命名实体的识别方法和识别装置
本技术涉及数据处理,具体而言,涉及一种命名实体的识别方法和识别装置。
背景技术:
1、命名实体识别在特定领域的应用有利于大数据时代大规模知识库的建设。它可以从大量的数据文本中,对文字信息按照预先设置的标签项进行标注,从而能够根据需求,从海量的大数据文本中,识别出所需要的文字。
2、在发明专利“命名实体识别模型训练方法、识别方法及装置”(专利申请号:cn202110797174.5)中提出了一种基于深度学习的命名实体识别方法,该方法的初始神经网络模型由通过结合关键词级别编码和词级别编码对科技论文数据进行向量表示,再将词级别向量和词级别向量引入双向长短期记忆网络,再将词级别向量引入自注意力机制模型,从而实现对科技论文的命名实体识别。
3、现有技术方案中,一般都是如上述提到的发明专利中所介绍的内容一样,基于深度学习的方法,对数据文本进行识别和标注。基于深度学习的识别方法在实践中,具有很高的准确性。但是,该方法在实践运用中,需要大量的标注数据,所以现有的实体命名的识别方法会受到大量人工标注数据的制约,如果需要保证识别实体的准确度,则需要花费大量的人力、物力用于人工标注。
4、综上所述,目前缺乏一种能够减少人工标注量又能够保证识别准确性的命名实体的识别方法和识别装置。
技术实现思路
1、本技术的内容部分用于以简要的形式介绍构思,这些构思将在后面的具体实施方式部分被详细描述。本技术的内容部分并不旨在标识要求保护的技术方案的关键特征或必要特征,也不旨在用于限制所要求的保护的技术方案的范围。
2、作为本技术的第一个方面,为了解决以上背景技术部分提到的技术问题,本技术的一些实施例提供了一种命名实体的识别方法,包括如下步骤:
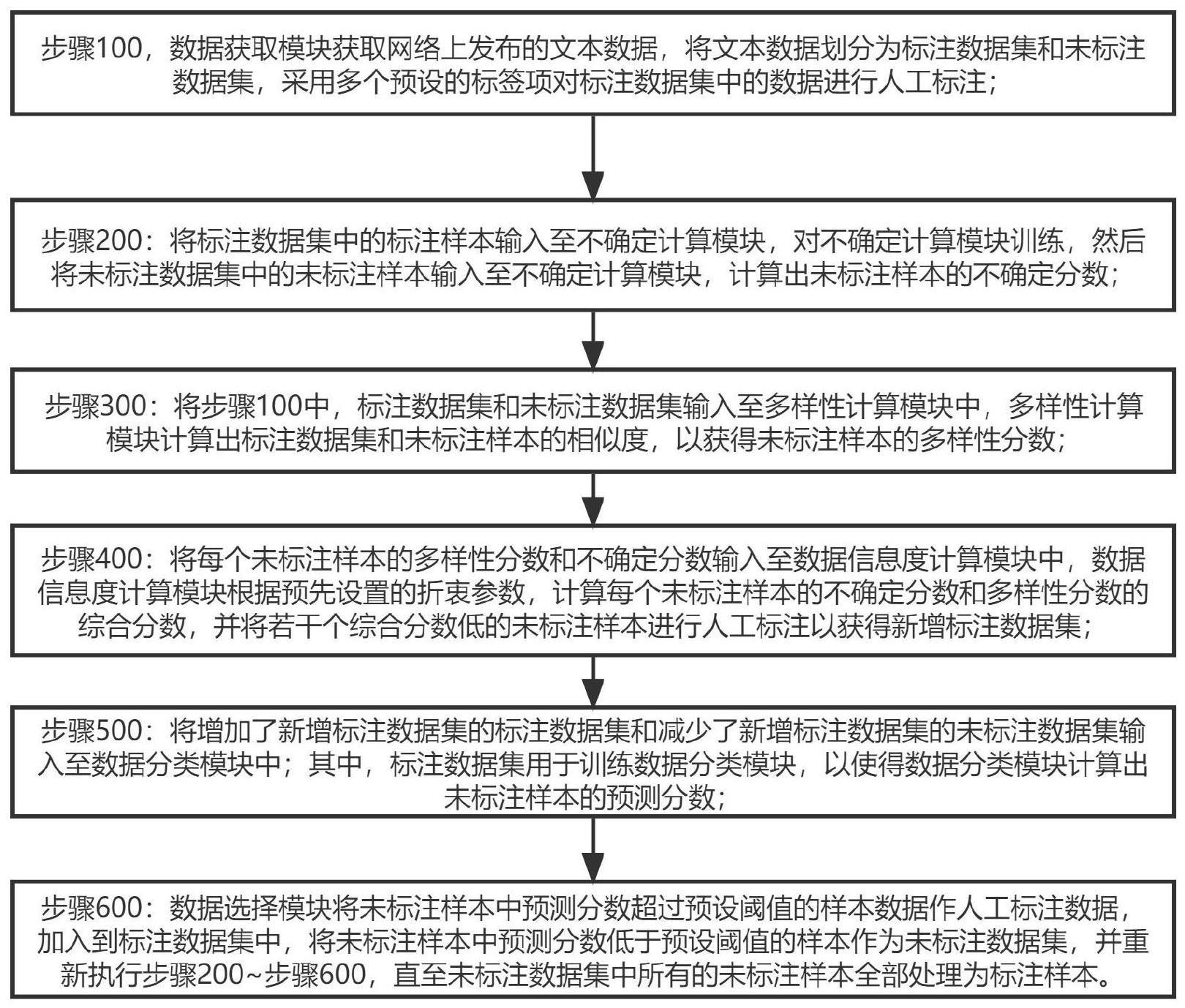
3、步骤100,数据获取模块获取网络上发布的文本数据,将文本数据划分为标注数据集和未标注数据集,采用多个预设的标签项对标注数据集中的数据进行人工标注;
4、步骤200:将标注数据集中的标注样本输入至不确定计算模块,对不确定计算模块训练,然后将未标注数据集中的未标注样本输入至不确定计算模块,计算出未标注样本的不确定分数;
5、步骤300:将步骤100中,标注数据集和未标注数据集输入至多样性计算模块中,多样性计算模块计算出标注数据集和未标注样本的相似度,以获得未标注样本的多样性分数;
6、步骤400:将每个未标注样本的多样性分数和不确定分数输入至数据信息度计算模块中,数据信息度计算模块根据预先设置的折衷参数,计算每个未标注样本的不确定分数和多样性分数的综合分数,并根据综合分数的高低筛选出若干个未标注样本进行人工标注以获得新增标注数据集;
7、步骤500:将增加了新增标注数据集的标注数据集和减少了新增标注数据集的未标注数据集输入至数据分类模块中;其中,标注数据集用于训练数据分类模块,以使得数据分类模块计算出未标注样本的预测分数;
8、步骤600:数据选择模块将未标注样本中预测分数超过预设阈值的样本数据作人工标注数据,加入到标注数据集中,将未标注样本中预测分数低于预设阈值的样本作为未标注数据集,并重新执行步骤200~步骤600,直至未标注数据集中所有的未标注样本全部处理为标注样本。
9、本技术所提供的技术方案,通过将标注样本用于对数据分类模块进行训练,从而使得数据分类样本用于识别未标注样本与对应标签项时,具有很高的准确度;而针对繁复的人工标注,本技术一方面将未标注样本和某标签项超过预测阈值作为标注样本,从而能够随着不断的重复进行,增加标注样本的数量;另一方面,还重复的计算未标注样本和标注样本之间的多样性以及不确定性,从而根据不确定性和多样性的综合分数,将未标注数据集相较于标注数据集中,相似度低、不确定性大的未标注样本进行人工标注,所以能够使得标注样本用于训练数据分类模块时,具有足够广度的样本类型。同时,对于人工标注工作而言,大量繁复的样本标注工作,由预测分数超过阈值的未标注样本所提供,所以人工标注的数据数量将会大幅度减少;人工标注只需要用于足有丰富信息度的样本;如此,申请所提供的技术方案,能够减少人工标注量又能够保证识别准确性。
10、进一步的,步骤200具体包括如下步骤:
11、步骤201:将标注数据集l中的标注样本输入至不确定计算模块的初始分类器中,以对初始分类器进行训练;
12、步骤202:将未标注数据集u中未标注样本输入至不确定计算模块的初始分类器中,计算出未标注样本和对应标签项的不确定分数。
13、先采用标注样本对初始化分类器进行训练,再将未标注样本输入到初始化分类器,所得出的不确定分数与标注样本和未标注样本之间的相似性有关;可以预见,标注样本和未标注样本之间的相似性越高,则未标注样本的不确定分数应当越低,相应的将未标注样本输入到数据分类模块中,得到高于预测分数的概率就越大。而本技术之所以,不通过预测分数的方式来体现标注样本和未标注样本之间的相似性,其原因在于,在数据分类模块中,需要进行大量繁复的运算,准确的计算出未标注样本和对应标签项的预测概率,而在初始分类器中,只会大致的确定出一个不确定分数,所以能够减少计算量,增加数据处理效率。
14、进一步的,
15、步骤201中,对于标注数据集l={l1,l2,…li…ln},其中,第i个标注样本为li;对于每个标注样本li,都是由α个词组成的句子;
16、对于未标注数据集u={u1,u2,…ux…um},其中,都是由α个词组成的句子;对于未标注样本x具有α个词,且每个词都标注有标签,为此未标注样本x=tk1、tk2、…tki…tkα;其中,第i个词为tki;未标注样本x的标签为第i个词tki的标签为
17、步骤202中,计算未标注样本的不确定分数的公式为:
18、其中,是词tki的标签,
19、是未标注样本x对应标签的后验概率。
20、计算出未标注实例的概率,当概率越接近1时,表明该词是对应的标签;相反,当概率接近0时,表明该词不对应该标签;当概率接近0.5时,表明模型无法确定该词是否为对应标签,那么我们就将这样的实例筛选出来对其进行人工标注。我们就可以通过这样的方法提高训练数据集的准确度,从而提升模型的效果。
21、进一步的,步骤300中,针对未标注数据集u中的每个未标注样本和标注数据集中的每个标注样本,选择相同的词窗口,对未标注样本x和样本li进行对比,进而得到未标注样本x的多样性分数。
22、窗口的概念来源于word2vec的动态上下文窗口,通过滑动窗口,比较上下文的相似度从而计算实例之间的相似度。如此,在相同的词窗口下未标注样本和标注样本之间得相似度,能够便于标注样本和未标注样本之间的对比,能够比较在相同的选词范围下,未标注样本和标注样本之间的相似度。
23、进一步的,综合分数的计算公式为:sb=scor吠lcbscor吠sim1-b;其中b=0.1~0.9;
24、步骤400包括如下步骤:
25、步骤401:确定折衷参数b的选值数量m和每个对应选值的大小,其中b=0.1~0.9;
26、步骤402:将未标注数据集u中所有的未标注样本分割为若干子集s1、s2、s3、…si……sn;其中,第i个子集为si;其中,每个子集中的未标注样本为k个;
27、步骤403:计算未标注数据集u中所有未标注样本在选取的折衷参数b的取值下的综合分数,并且将每个折衷参数下,每个子集中综合分数最低的未标注样本x抽取出来以形成新增样本标注数据集cs,k>m。
28、这里抽取未标注样本的方式是在一个子集内,抽取出综合分数最低的未标注样本,而不是预先设置综合分数阈值。如此,能够保证在执行步骤400时,所获得新增样本标注数据集中的样本数量,能够通过调节子集数量进行设置。相较于设置一个固定的阈值,使得综合分数低与预设阈值的未标注样本,进行人工标注的方案,具有更高的准确性,避免设置的阈值太大,而需要进行大量的人工标注,或者设置的阈值太小,而使得人工标注的数量不够;并且,随着不断的执行步骤200~600,标注样本和未标注样本之间的综合分数会越来越理想,所以综合分数整体是一个变化的状态,设置过于准确的阈值,会导致无法适应不断变化的综合分数,而本技术设置的末尾筛选机制,则能够在每次执行时,都获得预期数量的标注样本,在减少标注工作量的情况下,每次都是将最需要进行人工标注的样本出,所以能够不断的增加数据分类模块预测的准确性。
29、进一步的,数据分类模包括bert模型、lstm模型以及crf模型。
30、bert通过自注意力机制以及多头注意力机制,得到输入序列的注意力权重,获取到其中关键词的特征。然后,将bert输出输入到bilstm中,bilstm通过前向和后向传播,每个字符都包含到上下文信息,然后每个字符和各个命名实体标签形成转移矩阵。最后,crf按不同标签排序的路径以及对应的预测分数,选择预测分数最高的序列作为最优路径。
31、进一步的:
32、步骤500中,获取未标注样本和对应标签预测分数的步骤如下:
33、步骤501:将后未标注数据集u’输入到bert模型中,bert模型得到输入的每个未标注样本的注意力权重,然后获取每个未标注样本中,关键词的特征;
34、步骤502:将获得的每个未标注样本的注意力权重和关键词的特征输入到bilstm模型中,获取每个未标注样本中每个词相较于各个标签项的概率矩阵;对于输入至bilstm中的每个未标注样本,会先计算未标注样本x中每个词前向传播的隐藏状态后向传播的隐藏状态以及合并前后传播的隐藏状态ht;
35、步骤503:对于每个未标注样本相较于各个标签项的概率矩阵,crf不同标签排序的路径以及对应的预测分数,选择预测分数最高的序列作为最优路径,并获得最后的标注序列
36、进一步的,
37、步骤503具体包括如下步骤:
38、步骤5031:从步骤502中,获取输入未标注样本x的每个词和对应标签的概率矩阵;
39、步骤5032:并通过概率矩阵,获得每个输入未标注样本x的每个词和对应标签的转移分数矩阵;
40、步骤5032:计算输入未标注样本x相较于对应标签项的标注分数,并通过梯度下降获得最优实体标签序列,进而计算出未标注样本x的标注分数。
41、bert是一种预训练模型,它使用了深度双向转换器(bi-directionaltransformer)来构建整个模型,通过这种方法可以获取全局上下文信息的语言表示。通过字符和bilstm获得的对应标签的概率矩阵,以及标签传播到标签的分数,计算对于输入序列和命名实体标签的任意路径的得分。通过这种方法避免得到错误的标签序列。crf可以通过相邻标签之间的关系获得最优的预测序列,弥补bilstm的不足。
42、进一步的,步骤100具体包括如下步骤:
43、步骤101:数据获取模块获取网络平台上发布的目标文本数据,将目标文本数据采用斯坦福自然语言处理工具进行分词。
44、步骤102:将文本数据集中的部分数据进行人工标注,以获得标注数据集l={l1,l2,…li…ln},剩余未进行人工标注的数据作为未标注数据集u={u1,u2,…ux…um}。
45、采用斯坦福自然语言处理工具将文本数据进行分词之后,数据文本中的所有句子都会被划分为单独的词,如此在进行人工标注时,能够提升人工标注的速率,减少人工在标注时,因为在划分词时的犹豫,而对标注效率的影响。
46、作为本技术的第二个方面,为了解决背景技术中提到的技术问题,提供了一种命名实体的识别装置,包括数据获取模块、不确定计算模块、多样性计算模块、数据信息度计算模块、数据分类模块以及数据选择模块;数据获取模块分别与不确定计算模块和多样性计算模块信号连接;数据信息度计算模块分别与多样化计算模块和不确定计算模块信号连接;数据分类模块分别与数据信息度计算模块和数据选择模块信号连接;数据选择模块分别与不确定计算模块和多样性计算模块信号连接;
47、其中,数据获取模块获取网络上发布的文本数据,将文本数据划分为标注数据集和未标注数据集,采用多个预设的标签项对标注数据集中的数据进行人工标注;
48、不确定计算模块采用标注数据集进行训练,然后计算未标注数据集的未标注样本的不确定分数;
49、多样性计算模块计算出标注数据集的样本和未标注样本的相似度,以获得每个未标注样本的多样性分数;
50、数据信息度计算模块根据预先设置的折衷参数,计算每个未标注样本的不确定分数和多样性分数的综合分数,并将若干个综合分数高的未标注样本进行人工标注以获得新增标注数据集;
51、数据分类模块根据新增标注数据集和标注数据集计算出剩余未标注未标注样本的预测分数;
52、数据选择模块将未标注样本中预测分数超过预设阈值的样本数据作人工标注数据,加入到标注数据集中,将未标注样本中预测分数低于预设阈值的样本作为未标注数据集,并重复执行上述操作,直至未标注数据集中所有的样本全部处理为标注样本。
53、综上所述,本技术通过计算未标注未标注样本的不确定性和多样性,将富含信息度的未标注数据进行人工标注,采用这些标注数据对bert-bilstm-crf模型进行训练,将训练得到的模型用于其余未标注未标注样本的预测,通过重复对模型进行再训练,提高模型的精度,这样的方法大大降低的深度模型对于高质量标注数据的需求,适用于新领域的使用。
- 还没有人留言评论。精彩留言会获得点赞!