一种基于多视图三维重建的自动驾驶数字孪生场景构建方法和系统
本发明涉及计算机视觉领域和自动驾驶,具体涉及一种基于多视图三维重建的自动驾驶数字孪生场景构建方法和系统。
背景技术:
1、近些年,受单个车辆的感知范围与能力的限制,自动驾驶逐渐朝着以数字孪生为核心的智能网联化方向发展。自动驾驶数字孪生技术基于现实场景中的传感数据,在三维虚拟环境中构建高精度的交通场景。重建的三维虚拟场景不仅为自动驾驶仿真测试提供完整、充足、可编辑的场景,还为自动驾驶算法优化提供大量驾驶数据,更为高精度地图的自动化制作提供了高效方案。自动驾驶数字孪生技术通过将现实交通场景元素映射到虚拟空间,建立起物理世界和虚拟世界之间的联系。在虚拟世界中,人们可以全过程、全要素的掌控自动驾驶中的各个环节,并依据一定的逻辑和规则自由切换时空,低成本、高效率地研究自动驾驶中的关键技术,进而驱动现实世界中自动驾驶技术的发展。
2、自动驾驶三维虚拟场景重建的本质是交通场景三维几何结构的感知和恢复。相较于激光雷达扫描方案而言,基于视觉的方法从二维投影中分析多视图几何关系与内在联系,具有成本低廉、数据获取方便、重建模型稠密、纹理丰富等优点。传统的colmap多视图三维重建算法基于经典计算几何理论,利用归一化互相关匹配法进行视图间光学一致性的度量,利用patchmatch进行深度传递。colmap算法可解释性强,但是深度图计算时间长,难以应用在自动驾驶这类大规模室外场景中。近些年,随着深度学习的发展,深度神经网络表现出强大提取图像特征的能力。许多研究将多视图和对应的相机位姿输入深度神经网络,实现端到端的多视图立体匹配与深度图估计。mvsnet提出可微的单应变换构造代价体,并使用多尺度的类unet结构对聚合后的代价体进行三维卷积,得到平滑后的概率体,并据此估计每张图像的深度图。cvp-mvsnet通过设计金字塔结构,由粗到细地优化深度图质量;fast-mvsnet采用稀疏代价体构建方法提高了深度图估计的速度。这些算法较传统colmap算法而言,极大地减少了深度图估计时间。
3、尽管现有技术在室内场景数据集上取得了不错的效果,但是在自动驾驶室外大规模场景中面临着较大挑战,主要包括:
4、(1)现有技术在结构复杂的自动驾驶场景中存在特征提取不充分的问题,导致重建精度不足。自动驾驶室外场景具有重建范围广、场景结构复杂、光线变化大等特点,场景中低纹理和纹理丰富的区域并存,现有技术采用固定的卷积核大小提取特征,忽视了纹理复杂区域丰富的场景特征;此外,现有技术赋予特征通道相等的权重,未能很好地过滤掉噪声数据,导致模型重建精度不足。
5、(2)现有技术在自动驾驶大规模室外场景重建中显存空间占用过大。在自动驾驶大规模室外场景中,场景中不同物体与相机之间的距离差异较大,深度图的假设深度范围必须设置得较大;此外,为了获得更佳的重建效果,图像分辨率也会设置得较大,这直接导致所构建的代价体的体积变大,进而网络模型在推理时占用大量的显存空间。例如,现有技术mvsnet方法在图像宽度设置为1200像素、高度800像素、假设深度范围设置为1024时,算法推理阶段会占用约29gb的显存空间,难以在普通消费级显卡上运行。
6、(3)输入的多视角图像的质量直接影响着重建场景的效果,现有技术使用的数据集大多围绕某一物体或某栋建筑进行采集,这种采集方式不适用于自动驾驶大规模室外场景。为此,需要提出一种针对自动驾驶场景室外图像数据采集与数据处理方案。
技术实现思路
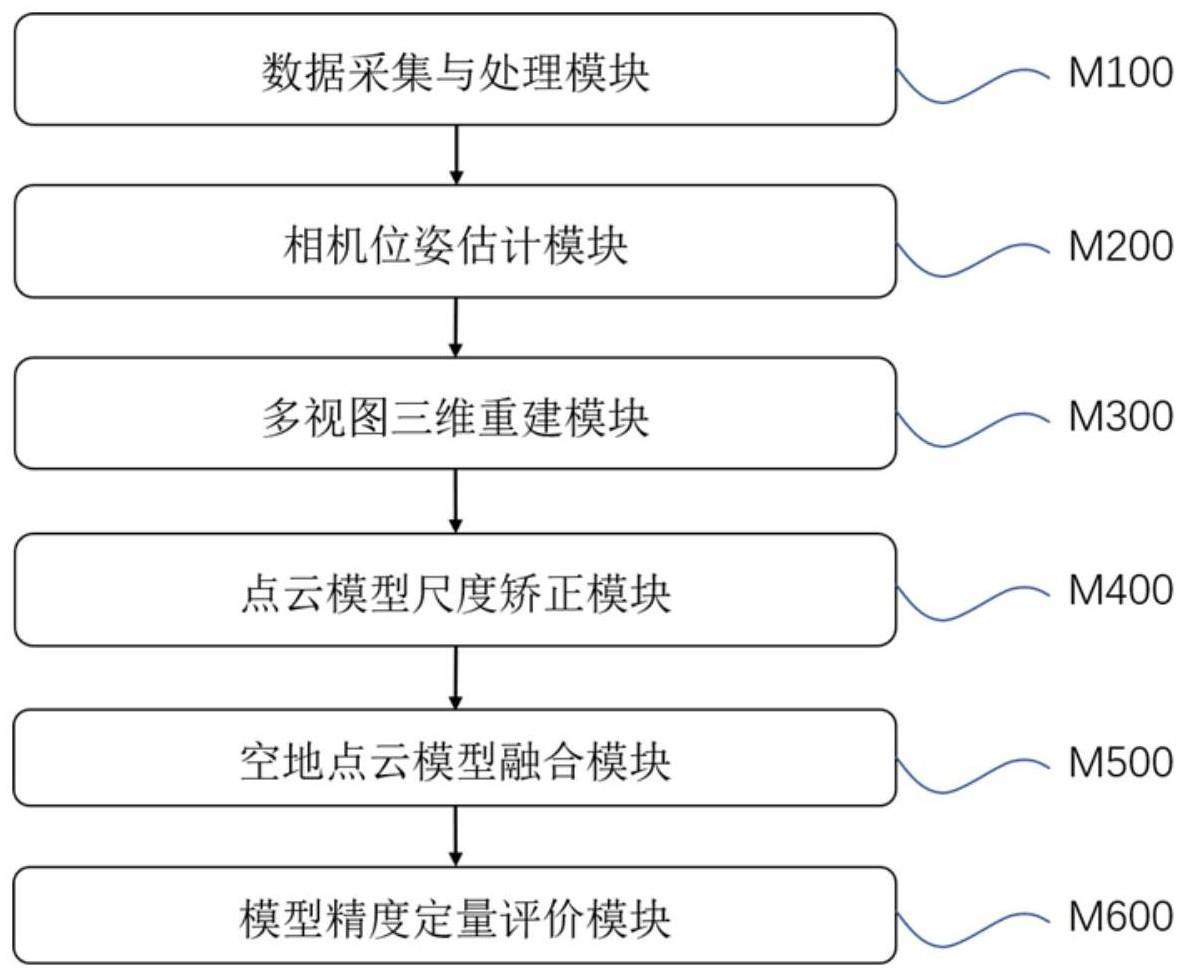
1、为解决现有技术中存在的上述问题,本发明提供了一种基于多视图三维重建的自动驾驶数字孪生场景构建方法和系统。本发明提出的自动驾驶场景多视图三维重建方法中的特征提取模块,通过改变卷积核大小方式进一步提取纹理复杂区域的特征,并赋予不同特征通道不同的权重。此外,提取得到的特征图经单应变换形成多个特征体并聚合成一个代价体,该方法将代价体沿深度维度方向进行切片,并使用时空递归神经网络对切片序列进行正则化处理,在降低自动驾驶室外大规模场景中模型推理阶段占用的显存空间大小的同时,保留了切片之间的关联。另外,本发明还提供了一种基于无人机的自动驾驶室外场景图像采集方案,能有效且全面地采集多视图三维重建方法所需要的图像数据。最后,本发明还提出了一种基于多视图三维重建的自动驾驶数字孪生场景构建系统,包括数据采集与处理、相机位姿估计、多视图三维重建、点云模型尺度矫正、空地点云模型融合、模型精度定量评价六个模块。
2、本发明的目的是通过以下技术方案来实现的:一种基于多视图三维重建的自动驾驶数字孪生场景构建系统,所述自动驾驶数字孪生场景构建系统包括:
3、数据采集与处理模块(m100),用于对自动驾驶场景的多视角图像进行采集和数据预处理,并将处理后的图像数据划分为若干组;
4、相机位姿估计模块(m200),用于将采集的多视角图像作为输入,输出拍摄每张图像的相机对应的位置和姿态,从而获取相机内外参数序列;
5、多视图三维重建模块(m300),用于构建网络模型,并通过网络模型提取多视角图像的特征图序列,并结合相机内外参数序列构建代价体,将代价体沿深度维度方向进行切片,然后将切片后的代价体进行处理得到概率体,并根据概率体估计多视角图像的深度图,最后融合深度图得到场景三维稠密点云;
6、点云模型尺度矫正模块(m400),用于将模块(m100)中处理得到的三个特征点及其组成三角形的边长作为输入参数,构建虚拟三维空间中等比例的三角形面片,并在多视图三维重建模块(m300)得到的场景三维稠密点云中,找到三个对应特征点的位置,将虚拟点云模型中的三个特征点与三角形面片中对应的三个点同时配准,对三维稠密点云进行尺度变换;
7、空地点云模型融合模块(m500),用于将数据采集与处理模块(m100)中无人机采集的图像重建得到的三维稠密点云划分为空中点云模型,将其它组图像重建得到的三维稠密点云划分为地面点云模型;本模块将若干个地面点云模型配准到空中点云模型,形成最终的自动驾驶数字孪生场景模型;
8、模型精度定量评价模块(m600),用于对自动驾驶场景三维模型的精度进行定量评测,判断自动驾驶场景三维模型的精度满足后续自动驾驶任务需求。
9、作为本发明的优选方案,所述数据采集与处理模块(m100)对数据进行采集和处理的方法包括以下步骤:
10、s201:划定待重建的自动驾驶场景范围;
11、s202:预设数据采集路线,使用无人机在固定的飞行高度按预设s型路线飞行,并在拍摄点拍摄场景图像;
12、s203:降低无人机飞行高度,围绕场景中的建筑物、采用八字绕飞的方式进行拍摄;
13、s204:对于道路旁边的建筑物、道路完全被树木遮挡的路段,使用手持拍摄设备,以环绕拍摄的方式采集数据;
14、s205:对收集的所有图像数据进行预处理:通过保留图像最中心区域的方式将图像尺寸调整为宽3000像素、高2250像素,然后将图像降采样到宽1600像素、高1200像素;
15、s206:将预处理后的图像数据划分为若干组,其中将步骤s202和步骤s203所采集的图像分为一组,作为第一组图像;将步骤s204中针对每一个建筑物或路段拍摄的图像单独分组;
16、s207:在每一组图像覆盖的现实场景中,选择三个最为明显的特征点,记录特征点的位置以及所构成三角形的毫米级精度边长。
17、作为本发明的优选方案,所述相机位姿估计模块(m200)包括检索匹配单元和增量式重建单元;所述检索匹配单元以多视角图像作为输入,寻找经过几何验证的、具有重叠区域的图像对,并计算空间中的同一点在这些图像对中两张图像上的投影;所述增量式重建单元用于输出拍摄每张图像的相机对应的位置和姿态。
18、更为优选的是,增量式重建单元输出拍摄每张图像的相机对应的位置和姿态的具体过程为:首先在多视角图像稠密位置选择一对初始图像对并配准;然后选择与当前已配准的图像之间配准点数量最多的图像;将新增加的视图与已确定位姿的图像集合进行配准,利用pnp问题求解算法估计拍摄该图像的相机位姿;之后对于新增加的已配准图像覆盖到的未重建出的空间点,三角化该图像并增加新的空间点到已重建出的空间点集合中;最后,对当前所有估计出的三维空间点和相机位姿进行一次光束平差法优化调整。
19、本发明还提供了一种上述自动驾驶数字孪生场景构建系统的场景构建方法,包括以下步骤:
20、s501:使用数据采集与处理模块(m100)对自动驾驶场景进行全方位感知,对采集后的多视角图像数据进行处理;
21、s502:将采集得到的多视角图像数据输入到相机位姿估计模块(m200),通过检索匹配与增量式重建方法估计出拍摄每张图像的相机对应的位置和姿态,获得相机内外参数序列
22、s503:将相机内外参数序列和数据采集与处理模块(m100)所采集的图像数据输入到多视图三维重建模块(m300)构建的网络模型中;利用网络模型对图像数据提取图像序列的特征图序列并根据相机内外参数序列和特征图序列构建特征体序列并聚合成一个代价体;将代价体沿深度维度方向进行切片,并通过网络模型同时处理每个切片及其前后相邻的两个切片,得到描述每一像素在不同深度上概率分布的概率体;
23、s504:将真实深度图中的有效深度值通过独热编码的方式调整为真实值体,真实值体作为有监督学习的标签;将概率体和真实值体输入原始网络模型,通过多轮训练的方式,使得概率体与真实值体之间的交叉熵损失函数值最小,得到训练好的网络模型;
24、s505:对于输入的多视角图像序列,其中的每一张图像经训练好的网络模型处理得到概率体,并将概率体调整为深度图;然后,对深度图序列进行过滤与融合,得到重建后的场景三维稠密点云;
25、s506:通过点云模型尺度矫正模块(m400)构建虚拟三维空间中等比例的三角形面片,将重建后的三维稠密点云中的三个特征点与三角形面片中对应点配准,对场景三维稠密点云进行尺度变换;
26、s507:通过空地点云模型融合模块(m500)将三维稠密点云划分为空中点云模型和地面点云模型;将若干个地面点云模型配准到空中点云模型,形成最终的自动驾驶数字孪生场景模型;并对重建的自动驾驶场景三维模型的精度进行定量评测,以保证其精度满足后续自动驾驶任务需求。
27、作为本发明的优选方案,步骤s503中特征图序列的获取具体为:通过网络模型学习到卷积核方向向量的偏移量,使得卷积核能适应不同纹理结构的区域,提取更为细致的特征;其次,将不同尺寸的特征图上采样到原输入图像大小,并将它们连接到一起组成一张具有32通道的特征图;然后,将每个特征通道的二维信息uc(i,j)压缩成一维实数zc,并进行两级全连接;最后,使用sigmoid函数将每个实数zc的范围限制在[0,1]范围内,使得特征图的每个通道具有不同的权重,削弱匹配过程中的噪声数据与无关特征;对每张输入图像均重复上述操作步骤,得到特征图序列
28、作为本发明的优选方案,步骤s503中代价体的聚合具体为:选择特征图序列中的一张图像作为参考特征图f1,其余特征图作为源特征图然后根据相机内外参数序列将所有的特征图通过单应变换投影到参考图像下的若干个平行平面上,构成n-1个特征体最后,通过聚合函数将特征体聚合成一个代价体。
29、作为本发明的优选方案,步骤s503中概率体的形成具体为:将代价体切成d个片,其中d是深度先验,表示深度值可以取0~d中的任意一个值;然后将代价体切片序列视为时间序列,送入网络模型中的时空递归神经网络进行正则化,时空递归神经网络使用st-lstm在时序(水平方向)和空域(垂直方向)上传递存储状态,保留切片序列之间的联系,减少概率体出现多峰值的情况;在水平方向上,某时刻的第一层单元接受上一时刻最后一层单元的隐藏状态和记忆状态,并在垂直方向上逐层传递;最后使用softmax归一化操作输出每一像素在深度d∈[0,d]处的概率值,形成概率体。
30、作为本发明的优选方案,步骤s505具体为:对每一张图像经训练好的网络模型推理得到的概率体进行argmax操作,得到深度图序列,并基于光度一致性准则和几何一致性准则过滤掉置信度低的深度图,最后通过公式p=dm-1k-1p将深度图融合成三维稠密点云;其中p是像素坐标,d是网络模型推理得到的深度值,p是世界坐标系下的三维坐标。
31、与现有技术相比,本发明具有以下有益技术效果:
32、(1)本发明提出了一种面向自动驾驶室外大规模场景的多视图三维重建方法。该方法通过子网络模型学习到卷积核方向向量的偏移量,进而在处理不同的图像部分时具有不同的卷积核大小,使得面对不同纹理复杂度的区域时具有不同的感受野,更能适应纹理复杂的区域。该方法通过对提取的特征图中的不同通道赋予不同的权重,增强了匹配过程中的重要特征,削弱了如噪声数据与无关特征,提高了特征提取的准确性与鲁棒性。本发明针对自动驾驶室外场景中场景结构复杂、低纹理和纹理丰富的区域并存的特点,提出了新的特征提取模块,克服了现有技术中在纹理复杂区域特征提取不足、受噪声数据影响大等问题,从而提升了自动驾驶场景模型重建精度。
33、(2)本发明提出的自动驾驶场景多视图三维重建方法将代价体沿深度维度方向进行切片,然后将切片序列加载到时空递归神经网络中,使得推理阶段显存占用空间的大小与假设深度范围d无关,进而网络模型可以用于对假设深度范围广的自动驾驶室外大规模场景的重建。本发明在使用st-lstm在水平和垂直方向上传递存储状态,降低了显存占用空间同时保留了切片序列之间的联系,并减少了现有技术中概率体出现多峰值的情况,提高了深度预测的准确率。
34、(3)本发明提出了一种面向自动驾驶场景的图像数据收集与数据处理方案,该方案通过计算图像重叠率的方式预设无人机飞行路线与拍摄点,并结合s型和八字绕飞的方式进行飞行拍摄,保证了收集的多视角图像的质量。此外,针对空中视角下部分车道被树木遮挡的问题,该方案还使用手持拍摄设备对地面附近的场景进行了图像数据采集,并对拍摄图像分组处理,为自动驾驶场景室外图像数据有效且全面地采集与数据处理提供了新的方案。
35、(4)本发明提出了一种基于多视图三维重建的自动驾驶数字孪生场景构建系统,该系统提供了自动驾驶数字孪生场景重建及精度评价的整个过程,包括数据采集与处理、相机位姿估计、多视图三维重建、点云模型尺度矫正、空地点云模型融合、模型精度定量评价模块。该系统能有效、全面地采集自动驾驶室外场景的图像数据,并估计拍摄这些图像的相机位置和姿态。此外,该系统能以较小的显存空间占用、更强的纹理复杂区域特征提取能力重建出自动驾驶场景的三维模型,并通过空地点云模型融合的方式提高了场景模型的完整性,还提供一种定量评估的方法对所重建场景模型精度进行评估。
- 还没有人留言评论。精彩留言会获得点赞!