一种面试场景下的相似问句检索机制的制作方法
本发明涉及面试场景,特别涉及一种面试场景下的相似问句检索机制。
背景技术:
1、现有的面试场景下的相似问句检索机制总共有两种技术,首先为文本聚类算法,这是一种根据不同问句之间的相似性,进行聚类。同样也是一种无监督的、探索型的方式。这类方法首先将句子进行向量化,然后根据向量之间的距离进行相似度计算,然后通过如k-means进行聚类。聚类结果中,处于同一个类别下的问句被视作相似问句,其次是文本相似度检索,该方法将所述语句作为查询语句,将历史面试的问句作为目标(标准句)进行匹配。将匹配度超过一定阈值的目标标准句作为检索结果,视作相似问句。这种思想广泛应用在智能外呼、智能客服等领域。
2、但文本聚类算法的主要问题是准确度低:由于聚类算法属于无监督学习的一种,相对于有监督学习而言,缺少了人类的先验知识,准确率不高。另外,很多句子仅仅是在形式上解决,但是语义千差万别,例如问句1:请问http和https有什么区别?问句2:请问kpi和okr有什么区别?这两个问句除了http、https、kpi、okr不一样,其它词完全一样。在进行聚类时容易被归为一类,由于面试场景是一个高度口语化的语境,会有大量口语化无意义词的出现。面试采用视频面试形式,由于网络传输原因,会出现字词的缺失。叠加上语音识别的准确率问题,如果直接聚类,会出现大量无意义类别和无意义问句,准确率极低
3、文本相似度检索的则同时存在准确率低和耗时长两个问题。首先,历史问句数量巨大,而且受到口语化字词、网络卡顿、语音识别准确率等因素影响,有大量无意义问句。直接对历史问句进行检索必然会匹配出大量无意义结果。其次考虑对q个问句进行检索,历史问句数量为h。由于需要逐一匹配并根据得分排序,时间复杂度为o(q×h)。
技术实现思路
1、(一)解决的技术问题
2、针对现有技术的不足,本发明提供了一种面试场景下的相似问句检索机制,解决了面试场景下,相似问题的检索和匹配的问题。
3、(二)技术方案
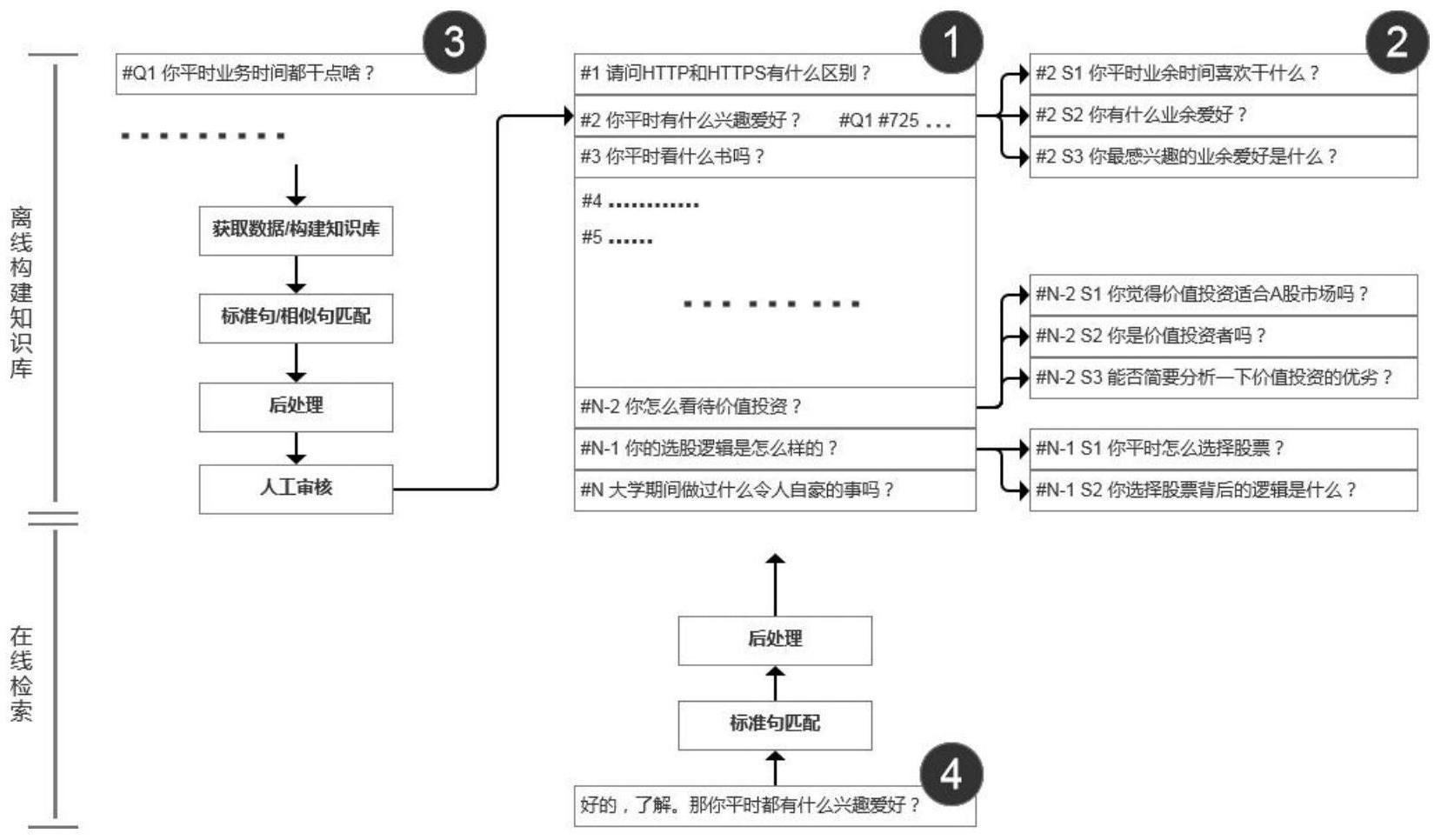
4、2.为实现以上目的,本发明通过以下技术方案予以实现:一种面试场景下的相似问句检索机制,包括先验的知识库的构建和离线的知识库构建,该方法包括以下步骤:
5、s1、标准问题构建;
6、s2、相似问句扩写;
7、s3、离线问句映射;
8、s4、在线问句检索。
9、优选的,所述相似问句扩写是基于标准问题构建的扩写,主要包含同一个标准问句的不同问法。
10、进一步,所述构件数据库通过调用服务接口输入问句query和知识库名称source,根据source判别是否存在知识库索引文件。
11、更进一步,所述离线问句映射分为获取数据/构建知识库、标准句匹配、后处理、人工审核四步组建。
12、更加进一步,所述对于时间复杂度而言,考虑q个问句,在h个历史问句中逐一匹配,时间复杂度为o(q×h)。
13、(三)有益效果
14、本发明提供了一种面试场景下的相似问句检索机制。具备以下有益效果:本发明将过往面试记录的问句通过一系列清洗和匹配操作,映射到了各标准问句上,从而构建了一个面试问句的知识库。该知识库不仅包含业界通常所说的标准句、相似句,还包含历史面试记录所匹配到的高质量问句。通过这种关联操作,可同时优化匹配准确率问题和耗时问题。
技术特征:
1.一种面试场景下的相似问句检索机制,其特征在于:包括先验的知识库的构建和离线的知识库构建,该方法包括以下步骤:
2.根据权利要求1所述的一种面试场景下的相似问句检索机制,其特征在于:所述相似问句扩写是基于标准问题构建的扩写,主要包含同一个标准问句的不同问法。
3.根据权利要求1所述的一种面试场景下的相似问句检索机制,其特征在于:所述构件数据库通过调用服务接口输入问句query和知识库名称source,根据source判别是否存在知识库索引文件。
4.根据权利要求1所述的一种面试场景下的相似问句检索机制,其特征在于:所述离线问句映射分为获取数据/构建知识库、标准句匹配、后处理、人工审核四步组建。
5.根据权利要求1所述的一种面试场景下的相似问句检索机制,其特征在于:所述对于时间复杂度而言,考虑q个问句,在h个历史问句中逐一匹配,时间复杂度为o(q×h)。
技术总结
本发明提供一种面试场景下的相似问句检索机制,涉及面试场景技术领域。包括先验的知识库的构建和离线的知识库构建,该方法包括以下步骤:S1、标准问题构建;S2、相似问句扩写;S3、离线问句映射;S4、在线问句检索;所述相似问句扩写是基于标准问题构建的扩写,主要包含同一个标准问句的不同问法所述构件数据库通过调用服务接口输入问句query和知识库名称source,本发明将过往面试记录的问句通过一系列清洗和匹配操作,映射到了各标准问句上,从而构建了一个面试问句的知识库。该知识库不仅包含业界通常所说的标准句、相似句,还包含历史面试记录所匹配到的高质量问句。通过这种关联操作,可同时优化匹配准确率问题和耗时问题。
技术研发人员:厉程
受保护的技术使用者:杭州双系科技有限公司
技术研发日:
技术公布日:2024/1/12
- 还没有人留言评论。精彩留言会获得点赞!