的rop眼底图像施加第二随机噪声,得到第二眼底图像样本;
44、眼底图像样本输入单元,用于将所述第一眼底图像样本输入至所述第一分期预测子模型,并将所述第二眼底图像样本输入至所述第二分期预测子模型;
45、第一预测标签输出单元,用于调用所述第一特征提取层从所述第一眼底图像样本中提取高层语义特征,并调用所述第一全连接层基于所述高层语义特征对所述第一眼底图像样本进行分期预测,并输出所述第一眼底图像样本的第一分期预测标签;
46、第二预测标签输出单元,用于调用所述第二特征提取层从所述第二眼底图像样本中提取高层语义特征,并调用所述第二全连接层基于所述高层语义特征对所述第二眼底图像样本进行分期预测,并输出所述第二眼底图像样本的第二分期预测标签。
47、可选地,所述预测一致损失计算模块包括:
48、模型参数获取单元,用于获取所述第一分期预测子模型的第一模型参数,及所述第二分期预测子模型的第二模型参数;
49、预测一致损失计算单元,用于基于所述第一模型参数、所述第二模型参数、所述第一数量、所述第二数量、所述第一随机噪声和所述第二随机噪声,计算得到所述第一分期预测子模型与所述第二分期预测子模型之间的所述预测一致性损失值。
50、可选地,所述语义一致损失计算模块包括:
51、语义相似度获取单元,用于获取所述第一眼底图像样本和所述第二眼底图像样本的高层语义特征之间的相似度;
52、语义一致损失计算单元,用于基于所述第一模型参数、所述第二模型参数、所述第一数量、所述第二数量、所述第一随机噪声、所述第二随机噪声、所述相似度,计算得到所述第一分期预测子模型与所述第二分期预测子模型之间的所述语义关联一致性损失值。
53、可选地,所述目标损失值计算模块包括:
54、目标损失值计算单元,用于基于所述分类损失值、所述预测一致性损失值、所述语义关联一致性损失值和损失平衡系数,计算得到所述目标损失值。
55、第三方面,本技术实施例提供了一种电子设备,包括:
56、存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述计算机程序被所述处理器执行时实现上述任一项所述的模型训练方法。
57、第四方面,本技术实施例提供了一种可读存储介质,当所述存储介质中的指令由电子设备的处理器执行时,使得电子设备能够执行上述任一项所述的模型训练方法。
58、在本技术实施例中,获取眼底图像样本,眼底图像样本包括:第一数量的有分期标签的rop眼底图像和第二数量的无分期标签的rop眼底图像,第一数量小于第二数量。将第一数量的眼底图像样本输入眼底图像分期预测模型,得到第一数量的眼底图像的分期预测输出,并计算分类损失值。基于眼底图像分期预测模型对第一数量、第二数量的眼底图像样本处理得到预测输出,并计算得到眼底图像分期预测模型的预测一致性损失值。基于眼底图像分期预测模型根据从眼底图像样本中提取的特征,计算得到眼底图像分期预测模型的语义关联一致性损失值。基于分类损失值、预测一致性损失值和语义关联一致性损失值,计算得到眼底图像分期预测模型的目标损失值。在目标损失值处于预设范围内的情况下,将收敛后的眼底图像分期预测模型作为最终的分期预测模型。本技术实施例可同时利用少量带标签rop眼底图像和大量无标签rop眼底图像来进行rop自动分期,有助于缓解医生的标注负担与成本。同时,通过预测一致性损失来充分从无标签数据中挖掘有用的判别信息,从而大大提升深度学习模型的分类性能。通过疾病语义关联一致性损失,额外考虑到了rop不同时期疾病特征的演化关系,提高了模型的识别准确率。
59、上述说明仅是本技术技术方案的概述,为了能够更清楚了解本技术的技术手段,而可依照说明书的内容予以实施,并且为了让本技术的上述和其它目的、特征和优点能够更明显易懂,以下特举本技术的具体实施方式。
- 还没有人留言评论。精彩留言会获得点赞!