基于混合监督多任务学习的域适应人群计数方法及存储介质
本发明涉及计算机视觉领域和人群计数,具体涉及一种基于混合监督多任务学习的域适应人群计数方法及存储介质。
背景技术:
1、在过去几十年里,越来越多的研究团队将目标计数问题作为主要研究方向,在诸如人群、动物、细胞、交通工具等各种领域,开展基于图像或视频的目标数量统计研究。其中,人群计数是一个重要研究课题。特别是近年来国内外疫情发生使得人流聚集,人群计数可以对公共人群场景进行流量管控、异常检测提供关键技术支撑,助力我国公共安全保障事业。
2、基于深度学习的人群计数方法是目前的主流方法,现有技术cn112668532 a公开了一种基于多阶段混合注意网络的人群计数方法,该方法包括:s1、对输入图像进行高斯模糊生成标签密度图并进行数据增强;s2、建模多阶段混合注意网络并初始化权重参数;s3、数据增强后的训练集人群图像输入到s2的网络中进行训练,并将输出密度图与标签密度图作欧几里德损失计算误差,通过误差反向传播更新网络参数直到训练结束并保存最优模型;s4、将测试集人群图像输入到最优模型中输出密度图并进行积分得到估计人数。虽然一定程度上解决了人群计数不准确的问题。但是当前用于人群计数的数据集主要包括shanghaitech part a,shanghaitech part b,ucf-cc,ucf-qnrf等多种数据集,这些数据集之间存在较大的数据差异,通过一个数据集训练好的模型,在应用到另一个不同的数据集上时,人群计数准确性能显著下降,难以泛化,这严重影响了模型的实际应用能力,只能重新建立新的模型。其次,应用于现实场景时,目标场景通常没有太多的人群标注,无法生成标签密度图,从而导致人群计数模型的计数准确性差,因此对目标场景需要较多的研究成本去进行标注。
技术实现思路
1、本发明的目的之一在于提供一种基于混合监督多任务学习的域适应人群计数方法,解决现有技术在不同人群场景下的数据分布差异与目标场景人群标注量少给人群计数模型带来的计数准确性差的问题。
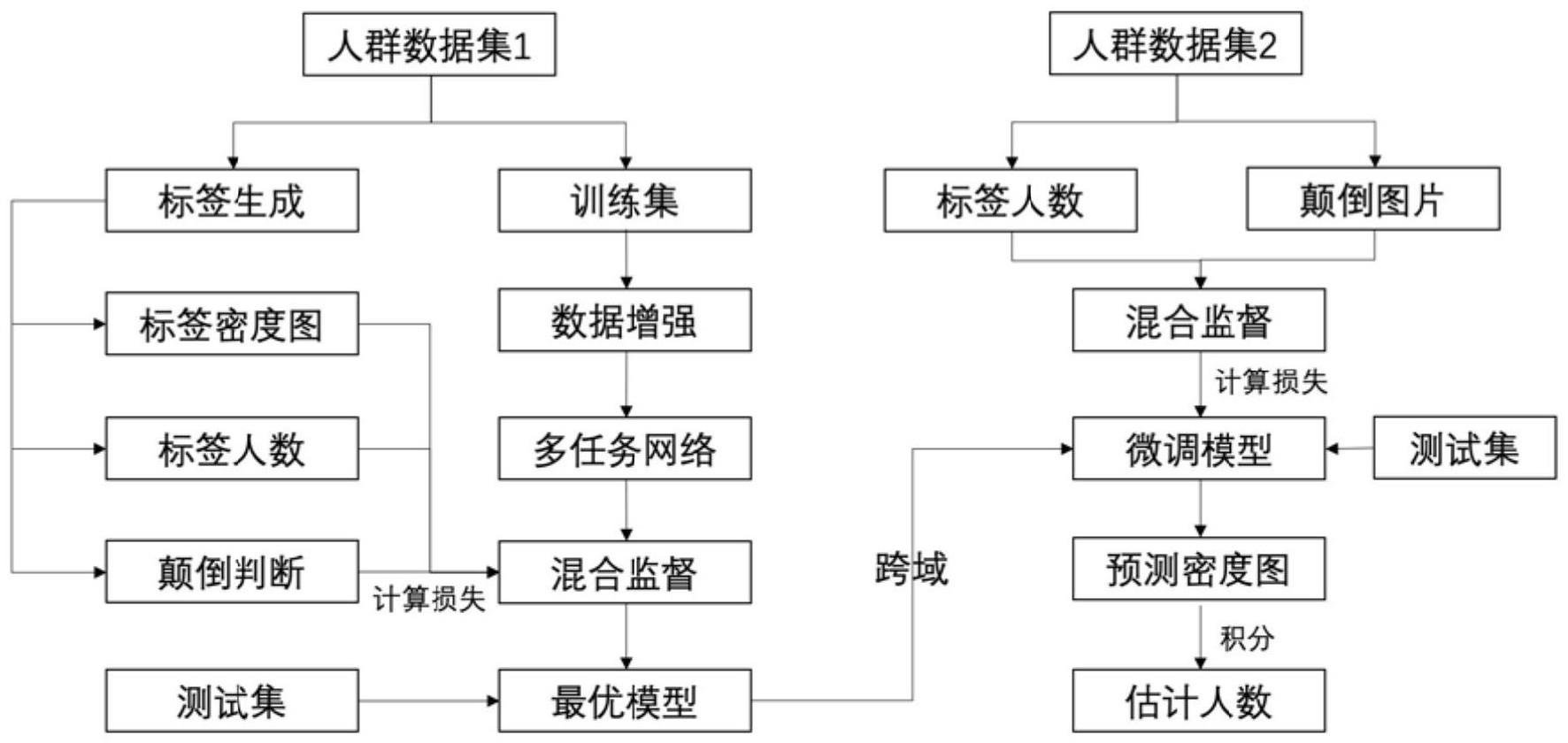
2、为了达到上述目的,提供了一种基于混合监督多任务学习的域适应人群计数方法,包括以下步骤:
3、s1:利用第一人群数据集的标注信息进行标签生成,其中包括标签密度图、标签人数和随机生成图像的颠倒图片的标签颠倒判断值,并对其中的训练集进行数据增强;
4、s2:建模混合监督多任务学习网络;
5、s3:初始化预训练模型及其它网络层参数;
6、s4:输入训练图像,输出估计密度图、估计颠倒判断值和估计人数,并计算估计密度图和标签密度图的损失、估计颠倒判断值与标签颠倒判断值的损失和估计人数与标签人数的损失;
7、s5:选择优化算法最小化损失,并进行误差反向传播更新网络参数;
8、s6:每训练一次,就在第一人群数据集的测试集上通过评价指标验证模型计数性能;
9、s7:迭代s4、s5至设定次数,保存结果并获取适用于第一人群数据集的最优模型;
10、s8:利用第二人群数据集的标注信息进行标签生成,其中包括标签人数和随机生成图像的颠倒图片的标签颠倒判断值,并对其中的训练集进行数据增强;
11、s9:载入适用于第一人群数据集的最优模型;
12、s10:输入第二人群数据集的训练数据,输出估计密度图、估计人数与估计颠倒判断值,并计算估计密度图与估计人数所在分支产生的估计密度图的损失,计算颠倒判断值与标签值的损失和估计人数与真实人数的损失;
13、s11:选择优化算法最小化损失,并进行误差反向传播更新网络参数;
14、s12:每训练一次,就在第二人群数据集的测试集上通过评价指标验证模型计数性能;
15、s13:迭代s10、s11至设定次数,保存结果并获取适用于第二人群数据集的最优模型;
16、s14:将第二人群数据集的测试集图片输入s13的最优模型中,输出预测密度图并进行积分获得估计人数。
17、进一步,所述步骤s1中标签生成具体包括以下子步骤:
18、s101、利用高斯核函数对第一人群数据集的位置级注释进行高斯模糊,生成标签密度图,标签密度图的生成公式如下:
19、
20、其中,n表示图像中的总人头标注数量,假设xi处存在一个人头标注,将人头表示为δ(x-xi);对于给定的人头位置xi,定义为其与k个邻居的人头中心位置的距离,则平均距离定义为表示高斯核标准差参数为σi的高斯卷积,β为常数,将其设置为0.3;
21、s102、根据读取的数据集人头标注,得到标签人数,作为计数级标签;
22、s103、通过随机函数对训练集人群图像进行随机颠倒180度,取[0,1]或[1,0]作为颠倒判断值;
23、所述步骤s1中训练集进行数据增强具体包括以下子步骤:
24、s104、对训练集人群图像进行标准化和归一化,三通道均值和方差分别为(0.485,0.456,0.406)和(0.229,0.224,0.225);
25、s105、对训练人群图像进行固定尺寸的随机裁剪;
26、s106、对训练数据进行概率值为0.9的二值化以增加样本的多样性;
27、s107、对训练数据进行概率值为0.5的随机对比度以增加样本多样性。
28、进一步,所述步骤s2具体为:建模混合监督多任务学习网络,包括特征提取共享模块、颠倒图像判断辅助任务模块、估计密度图生成主任务模块和估计人数生成辅助任务模块,具体包括以下子步骤:
29、s201、采用vgg16-bn模型的前10层作为特征提取共享模块,作为其余模块的共享层;
30、s202、颠倒图像判断辅助任务模块具体为,步骤s201提取了512通道数特征x0经过了全局平均池化层进行降维,将特征图(b×c×h×w)转化为得到二维数据(b×c),此后通过四层全连接层,神经元数量为512,128,64,2,前三层后接relu激活函数,最后通过sigmoid激活层将二维数据映射到[0,1]的范围内,获得图像颠倒与不颠倒的估计颠倒判断值,采用颠倒判断值标签进行自监督学习;
31、s203、估计人数生成辅助任务模块具体为,将s201提取的512通道数特征x0输入到5层普通卷积层中,包括4个核大小为3x3,通道数为512、256、128、64的带bn的卷积层,以及一个核大小为1×1通道数为1的卷积层,激活函数均为relu激活函数,最终得到估计密度图g1,并进行积分得到估计人数,采用计数级标签进行弱监督学习;
32、s204、估计密度图生成主任务模块具体为,将s21提取的512通道数特征x0输入到5层普通卷积层中,包括4个核大小为3x3,通道数为512、256、128、64的带bn的卷积层,以及一个核大小为1×1通道数为1的卷积层,激活函数均为relu激活函数;最终得到估计密度图g2,采用位置级标签进行全监督学习,作为评价指标判断模型的计数性能。
33、进一步,所述步骤s4中,具体包括以下子步骤:
34、s401、将经过步骤s104-s104进行数据增强后的数据样本输入混合监督多任务网络,从后端三个网络分支得到三个输出,分别为估计人数、估计密度图g2和估计颠倒判断值;
35、s402、使用欧几里得损失计算估计密度图g2和对应的标签密度图的损失;
36、s403、使用平滑l1损失计算估计人数与标签人数之间的损失;
37、s404、使用交叉熵损失计算估计颠倒判断值与标签颠倒判断值之间的损失;
38、s405、将三个损失相加实现误差反向传播以更新网络参数。
39、进一步,所述步骤s402中计算误差的损失函数如下:
40、
41、其中,n代表输入网络的图片批处理大小,表示图片的标签密度图,g(xi;θ)表示图片的带参数的预测密度图,n=8;
42、所述步骤s403中计算误差的损失函数如下:
43、
44、其中,x表示标签人数与估计人数之间的差异;
45、所述步骤s404中计算误差的损失函数如下:
46、
47、其中,yi表示标签颠倒判断值,表示估计颠倒判断值;
48、所述步骤s405中实现反向传播以更新网络参数的最终损失函数如下:
49、ls=lmse+αlsmoothl1+βlc
50、其中α取1,β取10。
51、进一步,所述步骤s5中,利用adam优化算法最小化ls损失,对模型进行梯度下降以更新参数。
52、进一步,所述步骤s10具体包括以下步骤:
53、s10-1、向s9中的最优模型输入第二人群数据集的训练数据,输出估计密度图、估计人数与估计颠倒判断值;
54、s10-2、使用金字塔结构相似性损失计算估计密度图g2与估计人数所在分支产生的估计密度图g1损失;
55、s10-3、使用交叉熵损失计算估计颠倒判断值与标签颠倒判断值的损失;
56、s10-4、使用平滑l1损失计算估计人数与标签人数的损失;
57、s10-5、将三个损失相加实现误差反向传播以更新网络参数。
58、进一步,所述步骤s10-2中计算误差的损失函数如下:
59、
60、其中,μf和表示估计密度图g2的局部均值和方差,μy和表示估计密度图g1的局部均值和方差;σfy表示两者的协方差,c1与c2为固定值;
61、为了增强两张估计密度图之间的局部一致性,采用金字塔结构的1-ssim损失:
62、
63、其中,n表示图像批处理大小,s表示尺度等级,pavg表示下采样因子为kj的池化操作,d(xi;θ)表示估计密度图g1,d2(xi;θ)表示估计密度图g2;
64、所述步骤s10-5中实现反向传播以更新网络参数的最终损失函数为:
65、lt=l1-s+αlsmoothl1+βlc
66、其中,lsmoothl1和lc与步骤s4中相同,参数取值也相同。
67、进一步,所述步骤s11中利用adam优化算法最小化lt损失,对模型进行梯度下降以更新参数。
68、本发明的目的之二在于提供一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现所述的基于混合监督多任务学习的域适应人群计数方法。
69、原理及优点:
70、本方案中,先对第一人群数据集的输入图像进行监督标签生成,生成标签密度图、生成标签人数以及随机生成图像的颠倒图片产生颠倒判断值,并进行数据增强。随后建模多混合监督多任务学习网络并初始化权重参数,再将数据增强后的训练集人群图像输入到网络中进行训练,并将多任务网络的三种输出与对应的监督标签进行混合监督,使用三种损失函数计算误差,通过误差反向传播更新网络参数直到训练结束并保存最优模型。对于跨域的新数据集,需要对模型进行微调,生成其标签人数和随机生成图像的颠倒图片产生颠倒判断值作为监督标签。再将数据输入进之前的最优模型中进行训练微调,并将多任务网络的三种输出与上述两种监督标签通过损失函数计算误差,直到训练结束并保存最优模型。最后将测试集输入到最优模型中输出预测密度图并进行积分得到估计人数。
71、与当前人群计数方法相比,本发明提出了基于混合监督多任务学习网络的方案,前端的预训练模型vgg16-bn的前十层用于提出丰富的特征信息并作为多任务特征共享层;同时将该初级特征输入到后端三个多任务分支,包括密度图生成主任务模块(全监督学习),估计人数生成辅助任务模块(弱监督学习)和颠倒图像判断辅助任务模块(自监督学习)。通过图像颠倒,网络可以学习到透视信息;通过弱监督的估计人数生成模块在充分利用数据集标签;通过主任务与两种辅助任务的混合监督,可以实现跨域操作。而且在跨域后,目标数据集(目标数据域)只训练少量的迭代次数,就可以达到优秀的计数效果,达到减少目标数据域的人工标注(无需再次对密度图标注)的同时降低数据域之间的分布差异这一效果。
- 还没有人留言评论。精彩留言会获得点赞!