一种半结构化文本匹配方法及系统
本发明属于自然语言处理领域,具体涉及一种半结构化文本匹配方法及系统。
背景技术:
1、由于自然语言的歧义性,半结构文本的匹配很容易造成相同含义的文本存在不同的表述。例如,政务系统的系统名称的匹配,这一步是政务数据资源整合的基础性环节。除了匹配对象系统名称外,还有其它可用信息,如系统所属部门。再如,预算系统中项目名称与定额库的定额名称匹配,这个匹配是轨道交通自动计价开发系统的必要环节,除了匹配对象项目名称、定额名称外,还有其他可用信息,如具体参数。
2、例如,政务系统中政务软件名称的匹配,这一步是政务系统数据资源整合的基础性环节。在某地政务系统中,同一个系统在不同部门登记了不同的名称,例如在a部门的短信平台中有“政务大数据平台”,而该系统在b部门登记为“大数据平台共享交换系统”。再如,在预算系统中有项目名称与定额库的定额名称匹配的问题:项目名称为“镀锌钢板(天圆地方)”对应的定额名称为“装配式镀锌薄钢板矩形风管”,“镀锌钢板(天圆地方)”的参项目规格型号为“δ=0.8mm;长边长=450,制作风管”,“装配式镀锌薄钢板矩形风管”的定额规格型号为“320mm”。
技术实现思路
1、本发明的目的在于提出一种半结构化文本匹配方法及系统,以解决现有技术中所存在的一个或多个技术问题,至少提供一种有益的选择或创造条件。
2、本发明针对这种情况,融合使用场景中的有效信息(例如,对于政务系统政务的软件名称的匹配融入了所属部门),从而构建出半结构化文本。在此基础上,将问题形式化为分类问题,提出了多元模型融合了多种信息,从而高效解决问题。本发明同时阐述了多元模型的微调过程,并给出了系统中项目名称与定额库的定额名称匹配的详细实施案例。
3、为了实现上述目的,根据本发明的一方面,提供一种半结构化文本匹配方法,所述方法包括以下步骤:
4、构建半结构化文本;
5、从半结构化文本中获取第一待匹配对象和第二待匹配对象;
6、将第一待匹配对象和第二待匹配对象分别形式化为xu、xv;
7、构建多元模型,将xu、xv输入多元模型获取匹配结果。
8、进一步地,所述半结构化文本包括至少两个的表头或者主题名称。
9、优选地,所述半结构化文本为发票、证件、简历、保险单、采购单据、行业报告或者商务邮件的电子数据中任意一种此外,所述半结构化文本也可以为excel的表格。
10、进一步地,从半结构化文本中获取第一待匹配对象和第二待匹配对象的意义为:从半结构化文本中获取不同的表头或者主题名称分别作为第一待匹配对象和第二待匹配对象。
11、进一步地,将第一待匹配对象和第二待匹配对象分别形式化为xu、xv的方法具体为:
12、设第一待匹配对象和第二待匹配对象分别为xu、xv:
13、其中,xu={xu_1,xu_11,xu_12,...,xu_1m};xv={xv_1,xv_11,xv_12,...,xv_1n};
14、其中xu_1、xv_1为待匹配xu和xv的核心元素;(xu_1、xv_1为第一待匹配对象和第二待匹配对象对应的表头或者主题名称的中的待匹配数据);
15、而xu_1i、xv_1j分别为xu和xv的第i个和第j个相关信息,记为第i个和第j个辅助元素(xu_1i、xv_1j为除了第一待匹配对象和第二待匹配对象之外的表头或者主题名称分别与xu_1、xv_1对应的数据),这些信息用于辅助xu和xv的匹配,其中,i和j分别为xu和xv中相关信息的序号;1<=i<=m,1<=j<=n;m和n分别为xu和xv中相关信息的数量;
16、令f(xu,xv)∈{-1,1};f(xu,xv)的值为1表示xu_1和xv_1能够匹配上,f(xu,xv)的值为-1表示xu_1和xv_1不匹配,f(xu,xv)是xu_1和xv_1的匹配结果。
17、进一步地,所述多元模型为双元模型、三元模型和四元模型中任意一种。
18、第一待匹配对象和第二待匹配对象xu、xv的核心元素分别是xu_1、xv_1,以核心元素为中心,辅助核心元素的辅助元素xu_1i、xv_1j分别为xu和xv的m个和n个辅助信息,1<=i<=m,1<=j<=n;
19、将xu、xv中的每个元素都经由大模型(即多元模型中每一个“元”)处理,得到其对应的嵌入向量;其中,所述本大模型可以为bert模型或者gpt3模型;在获得各元素对应的嵌入向量后,通过余弦及其组合的方法计算对象xu、xv的匹配情况,从而完成核心元素xu_1、xv_1的匹配。
20、其中,核心元素xu_1、xv_1共享一个大模型,处理辅助元素xu_1i、xv_1j大模型的参数独立、不共享;在多元模型中,处理核心元素xu_1、xv_1的大模型共享相同的参数。
21、优选地,所述双元模型为:把一对待匹配的名称作为核心元素xu_1、xv_1输入到共享参数的大模型(如bert模型);xu_1、xv_1经过大模型的处理得到嵌入向量u_1、v_1,其中cosine-sim(u_1,v_1)是计算u_1,v_1的余弦相似度,余弦相似度大于等于0输出1,小于0输出-1;-1表示不匹配、1表示匹配。
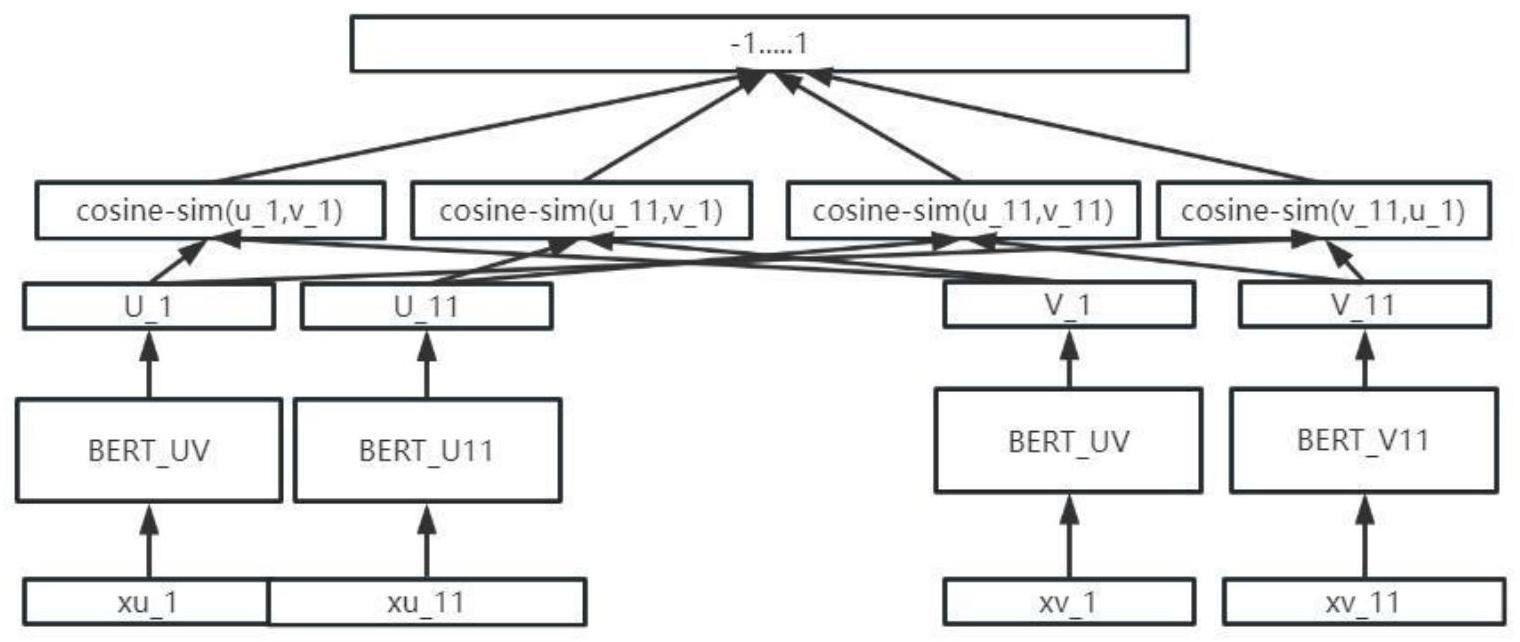
22、优选地,所述三元模型为:
23、将待匹配的两个核心元素xu_1、xv_1、以及其中一个的附属属性描述文本作为辅助元素(即相关信息),分别输入到对应的大模型中,形成各自向量,然后计算各自向量的相似度;
24、例如:将待匹配的两个名称分别定义为核心元素xu_1、xv_1,其中核心元素xu_1包括辅助元素xu_11;以核心元素xu_1为项目名称,以核心元素xv_1为定额名称;为进一步提升性能,使用了项目名称的规格参数xu_11;将核心元素xu_1(项目名称)、xv_1(定额名称)分别输入到共享参数的大模型(如bert_uv,bert_uv是得到向量u_1和v_1的具有相同参数的bert模型)得到嵌入向量u_1、v_1,将xu_1的规格参数xu_11输入到另一个大模型(如bert_u11,bert_u11也是一个bert模型,仅为得到向量u_11)得到u_11。其中,bert_uv和bert_u11均为bert模型,只是输入和输出不同,应用时参数不同。
25、获得嵌入向量u_1、u_11、v_1后,分别计算u_1和v_1、u_11和v_1向量的余弦相似度,以cosine-sim(u_1,v_1)表示计算u_1,v_1的余弦相似度,cosine-sim(u_11,v_1)计算u_11和v_1的余弦相似度,最后取它们余弦相似度的平均值;平均值大于等于0输出1,小于0输出-1。
26、优选地,所述四元模型为:
27、将待匹配的两个名称即核心元素xu_1、xv_1、及其附属属性(xu_11、xv_11),输入到对应的大模型中,形成各自的嵌入向量,然后计算它们的相似度。
28、进一步说明,将待匹配的两个名称分别定义为核心元素为xu_1、xv_1,令核心元素xu_1、xv_1的辅助元素为xu_11、xv_11;以xu_1为项目名称,以xv_1为定额名称,以项目名称规格参数为xu_11,以定额名称的规格参数为xv_11;(在三元模型的基础上,进一步使用了定额名称的规格参数为xv_11)。
29、将核心元素xu_1(项目名称)、xv_1(定额名称)分别输入到共享参数的大模型(如bert_uv)得到嵌入向量u_1、v_1,xu_1的辅助元素xu_11被送到了另一个大模型(如bert_u11)得到嵌入向量u_11,xv_1的辅助元素xv_11被送到了另一个大模型(如bert_v11)得到嵌入向量v_11。
30、四元模型是双元模型和三元模型的一个扩展,四元模型可以接收输入多个半结构文本,形成它们的向量。
31、把项目名称,项目名称规格参数,定额名称及其定额参数分别看成xu_1、xu_11、xv_1、xv_11四个半结构文本分别送进四个bert模型,模型输出的这些文本对应的向量u_1、u_11、v_1、v_11。
32、获得嵌入向量u_1、u_11、v_1、v_11后,在计算u_1和v_1向量的余弦相似度、u_11和v_1向量的余弦相似度基础上在计算u_11和v_1、u_11和v_11,v_11和u_1的余弦相似度,取他们余弦相似度的平均值,其中平均值大于等于0输出1,小于0输出-1。
33、本发明中,核心元素xu_1、xv_1共享一个大模型,处理辅助元素xu_1i、xv_1j大模型的参数独立、不共享。
34、核心元素xu_1、xv_1为待匹配的具有相同或相近语义的两个名称,借鉴信息检索、信息推荐研究成果,采用共享参数的大模型处理。
35、参数的完全独立不共享的做法尽管能互不干扰,但是,由于bert、gpt3等都是大模型,作为初代大模型的bert只有12.7亿个参数,相对现在的大模型参数较少,能够运行在消费级显卡上,即高档pc而非专用服务器,gtp3参数量为1750亿,glam达到了1.2万亿参数,所以,本领域技术人员一般认为:如果让参数完全独立会使参数量大幅的增加,因此尽管模型依然可以运行,但是本领域技术人员并不会使参数完全独立且不共享。
36、现在讨论辅助元素xu_1i、xv_1j是否共享参数。首先考察辅助元素xu_1i。继续以背景技术中所提及的“镀锌钢板”的规格参数“δ=0.8mm;长边长=450,制作风管”为例,这个参数与作为名称的核心元素存在显著不同,如果继续共享参数,容易造成模型微调的时候发生混淆,因此采用独立模型、非共享参数方式。同样,辅助元素“定额规格型号”“320mm”也不能与核心元素xu_1、xv_1共享一个大模型,需要采用独立模型、非共享参数方式。更进一步,探讨处理xu_1、xv_1的辅助参数的大模型是否能共享参数。例如,“镀锌钢板”的规格型号为“δ=0.8mm;长边长=450,制作风管”,与其对应的“定额规格型号”是“320mm”,二者文字、语义差异极大,难以通过相同参数的大模型获取嵌入向量。因此,辅助元素xu_1i、xv_1j通过独立的大模型获取嵌入向量。
37、为进一步避免模型微调的时候发生混淆的问题,本技术需要根据核心元素和辅助元素选择恰当的bert模型进行微调。具体微调过程如下:
38、优选地,对于所述多元模型中的各个核心元素和辅助元素均进行微调算法;
39、对于核心元素的微调算法如下:
40、首先从已经半结构化的对象中获取关于核心元素的多条句子(或短语,以下简称为句子)此处多条指大量指上百万千万,把核心元素xu_1和xv_1嵌入到每条句子中,并把xu_1和xv_1分别mask(遮蔽)掉,送入bert模型,分别得到xu_1的mask的第i个词嵌入向量embeddingi记为u_i和xv_1的mask的第i个词嵌入向量embeddingi记为v_i.最后取u_i和v_i的余弦相似度(1<=i<=batch,batch是一次迭代有多少条句子的意思)。
41、如果余弦相似度大于等于0就输出1,小于0就输出-1,损失函数用指数损失函数。用这样的方式训练一个共享参数的bert模型。
42、其数学公式表达如下:
43、f1(x)=g(cosine-sim(u_i,v_i)) (1);
44、l(f(x),y)=e-yf(x) (2);
45、式(1)的g(cosine-sim(u_i,v_i))表示对于u_i和v_i的余弦相似度,余弦相似度大于等于0输出1,小于0输出-1,f1(x)是核心元素的微调算法调整后的bert模型的匹配结果。
46、式(2)是指数损失函数,y是目标值,y为-1或1。
47、对于辅助元素的微调算法如下:
48、首先从已经半结构化的对象中获取关于辅助元素的多条句子(或短语,以下简称为句子)多条,把同一辅助元素嵌入到每条句子中两个不同的位置处(可以为随机两处),并把每条句子中的辅助元素mask(遮蔽)掉,把带mask的句子送入到bert模型,获取句子中第一个mask的embeddingi为ai,第二个mask的embeddigi为bi(1<=i<=batch),取ai和bi的余弦相似度,其中余弦相似度大于等于0就输出1,小于0就输出-1,损失函数用指数损失函数。用这样的方式训练一个辅助元素的bert模型。其数学公式表达如下:
49、f2(x)=g(cosine-sim(ai,bi)) (3);
50、函数(3)中的g(cosine-sim(ai,bi))表示对于ai和bi的余弦相似度,余弦相似度大于等于0输出1,小于0输出-1,f2(x)是辅助元素的微调算法调整后的bert模型的匹配结果。
51、本发明还提供了一种半结构化文本匹配系统,所述一种半结构化文本匹配系统包括:处理器、存储器及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现所述一种半结构化文本匹配方法中的步骤,所述一种半结构化文本匹配系统可以运行于桌上型计算机、笔记本电脑、掌上电脑及云端数据中心等计算设备中,可运行的系统可包括,但不仅限于,处理器、存储器、服务器集群,所述处理器执行所述计算机程序运行在以下系统的单元中:
52、半结构化文本获取单元,用于构建半结构化文本;
53、匹配对象获取单元,用于从半结构化文本中获取第一待匹配对象和第二待匹配对象;
54、匹配对象形式化单元,用于将第一待匹配对象和第二待匹配对象分别形式化为xu、xv;
55、多元模型匹配单元,用于构建多元模型,将xu、xv输入多元模型获取匹配结果。
56、本发明的有益效果为:
57、本发明提出一种半结构化文本匹配方法以多元模型解决半结构文本匹配问题。(1)根据业务场景(例如对于政务系统政务软件名称的匹配融入所属部门)构建出半结构化文本。(2)将半结构文本匹配问题形式化为分类问题。(3)每一个待匹配的文本及其附属文本都经过“元”的处理,根据待匹配的文本及其附属文本的特定选择共享或不共享参数的大模型(如bert)处理待匹配文本及其附属文本,形成对应的嵌入向量。(4)在此基础上,进行分类。本发明同时阐述了如何微调大模型(如bert)以提高多元模型的召回率。
- 还没有人留言评论。精彩留言会获得点赞!